diff --git a/README.md b/README.md
new file mode 100644
index 0000000..160ccf9
--- /dev/null
+++ b/README.md
@@ -0,0 +1,198 @@
+
+
Grad-SVC based Grad-TTS from HUAWEI Noah's Ark Lab
+
+This project is named as Grad-SVC, or GVC for short. Its core technology is diffusion, but so different from other diffusion based SVC models. Codes are adapted from Grad-TTS and so-vits-svc-5.0. So the features from so-vits-svc-5.0 will be used in this project.
+
+The project will be completed in the coming months ~~~
+
+
+## Setup Environment
+1. Install project dependencies
+
+ ```shell
+ pip install -r requirements.txt
+ ```
+
+2. Download the Timbre Encoder: [Speaker-Encoder by @mueller91](https://drive.google.com/drive/folders/15oeBYf6Qn1edONkVLXe82MzdIi3O_9m3), put `best_model.pth.tar` into `speaker_pretrain/`.
+
+3. Download [hubert_soft model](https://github.com/bshall/hubert/releases/tag/v0.1),put `hubert-soft-0d54a1f4.pt` into `hubert_pretrain/`.
+
+4. Download pretrained [nsf_bigvgan_pretrain_32K.pth](https://github.com/PlayVoice/NSF-BigVGAN/releases/augment), and put it into `bigvgan_pretrain/`.
+
+5. Download pretrain model [gvc.pretrain.pth](), and put it into `grad_pretrain/`.
+ ```shell
+ python gvc_inference.py --config configs/base.yaml --model ./grad_pretrain/gvc.pretrain.pth --spk ./configs/singers/singer0001.npy --wave test.wav
+ ```
+
+## Dataset preparation
+Put the dataset into the `data_raw` directory following the structure below.
+```
+data_raw
+├───speaker0
+│ ├───000001.wav
+│ ├───...
+│ └───000xxx.wav
+└───speaker1
+ ├───000001.wav
+ ├───...
+ └───000xxx.wav
+```
+
+## Data preprocessing
+After preprocessing you will get an output with following structure.
+```
+data_gvc/
+└── waves-16k
+│ └── speaker0
+│ │ ├── 000001.wav
+│ │ └── 000xxx.wav
+│ └── speaker1
+│ ├── 000001.wav
+│ └── 000xxx.wav
+└── waves-32k
+│ └── speaker0
+│ │ ├── 000001.wav
+│ │ └── 000xxx.wav
+│ └── speaker1
+│ ├── 000001.wav
+│ └── 000xxx.wav
+└── mel
+│ └── speaker0
+│ │ ├── 000001.mel.pt
+│ │ └── 000xxx.mel.pt
+│ └── speaker1
+│ ├── 000001.mel.pt
+│ └── 000xxx.mel.pt
+└── pitch
+│ └── speaker0
+│ │ ├── 000001.pit.npy
+│ │ └── 000xxx.pit.npy
+│ └── speaker1
+│ ├── 000001.pit.npy
+│ └── 000xxx.pit.npy
+└── hubert
+│ └── speaker0
+│ │ ├── 000001.vec.npy
+│ │ └── 000xxx.vec.npy
+│ └── speaker1
+│ ├── 000001.vec.npy
+│ └── 000xxx.vec.npy
+└── speaker
+│ └── speaker0
+│ │ ├── 000001.spk.npy
+│ │ └── 000xxx.spk.npy
+│ └── speaker1
+│ ├── 000001.spk.npy
+│ └── 000xxx.spk.npy
+└── singer
+ ├── speaker0.spk.npy
+ └── speaker1.spk.npy
+```
+
+1. Re-sampling
+ - Generate audio with a sampling rate of 16000Hz in `./data_gvc/waves-16k`
+ ```
+ python prepare/preprocess_a.py -w ./data_raw -o ./data_gvc/waves-16k -s 16000
+ ```
+
+ - Generate audio with a sampling rate of 32000Hz in `./data_gvc/waves-32k`
+ ```
+ python prepare/preprocess_a.py -w ./data_raw -o ./data_gvc/waves-32k -s 32000
+ ```
+2. Use 16K audio to extract pitch
+ ```
+ python prepare/preprocess_f0.py -w data_gvc/waves-16k/ -p data_gvc/pitch
+ ```
+3. use 32k audio to extract mel
+ ```
+ python prepare/preprocess_spec.py -w data_gvc/waves-32k/ -s data_gvc/mel
+ ```
+4. Use 16K audio to extract hubert
+ ```
+ python prepare/preprocess_hubert.py -w data_gvc/waves-16k/ -v data_gvc/hubert
+ ```
+5. Use 16k audio to extract timbre code
+ ```
+ python prepare/preprocess_speaker.py data_gvc/waves-16k/ data_gvc/speaker
+ ```
+6. Extract the average value of the timbre code for inference
+ ```
+ python prepare/preprocess_speaker_ave.py data_gvc/speaker/ data_gvc/singer
+ ```
+8. Use 32k audio to generate training index
+ ```
+ python prepare/preprocess_train.py
+ ```
+9. Training file debugging
+ ```
+ python prepare/preprocess_zzz.py
+ ```
+
+## Train
+1. Start training
+ ```
+ python gvc_trainer.py
+ ```
+2. Resume training
+ ```
+ python gvc_trainer.py -p logs/grad_svc/grad_svc_***.pth
+ ```
+3. Log visualization
+ ```
+ tensorboard --logdir logs/
+ ```
+
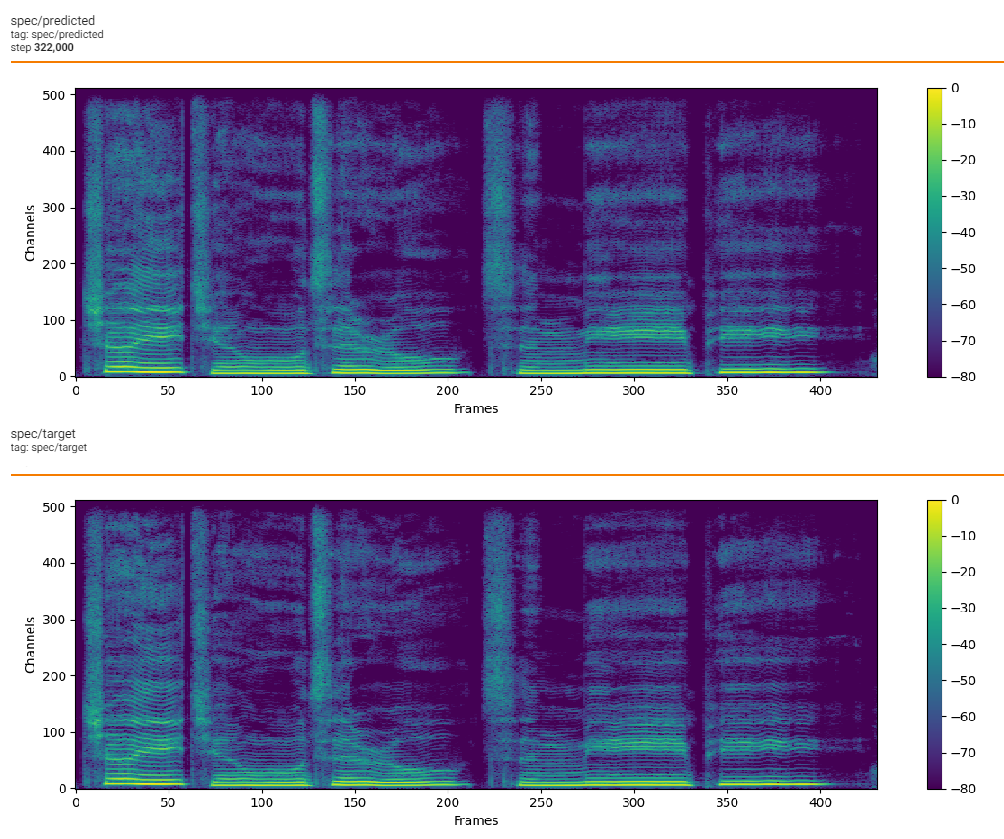
+## Loss
+
+
+
+
+## Inference
+
+1. Export inference model
+ ```
+ python gvc_export.py --checkpoint_path logs/grad_svc/grad_svc_***.pt
+ ```
+
+2. Inference
+ - if there is no need to adjust `f0`, just run the following command.
+ ```
+ python gvc_inference.py --model gvc.pth --spk ./data_gvc/singer/your_singer.spk.npy --wave test.wav --shift 0
+ ```
+ - if `f0` will be adjusted manually, follow the steps:
+
+ 1. use hubert to extract content vector
+ ```
+ python hubert/inference.py -w test.wav -v test.vec.npy
+ ```
+ 2. extract the F0 parameter to the csv text format
+ ```
+ python pitch/inference.py -w test.wav -p test.csv
+ ```
+ 3. final inference
+ ```
+ python gvc_inference.py --model gvc.pth --spk ./data_gvc/singer/your_singer.spk.npy --wave test.wav --vec test.vec.npy --pit test.csv --shift 0
+ ```
+
+3. Convert mel to wave
+ ```
+ python gvc_inference_wave.py --mel gvc_out.mel.pt --pit gvc_tmp.pit.csv
+ ```
+
+## Code sources and references
+
+https://github.com/huawei-noah/Speech-Backbones/blob/main/Grad-TTS
+
+https://github.com/facebookresearch/speech-resynthesis [paper](https://arxiv.org/abs/2104.00355)
+
+https://github.com/jaywalnut310/vits [paper](https://arxiv.org/abs/2106.06103)
+
+https://github.com/NVIDIA/BigVGAN [paper](https://arxiv.org/abs/2206.04658)
+
+https://github.com/mindslab-ai/univnet [paper](https://arxiv.org/abs/2106.07889)
+
+https://github.com/mozilla/TTS
+
+https://github.com/bshall/soft-vc
+
+https://github.com/maxrmorrison/torchcrepe
diff --git a/assets/grad_svc_loss.jpg b/assets/grad_svc_loss.jpg
new file mode 100644
index 0000000..ceea76c
Binary files /dev/null and b/assets/grad_svc_loss.jpg differ
diff --git a/assets/grad_svc_mel.jpg b/assets/grad_svc_mel.jpg
new file mode 100644
index 0000000..476a9a6
Binary files /dev/null and b/assets/grad_svc_mel.jpg differ
diff --git a/bigvgan/LICENSE b/bigvgan/LICENSE
new file mode 100644
index 0000000..328ed6e
--- /dev/null
+++ b/bigvgan/LICENSE
@@ -0,0 +1,21 @@
+MIT License
+
+Copyright (c) 2022 PlayVoice
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
diff --git a/bigvgan/README.md b/bigvgan/README.md
new file mode 100644
index 0000000..7816c1e
--- /dev/null
+++ b/bigvgan/README.md
@@ -0,0 +1,138 @@
+
+
Neural Source-Filter BigVGAN
+ Just For Fun
+
+
+
+
+## Dataset preparation
+
+Put the dataset into the data_raw directory according to the following file structure
+```shell
+data_raw
+├───speaker0
+│ ├───000001.wav
+│ ├───...
+│ └───000xxx.wav
+└───speaker1
+ ├───000001.wav
+ ├───...
+ └───000xxx.wav
+```
+
+## Install dependencies
+
+- 1 software dependency
+
+ > pip install -r requirements.txt
+
+- 2 download [release](https://github.com/PlayVoice/NSF-BigVGAN/releases/tag/debug) model, and test
+
+ > python nsf_bigvgan_inference.py --config configs/nsf_bigvgan.yaml --model nsf_bigvgan_g.pth --wave test.wav
+
+## Data preprocessing
+
+- 1, re-sampling: 32kHz
+
+ > python prepare/preprocess_a.py -w ./data_raw -o ./data_bigvgan/waves-32k
+
+- 3, extract pitch
+
+ > python prepare/preprocess_f0.py -w data_bigvgan/waves-32k/ -p data_bigvgan/pitch
+
+- 4, extract mel: [100, length]
+
+ > python prepare/preprocess_spec.py -w data_bigvgan/waves-32k/ -s data_bigvgan/mel
+
+- 5, generate training index
+
+ > python prepare/preprocess_train.py
+
+```shell
+data_bigvgan/
+│
+└── waves-32k
+│ └── speaker0
+│ │ ├── 000001.wav
+│ │ └── 000xxx.wav
+│ └── speaker1
+│ ├── 000001.wav
+│ └── 000xxx.wav
+└── pitch
+│ └── speaker0
+│ │ ├── 000001.pit.npy
+│ │ └── 000xxx.pit.npy
+│ └── speaker1
+│ ├── 000001.pit.npy
+│ └── 000xxx.pit.npy
+└── mel
+ └── speaker0
+ │ ├── 000001.mel.pt
+ │ └── 000xxx.mel.pt
+ └── speaker1
+ ├── 000001.mel.pt
+ └── 000xxx.mel.pt
+
+```
+
+## Train
+
+- 1, start training
+
+ > python nsf_bigvgan_trainer.py -c configs/nsf_bigvgan.yaml -n nsf_bigvgan
+
+- 2, resume training
+
+ > python nsf_bigvgan_trainer.py -c configs/nsf_bigvgan.yaml -n nsf_bigvgan -p chkpt/nsf_bigvgan/***.pth
+
+- 3, view log
+
+ > tensorboard --logdir logs/
+
+
+## Inference
+
+- 1, export inference model
+
+ > python nsf_bigvgan_export.py --config configs/maxgan.yaml --checkpoint_path chkpt/nsf_bigvgan/***.pt
+
+- 2, extract mel
+
+ > python spec/inference.py -w test.wav -m test.mel.pt
+
+- 3, extract F0
+
+ > python pitch/inference.py -w test.wav -p test.csv
+
+- 4, infer
+
+ > python nsf_bigvgan_inference.py --config configs/nsf_bigvgan.yaml --model nsf_bigvgan_g.pth --wave test.wav
+
+ or
+
+ > python nsf_bigvgan_inference.py --config configs/nsf_bigvgan.yaml --model nsf_bigvgan_g.pth --mel test.mel.pt --pit test.csv
+
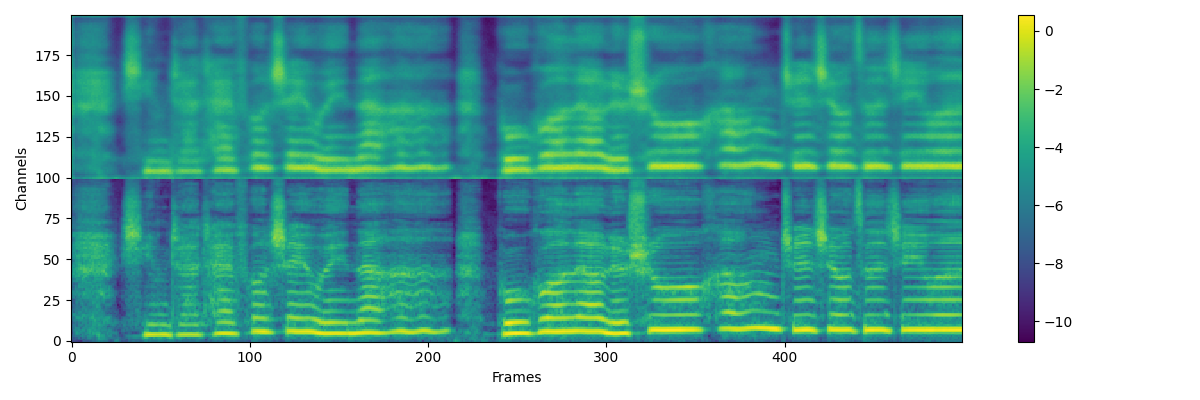
+## Augmentation of mel
+For the over smooth output of acoustic model, we use gaussian blur for mel when train vocoder
+```
+# gaussian blur
+model_b = get_gaussian_kernel(kernel_size=5, sigma=2, channels=1).to(device)
+# mel blur
+mel_b = mel[:, None, :, :]
+mel_b = model_b(mel_b)
+mel_b = torch.squeeze(mel_b, 1)
+mel_r = torch.rand(1).to(device) * 0.5
+mel_b = (1 - mel_r) * mel_b + mel_r * mel
+# generator
+optim_g.zero_grad()
+fake_audio = model_g(mel_b, pit)
+```
+
+
+## Source of code and References
+
+https://github.com/nii-yamagishilab/project-NN-Pytorch-scripts/tree/master/project/01-nsf
+
+https://github.com/mindslab-ai/univnet [[paper]](https://arxiv.org/abs/2106.07889)
+
+https://github.com/NVIDIA/BigVGAN [[paper]](https://arxiv.org/abs/2206.04658)
\ No newline at end of file
diff --git a/bigvgan/configs/nsf_bigvgan.yaml b/bigvgan/configs/nsf_bigvgan.yaml
new file mode 100644
index 0000000..809b129
--- /dev/null
+++ b/bigvgan/configs/nsf_bigvgan.yaml
@@ -0,0 +1,60 @@
+data:
+ train_file: 'files/train.txt'
+ val_file: 'files/valid.txt'
+#############################
+train:
+ num_workers: 4
+ batch_size: 8
+ optimizer: 'adam'
+ seed: 1234
+ adam:
+ lr: 0.0002
+ beta1: 0.8
+ beta2: 0.99
+ mel_lamb: 5
+ stft_lamb: 2.5
+ pretrain: ''
+ lora: False
+#############################
+audio:
+ n_mel_channels: 100
+ segment_length: 12800 # Should be multiple of 320
+ filter_length: 1024
+ hop_length: 320 # WARNING: this can't be changed.
+ win_length: 1024
+ sampling_rate: 32000
+ mel_fmin: 40.0
+ mel_fmax: 16000.0
+#############################
+gen:
+ mel_channels: 100
+ upsample_rates: [5,4,2,2,2,2]
+ upsample_kernel_sizes: [15,8,4,4,4,4]
+ upsample_initial_channel: 320
+ resblock_kernel_sizes: [3,7,11]
+ resblock_dilation_sizes: [[1,3,5], [1,3,5], [1,3,5]]
+#############################
+mpd:
+ periods: [2,3,5,7,11]
+ kernel_size: 5
+ stride: 3
+ use_spectral_norm: False
+ lReLU_slope: 0.2
+#############################
+mrd:
+ resolutions: "[(1024, 120, 600), (2048, 240, 1200), (4096, 480, 2400), (512, 50, 240)]" # (filter_length, hop_length, win_length)
+ use_spectral_norm: False
+ lReLU_slope: 0.2
+#############################
+dist_config:
+ dist_backend: "nccl"
+ dist_url: "tcp://localhost:54321"
+ world_size: 1
+#############################
+log:
+ info_interval: 100
+ eval_interval: 1000
+ save_interval: 10000
+ num_audio: 6
+ pth_dir: 'chkpt'
+ log_dir: 'logs'
diff --git a/bigvgan/model/__init__.py b/bigvgan/model/__init__.py
new file mode 100644
index 0000000..986a0cf
--- /dev/null
+++ b/bigvgan/model/__init__.py
@@ -0,0 +1 @@
+from .alias.act import SnakeAlias
\ No newline at end of file
diff --git a/bigvgan/model/alias/__init__.py b/bigvgan/model/alias/__init__.py
new file mode 100644
index 0000000..a2318b6
--- /dev/null
+++ b/bigvgan/model/alias/__init__.py
@@ -0,0 +1,6 @@
+# Adapted from https://github.com/junjun3518/alias-free-torch under the Apache License 2.0
+# LICENSE is in incl_licenses directory.
+
+from .filter import *
+from .resample import *
+from .act import *
\ No newline at end of file
diff --git a/bigvgan/model/alias/act.py b/bigvgan/model/alias/act.py
new file mode 100644
index 0000000..308344f
--- /dev/null
+++ b/bigvgan/model/alias/act.py
@@ -0,0 +1,129 @@
+# Adapted from https://github.com/junjun3518/alias-free-torch under the Apache License 2.0
+# LICENSE is in incl_licenses directory.
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from torch import sin, pow
+from torch.nn import Parameter
+from .resample import UpSample1d, DownSample1d
+
+
+class Activation1d(nn.Module):
+ def __init__(self,
+ activation,
+ up_ratio: int = 2,
+ down_ratio: int = 2,
+ up_kernel_size: int = 12,
+ down_kernel_size: int = 12):
+ super().__init__()
+ self.up_ratio = up_ratio
+ self.down_ratio = down_ratio
+ self.act = activation
+ self.upsample = UpSample1d(up_ratio, up_kernel_size)
+ self.downsample = DownSample1d(down_ratio, down_kernel_size)
+
+ # x: [B,C,T]
+ def forward(self, x):
+ x = self.upsample(x)
+ x = self.act(x)
+ x = self.downsample(x)
+
+ return x
+
+
+class SnakeBeta(nn.Module):
+ '''
+ A modified Snake function which uses separate parameters for the magnitude of the periodic components
+ Shape:
+ - Input: (B, C, T)
+ - Output: (B, C, T), same shape as the input
+ Parameters:
+ - alpha - trainable parameter that controls frequency
+ - beta - trainable parameter that controls magnitude
+ References:
+ - This activation function is a modified version based on this paper by Liu Ziyin, Tilman Hartwig, Masahito Ueda:
+ https://arxiv.org/abs/2006.08195
+ Examples:
+ >>> a1 = snakebeta(256)
+ >>> x = torch.randn(256)
+ >>> x = a1(x)
+ '''
+
+ def __init__(self, in_features, alpha=1.0, alpha_trainable=True, alpha_logscale=False):
+ '''
+ Initialization.
+ INPUT:
+ - in_features: shape of the input
+ - alpha - trainable parameter that controls frequency
+ - beta - trainable parameter that controls magnitude
+ alpha is initialized to 1 by default, higher values = higher-frequency.
+ beta is initialized to 1 by default, higher values = higher-magnitude.
+ alpha will be trained along with the rest of your model.
+ '''
+ super(SnakeBeta, self).__init__()
+ self.in_features = in_features
+ # initialize alpha
+ self.alpha_logscale = alpha_logscale
+ if self.alpha_logscale: # log scale alphas initialized to zeros
+ self.alpha = Parameter(torch.zeros(in_features) * alpha)
+ self.beta = Parameter(torch.zeros(in_features) * alpha)
+ else: # linear scale alphas initialized to ones
+ self.alpha = Parameter(torch.ones(in_features) * alpha)
+ self.beta = Parameter(torch.ones(in_features) * alpha)
+ self.alpha.requires_grad = alpha_trainable
+ self.beta.requires_grad = alpha_trainable
+ self.no_div_by_zero = 0.000000001
+
+ def forward(self, x):
+ '''
+ Forward pass of the function.
+ Applies the function to the input elementwise.
+ SnakeBeta = x + 1/b * sin^2 (xa)
+ '''
+ alpha = self.alpha.unsqueeze(
+ 0).unsqueeze(-1) # line up with x to [B, C, T]
+ beta = self.beta.unsqueeze(0).unsqueeze(-1)
+ if self.alpha_logscale:
+ alpha = torch.exp(alpha)
+ beta = torch.exp(beta)
+ x = x + (1.0 / (beta + self.no_div_by_zero)) * pow(sin(x * alpha), 2)
+ return x
+
+
+class Mish(nn.Module):
+ """
+ Mish activation function is proposed in "Mish: A Self
+ Regularized Non-Monotonic Neural Activation Function"
+ paper, https://arxiv.org/abs/1908.08681.
+ """
+
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, x):
+ return x * torch.tanh(F.softplus(x))
+
+
+class SnakeAlias(nn.Module):
+ def __init__(self,
+ channels,
+ up_ratio: int = 2,
+ down_ratio: int = 2,
+ up_kernel_size: int = 12,
+ down_kernel_size: int = 12):
+ super().__init__()
+ self.up_ratio = up_ratio
+ self.down_ratio = down_ratio
+ self.act = SnakeBeta(channels, alpha_logscale=True)
+ self.upsample = UpSample1d(up_ratio, up_kernel_size)
+ self.downsample = DownSample1d(down_ratio, down_kernel_size)
+
+ # x: [B,C,T]
+ def forward(self, x):
+ x = self.upsample(x)
+ x = self.act(x)
+ x = self.downsample(x)
+
+ return x
\ No newline at end of file
diff --git a/bigvgan/model/alias/filter.py b/bigvgan/model/alias/filter.py
new file mode 100644
index 0000000..7ad6ea8
--- /dev/null
+++ b/bigvgan/model/alias/filter.py
@@ -0,0 +1,95 @@
+# Adapted from https://github.com/junjun3518/alias-free-torch under the Apache License 2.0
+# LICENSE is in incl_licenses directory.
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import math
+
+if 'sinc' in dir(torch):
+ sinc = torch.sinc
+else:
+ # This code is adopted from adefossez's julius.core.sinc under the MIT License
+ # https://adefossez.github.io/julius/julius/core.html
+ # LICENSE is in incl_licenses directory.
+ def sinc(x: torch.Tensor):
+ """
+ Implementation of sinc, i.e. sin(pi * x) / (pi * x)
+ __Warning__: Different to julius.sinc, the input is multiplied by `pi`!
+ """
+ return torch.where(x == 0,
+ torch.tensor(1., device=x.device, dtype=x.dtype),
+ torch.sin(math.pi * x) / math.pi / x)
+
+
+# This code is adopted from adefossez's julius.lowpass.LowPassFilters under the MIT License
+# https://adefossez.github.io/julius/julius/lowpass.html
+# LICENSE is in incl_licenses directory.
+def kaiser_sinc_filter1d(cutoff, half_width, kernel_size): # return filter [1,1,kernel_size]
+ even = (kernel_size % 2 == 0)
+ half_size = kernel_size // 2
+
+ #For kaiser window
+ delta_f = 4 * half_width
+ A = 2.285 * (half_size - 1) * math.pi * delta_f + 7.95
+ if A > 50.:
+ beta = 0.1102 * (A - 8.7)
+ elif A >= 21.:
+ beta = 0.5842 * (A - 21)**0.4 + 0.07886 * (A - 21.)
+ else:
+ beta = 0.
+ window = torch.kaiser_window(kernel_size, beta=beta, periodic=False)
+
+ # ratio = 0.5/cutoff -> 2 * cutoff = 1 / ratio
+ if even:
+ time = (torch.arange(-half_size, half_size) + 0.5)
+ else:
+ time = torch.arange(kernel_size) - half_size
+ if cutoff == 0:
+ filter_ = torch.zeros_like(time)
+ else:
+ filter_ = 2 * cutoff * window * sinc(2 * cutoff * time)
+ # Normalize filter to have sum = 1, otherwise we will have a small leakage
+ # of the constant component in the input signal.
+ filter_ /= filter_.sum()
+ filter = filter_.view(1, 1, kernel_size)
+
+ return filter
+
+
+class LowPassFilter1d(nn.Module):
+ def __init__(self,
+ cutoff=0.5,
+ half_width=0.6,
+ stride: int = 1,
+ padding: bool = True,
+ padding_mode: str = 'replicate',
+ kernel_size: int = 12):
+ # kernel_size should be even number for stylegan3 setup,
+ # in this implementation, odd number is also possible.
+ super().__init__()
+ if cutoff < -0.:
+ raise ValueError("Minimum cutoff must be larger than zero.")
+ if cutoff > 0.5:
+ raise ValueError("A cutoff above 0.5 does not make sense.")
+ self.kernel_size = kernel_size
+ self.even = (kernel_size % 2 == 0)
+ self.pad_left = kernel_size // 2 - int(self.even)
+ self.pad_right = kernel_size // 2
+ self.stride = stride
+ self.padding = padding
+ self.padding_mode = padding_mode
+ filter = kaiser_sinc_filter1d(cutoff, half_width, kernel_size)
+ self.register_buffer("filter", filter)
+
+ #input [B, C, T]
+ def forward(self, x):
+ _, C, _ = x.shape
+
+ if self.padding:
+ x = F.pad(x, (self.pad_left, self.pad_right),
+ mode=self.padding_mode)
+ out = F.conv1d(x, self.filter.expand(C, -1, -1),
+ stride=self.stride, groups=C)
+
+ return out
\ No newline at end of file
diff --git a/bigvgan/model/alias/resample.py b/bigvgan/model/alias/resample.py
new file mode 100644
index 0000000..750e6c3
--- /dev/null
+++ b/bigvgan/model/alias/resample.py
@@ -0,0 +1,49 @@
+# Adapted from https://github.com/junjun3518/alias-free-torch under the Apache License 2.0
+# LICENSE is in incl_licenses directory.
+
+import torch.nn as nn
+from torch.nn import functional as F
+from .filter import LowPassFilter1d
+from .filter import kaiser_sinc_filter1d
+
+
+class UpSample1d(nn.Module):
+ def __init__(self, ratio=2, kernel_size=None):
+ super().__init__()
+ self.ratio = ratio
+ self.kernel_size = int(6 * ratio // 2) * 2 if kernel_size is None else kernel_size
+ self.stride = ratio
+ self.pad = self.kernel_size // ratio - 1
+ self.pad_left = self.pad * self.stride + (self.kernel_size - self.stride) // 2
+ self.pad_right = self.pad * self.stride + (self.kernel_size - self.stride + 1) // 2
+ filter = kaiser_sinc_filter1d(cutoff=0.5 / ratio,
+ half_width=0.6 / ratio,
+ kernel_size=self.kernel_size)
+ self.register_buffer("filter", filter)
+
+ # x: [B, C, T]
+ def forward(self, x):
+ _, C, _ = x.shape
+
+ x = F.pad(x, (self.pad, self.pad), mode='replicate')
+ x = self.ratio * F.conv_transpose1d(
+ x, self.filter.expand(C, -1, -1), stride=self.stride, groups=C)
+ x = x[..., self.pad_left:-self.pad_right]
+
+ return x
+
+
+class DownSample1d(nn.Module):
+ def __init__(self, ratio=2, kernel_size=None):
+ super().__init__()
+ self.ratio = ratio
+ self.kernel_size = int(6 * ratio // 2) * 2 if kernel_size is None else kernel_size
+ self.lowpass = LowPassFilter1d(cutoff=0.5 / ratio,
+ half_width=0.6 / ratio,
+ stride=ratio,
+ kernel_size=self.kernel_size)
+
+ def forward(self, x):
+ xx = self.lowpass(x)
+
+ return xx
\ No newline at end of file
diff --git a/bigvgan/model/bigv.py b/bigvgan/model/bigv.py
new file mode 100644
index 0000000..029362c
--- /dev/null
+++ b/bigvgan/model/bigv.py
@@ -0,0 +1,64 @@
+import torch
+import torch.nn as nn
+
+from torch.nn import Conv1d
+from torch.nn.utils import weight_norm, remove_weight_norm
+from .alias.act import SnakeAlias
+
+
+def init_weights(m, mean=0.0, std=0.01):
+ classname = m.__class__.__name__
+ if classname.find("Conv") != -1:
+ m.weight.data.normal_(mean, std)
+
+
+def get_padding(kernel_size, dilation=1):
+ return int((kernel_size*dilation - dilation)/2)
+
+
+class AMPBlock(torch.nn.Module):
+ def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
+ super(AMPBlock, self).__init__()
+ self.convs1 = nn.ModuleList([
+ weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
+ padding=get_padding(kernel_size, dilation[0]))),
+ weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
+ padding=get_padding(kernel_size, dilation[1]))),
+ weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
+ padding=get_padding(kernel_size, dilation[2])))
+ ])
+ self.convs1.apply(init_weights)
+
+ self.convs2 = nn.ModuleList([
+ weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
+ padding=get_padding(kernel_size, 1))),
+ weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
+ padding=get_padding(kernel_size, 1))),
+ weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
+ padding=get_padding(kernel_size, 1)))
+ ])
+ self.convs2.apply(init_weights)
+
+ # total number of conv layers
+ self.num_layers = len(self.convs1) + len(self.convs2)
+
+ # periodic nonlinearity with snakebeta function and anti-aliasing
+ self.activations = nn.ModuleList([
+ SnakeAlias(channels) for _ in range(self.num_layers)
+ ])
+
+ def forward(self, x):
+ acts1, acts2 = self.activations[::2], self.activations[1::2]
+ for c1, c2, a1, a2 in zip(self.convs1, self.convs2, acts1, acts2):
+ xt = a1(x)
+ xt = c1(xt)
+ xt = a2(xt)
+ xt = c2(xt)
+ x = xt + x
+ return x
+
+ def remove_weight_norm(self):
+ for l in self.convs1:
+ remove_weight_norm(l)
+ for l in self.convs2:
+ remove_weight_norm(l)
\ No newline at end of file
diff --git a/bigvgan/model/generator.py b/bigvgan/model/generator.py
new file mode 100644
index 0000000..3406c32
--- /dev/null
+++ b/bigvgan/model/generator.py
@@ -0,0 +1,143 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import numpy as np
+
+from torch.nn import Conv1d
+from torch.nn import ConvTranspose1d
+from torch.nn.utils import weight_norm
+from torch.nn.utils import remove_weight_norm
+
+from .nsf import SourceModuleHnNSF
+from .bigv import init_weights, AMPBlock, SnakeAlias
+
+
+class Generator(torch.nn.Module):
+ # this is our main BigVGAN model. Applies anti-aliased periodic activation for resblocks.
+ def __init__(self, hp):
+ super(Generator, self).__init__()
+ self.hp = hp
+ self.num_kernels = len(hp.gen.resblock_kernel_sizes)
+ self.num_upsamples = len(hp.gen.upsample_rates)
+ # pre conv
+ self.conv_pre = nn.utils.weight_norm(
+ Conv1d(hp.gen.mel_channels, hp.gen.upsample_initial_channel, 7, 1, padding=3))
+ # nsf
+ self.f0_upsamp = torch.nn.Upsample(
+ scale_factor=np.prod(hp.gen.upsample_rates))
+ self.m_source = SourceModuleHnNSF(sampling_rate=hp.audio.sampling_rate)
+ self.noise_convs = nn.ModuleList()
+ # transposed conv-based upsamplers. does not apply anti-aliasing
+ self.ups = nn.ModuleList()
+ for i, (u, k) in enumerate(zip(hp.gen.upsample_rates, hp.gen.upsample_kernel_sizes)):
+ # print(f'ups: {i} {k}, {u}, {(k - u) // 2}')
+ # base
+ self.ups.append(
+ weight_norm(
+ ConvTranspose1d(
+ hp.gen.upsample_initial_channel // (2 ** i),
+ hp.gen.upsample_initial_channel // (2 ** (i + 1)),
+ k,
+ u,
+ padding=(k - u) // 2)
+ )
+ )
+ # nsf
+ if i + 1 < len(hp.gen.upsample_rates):
+ stride_f0 = np.prod(hp.gen.upsample_rates[i + 1:])
+ stride_f0 = int(stride_f0)
+ self.noise_convs.append(
+ Conv1d(
+ 1,
+ hp.gen.upsample_initial_channel // (2 ** (i + 1)),
+ kernel_size=stride_f0 * 2,
+ stride=stride_f0,
+ padding=stride_f0 // 2,
+ )
+ )
+ else:
+ self.noise_convs.append(
+ Conv1d(1, hp.gen.upsample_initial_channel //
+ (2 ** (i + 1)), kernel_size=1)
+ )
+
+ # residual blocks using anti-aliased multi-periodicity composition modules (AMP)
+ self.resblocks = nn.ModuleList()
+ for i in range(len(self.ups)):
+ ch = hp.gen.upsample_initial_channel // (2 ** (i + 1))
+ for k, d in zip(hp.gen.resblock_kernel_sizes, hp.gen.resblock_dilation_sizes):
+ self.resblocks.append(AMPBlock(ch, k, d))
+
+ # post conv
+ self.activation_post = SnakeAlias(ch)
+ self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
+ # weight initialization
+ self.ups.apply(init_weights)
+
+ def forward(self, x, f0, train=True):
+ # nsf
+ f0 = f0[:, None]
+ f0 = self.f0_upsamp(f0).transpose(1, 2)
+ har_source = self.m_source(f0)
+ har_source = har_source.transpose(1, 2)
+ # pre conv
+ if train:
+ x = x + torch.randn_like(x) * 0.1 # Perturbation
+ x = self.conv_pre(x)
+ x = x * torch.tanh(F.softplus(x))
+
+ for i in range(self.num_upsamples):
+ # upsampling
+ x = self.ups[i](x)
+ # nsf
+ x_source = self.noise_convs[i](har_source)
+ x = x + x_source
+ # AMP blocks
+ xs = None
+ for j in range(self.num_kernels):
+ if xs is None:
+ xs = self.resblocks[i * self.num_kernels + j](x)
+ else:
+ xs += self.resblocks[i * self.num_kernels + j](x)
+ x = xs / self.num_kernels
+
+ # post conv
+ x = self.activation_post(x)
+ x = self.conv_post(x)
+ x = torch.tanh(x)
+ return x
+
+ def remove_weight_norm(self):
+ for l in self.ups:
+ remove_weight_norm(l)
+ for l in self.resblocks:
+ l.remove_weight_norm()
+ remove_weight_norm(self.conv_pre)
+
+ def eval(self, inference=False):
+ super(Generator, self).eval()
+ # don't remove weight norm while validation in training loop
+ if inference:
+ self.remove_weight_norm()
+
+ def inference(self, mel, f0):
+ MAX_WAV_VALUE = 32768.0
+ audio = self.forward(mel, f0, False)
+ audio = audio.squeeze() # collapse all dimension except time axis
+ audio = MAX_WAV_VALUE * audio
+ audio = audio.clamp(min=-MAX_WAV_VALUE, max=MAX_WAV_VALUE-1)
+ audio = audio.short()
+ return audio
+
+ def pitch2wav(self, f0):
+ MAX_WAV_VALUE = 32768.0
+ # nsf
+ f0 = f0[:, None]
+ f0 = self.f0_upsamp(f0).transpose(1, 2)
+ har_source = self.m_source(f0)
+ audio = har_source.transpose(1, 2)
+ audio = audio.squeeze() # collapse all dimension except time axis
+ audio = MAX_WAV_VALUE * audio
+ audio = audio.clamp(min=-MAX_WAV_VALUE, max=MAX_WAV_VALUE-1)
+ audio = audio.short()
+ return audio
diff --git a/bigvgan/model/nsf.py b/bigvgan/model/nsf.py
new file mode 100644
index 0000000..1e9e6c7
--- /dev/null
+++ b/bigvgan/model/nsf.py
@@ -0,0 +1,394 @@
+import torch
+import numpy as np
+import sys
+import torch.nn.functional as torch_nn_func
+
+
+class PulseGen(torch.nn.Module):
+ """Definition of Pulse train generator
+
+ There are many ways to implement pulse generator.
+ Here, PulseGen is based on SinGen. For a perfect
+ """
+
+ def __init__(self, samp_rate, pulse_amp=0.1, noise_std=0.003, voiced_threshold=0):
+ super(PulseGen, self).__init__()
+ self.pulse_amp = pulse_amp
+ self.sampling_rate = samp_rate
+ self.voiced_threshold = voiced_threshold
+ self.noise_std = noise_std
+ self.l_sinegen = SineGen(
+ self.sampling_rate,
+ harmonic_num=0,
+ sine_amp=self.pulse_amp,
+ noise_std=0,
+ voiced_threshold=self.voiced_threshold,
+ flag_for_pulse=True,
+ )
+
+ def forward(self, f0):
+ """Pulse train generator
+ pulse_train, uv = forward(f0)
+ input F0: tensor(batchsize=1, length, dim=1)
+ f0 for unvoiced steps should be 0
+ output pulse_train: tensor(batchsize=1, length, dim)
+ output uv: tensor(batchsize=1, length, 1)
+
+ Note: self.l_sine doesn't make sure that the initial phase of
+ a voiced segment is np.pi, the first pulse in a voiced segment
+ may not be at the first time step within a voiced segment
+ """
+ with torch.no_grad():
+ sine_wav, uv, noise = self.l_sinegen(f0)
+
+ # sine without additive noise
+ pure_sine = sine_wav - noise
+
+ # step t corresponds to a pulse if
+ # sine[t] > sine[t+1] & sine[t] > sine[t-1]
+ # & sine[t-1], sine[t+1], and sine[t] are voiced
+ # or
+ # sine[t] is voiced, sine[t-1] is unvoiced
+ # we use torch.roll to simulate sine[t+1] and sine[t-1]
+ sine_1 = torch.roll(pure_sine, shifts=1, dims=1)
+ uv_1 = torch.roll(uv, shifts=1, dims=1)
+ uv_1[:, 0, :] = 0
+ sine_2 = torch.roll(pure_sine, shifts=-1, dims=1)
+ uv_2 = torch.roll(uv, shifts=-1, dims=1)
+ uv_2[:, -1, :] = 0
+
+ loc = (pure_sine > sine_1) * (pure_sine > sine_2) \
+ * (uv_1 > 0) * (uv_2 > 0) * (uv > 0) \
+ + (uv_1 < 1) * (uv > 0)
+
+ # pulse train without noise
+ pulse_train = pure_sine * loc
+
+ # additive noise to pulse train
+ # note that noise from sinegen is zero in voiced regions
+ pulse_noise = torch.randn_like(pure_sine) * self.noise_std
+
+ # with additive noise on pulse, and unvoiced regions
+ pulse_train += pulse_noise * loc + pulse_noise * (1 - uv)
+ return pulse_train, sine_wav, uv, pulse_noise
+
+
+class SignalsConv1d(torch.nn.Module):
+ """Filtering input signal with time invariant filter
+ Note: FIRFilter conducted filtering given fixed FIR weight
+ SignalsConv1d convolves two signals
+ Note: this is based on torch.nn.functional.conv1d
+
+ """
+
+ def __init__(self):
+ super(SignalsConv1d, self).__init__()
+
+ def forward(self, signal, system_ir):
+ """output = forward(signal, system_ir)
+
+ signal: (batchsize, length1, dim)
+ system_ir: (length2, dim)
+
+ output: (batchsize, length1, dim)
+ """
+ if signal.shape[-1] != system_ir.shape[-1]:
+ print("Error: SignalsConv1d expects shape:")
+ print("signal (batchsize, length1, dim)")
+ print("system_id (batchsize, length2, dim)")
+ print("But received signal: {:s}".format(str(signal.shape)))
+ print(" system_ir: {:s}".format(str(system_ir.shape)))
+ sys.exit(1)
+ padding_length = system_ir.shape[0] - 1
+ groups = signal.shape[-1]
+
+ # pad signal on the left
+ signal_pad = torch_nn_func.pad(signal.permute(0, 2, 1), (padding_length, 0))
+ # prepare system impulse response as (dim, 1, length2)
+ # also flip the impulse response
+ ir = torch.flip(system_ir.unsqueeze(1).permute(2, 1, 0), dims=[2])
+ # convolute
+ output = torch_nn_func.conv1d(signal_pad, ir, groups=groups)
+ return output.permute(0, 2, 1)
+
+
+class CyclicNoiseGen_v1(torch.nn.Module):
+ """CyclicnoiseGen_v1
+ Cyclic noise with a single parameter of beta.
+ Pytorch v1 implementation assumes f_t is also fixed
+ """
+
+ def __init__(self, samp_rate, noise_std=0.003, voiced_threshold=0):
+ super(CyclicNoiseGen_v1, self).__init__()
+ self.samp_rate = samp_rate
+ self.noise_std = noise_std
+ self.voiced_threshold = voiced_threshold
+
+ self.l_pulse = PulseGen(
+ samp_rate,
+ pulse_amp=1.0,
+ noise_std=noise_std,
+ voiced_threshold=voiced_threshold,
+ )
+ self.l_conv = SignalsConv1d()
+
+ def noise_decay(self, beta, f0mean):
+ """decayed_noise = noise_decay(beta, f0mean)
+ decayed_noise = n[t]exp(-t * f_mean / beta / samp_rate)
+
+ beta: (dim=1) or (batchsize=1, 1, dim=1)
+ f0mean (batchsize=1, 1, dim=1)
+
+ decayed_noise (batchsize=1, length, dim=1)
+ """
+ with torch.no_grad():
+ # exp(-1.0 n / T) < 0.01 => n > -log(0.01)*T = 4.60*T
+ # truncate the noise when decayed by -40 dB
+ length = 4.6 * self.samp_rate / f0mean
+ length = length.int()
+ time_idx = torch.arange(0, length, device=beta.device)
+ time_idx = time_idx.unsqueeze(0).unsqueeze(2)
+ time_idx = time_idx.repeat(beta.shape[0], 1, beta.shape[2])
+
+ noise = torch.randn(time_idx.shape, device=beta.device)
+
+ # due to Pytorch implementation, use f0_mean as the f0 factor
+ decay = torch.exp(-time_idx * f0mean / beta / self.samp_rate)
+ return noise * self.noise_std * decay
+
+ def forward(self, f0s, beta):
+ """Producde cyclic-noise"""
+ # pulse train
+ pulse_train, sine_wav, uv, noise = self.l_pulse(f0s)
+ pure_pulse = pulse_train - noise
+
+ # decayed_noise (length, dim=1)
+ if (uv < 1).all():
+ # all unvoiced
+ cyc_noise = torch.zeros_like(sine_wav)
+ else:
+ f0mean = f0s[uv > 0].mean()
+
+ decayed_noise = self.noise_decay(beta, f0mean)[0, :, :]
+ # convolute
+ cyc_noise = self.l_conv(pure_pulse, decayed_noise)
+
+ # add noise in invoiced segments
+ cyc_noise = cyc_noise + noise * (1.0 - uv)
+ return cyc_noise, pulse_train, sine_wav, uv, noise
+
+
+class SineGen(torch.nn.Module):
+ """Definition of sine generator
+ SineGen(samp_rate, harmonic_num = 0,
+ sine_amp = 0.1, noise_std = 0.003,
+ voiced_threshold = 0,
+ flag_for_pulse=False)
+
+ samp_rate: sampling rate in Hz
+ harmonic_num: number of harmonic overtones (default 0)
+ sine_amp: amplitude of sine-wavefrom (default 0.1)
+ noise_std: std of Gaussian noise (default 0.003)
+ voiced_thoreshold: F0 threshold for U/V classification (default 0)
+ flag_for_pulse: this SinGen is used inside PulseGen (default False)
+
+ Note: when flag_for_pulse is True, the first time step of a voiced
+ segment is always sin(np.pi) or cos(0)
+ """
+
+ def __init__(
+ self,
+ samp_rate,
+ harmonic_num=0,
+ sine_amp=0.1,
+ noise_std=0.003,
+ voiced_threshold=0,
+ flag_for_pulse=False,
+ ):
+ super(SineGen, self).__init__()
+ self.sine_amp = sine_amp
+ self.noise_std = noise_std
+ self.harmonic_num = harmonic_num
+ self.dim = self.harmonic_num + 1
+ self.sampling_rate = samp_rate
+ self.voiced_threshold = voiced_threshold
+ self.flag_for_pulse = flag_for_pulse
+
+ def _f02uv(self, f0):
+ # generate uv signal
+ uv = torch.ones_like(f0)
+ uv = uv * (f0 > self.voiced_threshold)
+ return uv
+
+ def _f02sine(self, f0_values):
+ """f0_values: (batchsize, length, dim)
+ where dim indicates fundamental tone and overtones
+ """
+ # convert to F0 in rad. The interger part n can be ignored
+ # because 2 * np.pi * n doesn't affect phase
+ rad_values = (f0_values / self.sampling_rate) % 1
+
+ # initial phase noise (no noise for fundamental component)
+ rand_ini = torch.rand(
+ f0_values.shape[0], f0_values.shape[2], device=f0_values.device
+ )
+ rand_ini[:, 0] = 0
+ rad_values[:, 0, :] = rad_values[:, 0, :] + rand_ini
+
+ # instantanouse phase sine[t] = sin(2*pi \sum_i=1 ^{t} rad)
+ if not self.flag_for_pulse:
+ # for normal case
+
+ # To prevent torch.cumsum numerical overflow,
+ # it is necessary to add -1 whenever \sum_k=1^n rad_value_k > 1.
+ # Buffer tmp_over_one_idx indicates the time step to add -1.
+ # This will not change F0 of sine because (x-1) * 2*pi = x * 2*pi
+ tmp_over_one = torch.cumsum(rad_values, 1) % 1
+ tmp_over_one_idx = (tmp_over_one[:, 1:, :] - tmp_over_one[:, :-1, :]) < 0
+ cumsum_shift = torch.zeros_like(rad_values)
+ cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0
+
+ sines = torch.sin(
+ torch.cumsum(rad_values + cumsum_shift, dim=1) * 2 * np.pi
+ )
+ else:
+ # If necessary, make sure that the first time step of every
+ # voiced segments is sin(pi) or cos(0)
+ # This is used for pulse-train generation
+
+ # identify the last time step in unvoiced segments
+ uv = self._f02uv(f0_values)
+ uv_1 = torch.roll(uv, shifts=-1, dims=1)
+ uv_1[:, -1, :] = 1
+ u_loc = (uv < 1) * (uv_1 > 0)
+
+ # get the instantanouse phase
+ tmp_cumsum = torch.cumsum(rad_values, dim=1)
+ # different batch needs to be processed differently
+ for idx in range(f0_values.shape[0]):
+ temp_sum = tmp_cumsum[idx, u_loc[idx, :, 0], :]
+ temp_sum[1:, :] = temp_sum[1:, :] - temp_sum[0:-1, :]
+ # stores the accumulation of i.phase within
+ # each voiced segments
+ tmp_cumsum[idx, :, :] = 0
+ tmp_cumsum[idx, u_loc[idx, :, 0], :] = temp_sum
+
+ # rad_values - tmp_cumsum: remove the accumulation of i.phase
+ # within the previous voiced segment.
+ i_phase = torch.cumsum(rad_values - tmp_cumsum, dim=1)
+
+ # get the sines
+ sines = torch.cos(i_phase * 2 * np.pi)
+ return sines
+
+ def forward(self, f0):
+ """sine_tensor, uv = forward(f0)
+ input F0: tensor(batchsize=1, length, dim=1)
+ f0 for unvoiced steps should be 0
+ output sine_tensor: tensor(batchsize=1, length, dim)
+ output uv: tensor(batchsize=1, length, 1)
+ """
+ with torch.no_grad():
+ f0_buf = torch.zeros(f0.shape[0], f0.shape[1], self.dim, device=f0.device)
+ # fundamental component
+ f0_buf[:, :, 0] = f0[:, :, 0]
+ for idx in np.arange(self.harmonic_num):
+ # idx + 2: the (idx+1)-th overtone, (idx+2)-th harmonic
+ f0_buf[:, :, idx + 1] = f0_buf[:, :, 0] * (idx + 2)
+
+ # generate sine waveforms
+ sine_waves = self._f02sine(f0_buf) * self.sine_amp
+
+ # generate uv signal
+ # uv = torch.ones(f0.shape)
+ # uv = uv * (f0 > self.voiced_threshold)
+ uv = self._f02uv(f0)
+
+ # noise: for unvoiced should be similar to sine_amp
+ # std = self.sine_amp/3 -> max value ~ self.sine_amp
+ # . for voiced regions is self.noise_std
+ noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3
+ noise = noise_amp * torch.randn_like(sine_waves)
+
+ # first: set the unvoiced part to 0 by uv
+ # then: additive noise
+ sine_waves = sine_waves * uv + noise
+ return sine_waves
+
+
+class SourceModuleCycNoise_v1(torch.nn.Module):
+ """SourceModuleCycNoise_v1
+ SourceModule(sampling_rate, noise_std=0.003, voiced_threshod=0)
+ sampling_rate: sampling_rate in Hz
+
+ noise_std: std of Gaussian noise (default: 0.003)
+ voiced_threshold: threshold to set U/V given F0 (default: 0)
+
+ cyc, noise, uv = SourceModuleCycNoise_v1(F0_upsampled, beta)
+ F0_upsampled (batchsize, length, 1)
+ beta (1)
+ cyc (batchsize, length, 1)
+ noise (batchsize, length, 1)
+ uv (batchsize, length, 1)
+ """
+
+ def __init__(self, sampling_rate, noise_std=0.003, voiced_threshod=0):
+ super(SourceModuleCycNoise_v1, self).__init__()
+ self.sampling_rate = sampling_rate
+ self.noise_std = noise_std
+ self.l_cyc_gen = CyclicNoiseGen_v1(sampling_rate, noise_std, voiced_threshod)
+
+ def forward(self, f0_upsamped, beta):
+ """
+ cyc, noise, uv = SourceModuleCycNoise_v1(F0, beta)
+ F0_upsampled (batchsize, length, 1)
+ beta (1)
+ cyc (batchsize, length, 1)
+ noise (batchsize, length, 1)
+ uv (batchsize, length, 1)
+ """
+ # source for harmonic branch
+ cyc, pulse, sine, uv, add_noi = self.l_cyc_gen(f0_upsamped, beta)
+
+ # source for noise branch, in the same shape as uv
+ noise = torch.randn_like(uv) * self.noise_std / 3
+ return cyc, noise, uv
+
+
+class SourceModuleHnNSF(torch.nn.Module):
+ def __init__(
+ self,
+ sampling_rate=32000,
+ sine_amp=0.1,
+ add_noise_std=0.003,
+ voiced_threshod=0,
+ ):
+ super(SourceModuleHnNSF, self).__init__()
+ harmonic_num = 10
+ self.sine_amp = sine_amp
+ self.noise_std = add_noise_std
+
+ # to produce sine waveforms
+ self.l_sin_gen = SineGen(
+ sampling_rate, harmonic_num, sine_amp, add_noise_std, voiced_threshod
+ )
+
+ # to merge source harmonics into a single excitation
+ self.l_tanh = torch.nn.Tanh()
+ self.register_buffer('merge_w', torch.FloatTensor([[
+ 0.2942, -0.2243, 0.0033, -0.0056, -0.0020, -0.0046,
+ 0.0221, -0.0083, -0.0241, -0.0036, -0.0581]]))
+ self.register_buffer('merge_b', torch.FloatTensor([0.0008]))
+
+ def forward(self, x):
+ """
+ Sine_source = SourceModuleHnNSF(F0_sampled)
+ F0_sampled (batchsize, length, 1)
+ Sine_source (batchsize, length, 1)
+ """
+ # source for harmonic branch
+ sine_wavs = self.l_sin_gen(x)
+ sine_wavs = torch_nn_func.linear(
+ sine_wavs, self.merge_w) + self.merge_b
+ sine_merge = self.l_tanh(sine_wavs)
+ return sine_merge
diff --git a/bigvgan_pretrain/README.md b/bigvgan_pretrain/README.md
new file mode 100644
index 0000000..0bf434e
--- /dev/null
+++ b/bigvgan_pretrain/README.md
@@ -0,0 +1,5 @@
+Path for:
+
+ nsf_bigvgan_pretrain_32K.pth
+
+ DownLoad link:https://github.com/PlayVoice/NSF-BigVGAN/releases/tag/augment
diff --git a/configs/base.yaml b/configs/base.yaml
new file mode 100644
index 0000000..a7e52cc
--- /dev/null
+++ b/configs/base.yaml
@@ -0,0 +1,40 @@
+train:
+ seed: 37
+ train_files: "files/train.txt"
+ valid_files: "files/valid.txt"
+ log_dir: 'logs/grad_svc'
+ n_epochs: 10000
+ learning_rate: 1e-4
+ batch_size: 16
+ test_size: 4
+ test_step: 1
+ save_step: 1
+ pretrain: ""
+#############################
+data:
+ segment_size: 16000 # WARNING: base on hop_length
+ max_wav_value: 32768.0
+ sampling_rate: 32000
+ filter_length: 1024
+ hop_length: 320
+ win_length: 1024
+ mel_channels: 100
+ mel_fmin: 40.0
+ mel_fmax: 16000.0
+#############################
+grad:
+ n_mels: 100
+ n_vecs: 256
+ n_pits: 256
+ n_spks: 256
+ n_embs: 64
+
+ # encoder parameters
+ n_enc_channels: 192
+ filter_channels: 768
+
+ # decoder parameters
+ dec_dim: 64
+ beta_min: 0.05
+ beta_max: 20.0
+ pe_scale: 1000
diff --git a/grad/LICENSE b/grad/LICENSE
new file mode 100644
index 0000000..e1c1351
--- /dev/null
+++ b/grad/LICENSE
@@ -0,0 +1,19 @@
+Copyright (c) 2021 Huawei Technologies Co., Ltd.
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
\ No newline at end of file
diff --git a/grad/__init__.py b/grad/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/grad/base.py b/grad/base.py
new file mode 100644
index 0000000..7294dcb
--- /dev/null
+++ b/grad/base.py
@@ -0,0 +1,29 @@
+import numpy as np
+import torch
+
+
+class BaseModule(torch.nn.Module):
+ def __init__(self):
+ super(BaseModule, self).__init__()
+
+ @property
+ def nparams(self):
+ """
+ Returns number of trainable parameters of the module.
+ """
+ num_params = 0
+ for name, param in self.named_parameters():
+ if param.requires_grad:
+ num_params += np.prod(param.detach().cpu().numpy().shape)
+ return num_params
+
+
+ def relocate_input(self, x: list):
+ """
+ Relocates provided tensors to the same device set for the module.
+ """
+ device = next(self.parameters()).device
+ for i in range(len(x)):
+ if isinstance(x[i], torch.Tensor) and x[i].device != device:
+ x[i] = x[i].to(device)
+ return x
diff --git a/grad/diffusion.py b/grad/diffusion.py
new file mode 100644
index 0000000..3462999
--- /dev/null
+++ b/grad/diffusion.py
@@ -0,0 +1,273 @@
+import math
+import torch
+from einops import rearrange
+from grad.base import BaseModule
+
+
+class Mish(BaseModule):
+ def forward(self, x):
+ return x * torch.tanh(torch.nn.functional.softplus(x))
+
+
+class Upsample(BaseModule):
+ def __init__(self, dim):
+ super(Upsample, self).__init__()
+ self.conv = torch.nn.ConvTranspose2d(dim, dim, 4, 2, 1)
+
+ def forward(self, x):
+ return self.conv(x)
+
+
+class Downsample(BaseModule):
+ def __init__(self, dim):
+ super(Downsample, self).__init__()
+ self.conv = torch.nn.Conv2d(dim, dim, 3, 2, 1)
+
+ def forward(self, x):
+ return self.conv(x)
+
+
+class Rezero(BaseModule):
+ def __init__(self, fn):
+ super(Rezero, self).__init__()
+ self.fn = fn
+ self.g = torch.nn.Parameter(torch.zeros(1))
+
+ def forward(self, x):
+ return self.fn(x) * self.g
+
+
+class Block(BaseModule):
+ def __init__(self, dim, dim_out, groups=8):
+ super(Block, self).__init__()
+ self.block = torch.nn.Sequential(torch.nn.Conv2d(dim, dim_out, 3,
+ padding=1), torch.nn.GroupNorm(
+ groups, dim_out), Mish())
+
+ def forward(self, x, mask):
+ output = self.block(x * mask)
+ return output * mask
+
+
+class ResnetBlock(BaseModule):
+ def __init__(self, dim, dim_out, time_emb_dim, groups=8):
+ super(ResnetBlock, self).__init__()
+ self.mlp = torch.nn.Sequential(Mish(), torch.nn.Linear(time_emb_dim,
+ dim_out))
+
+ self.block1 = Block(dim, dim_out, groups=groups)
+ self.block2 = Block(dim_out, dim_out, groups=groups)
+ if dim != dim_out:
+ self.res_conv = torch.nn.Conv2d(dim, dim_out, 1)
+ else:
+ self.res_conv = torch.nn.Identity()
+
+ def forward(self, x, mask, time_emb):
+ h = self.block1(x, mask)
+ h += self.mlp(time_emb).unsqueeze(-1).unsqueeze(-1)
+ h = self.block2(h, mask)
+ output = h + self.res_conv(x * mask)
+ return output
+
+
+class LinearAttention(BaseModule):
+ def __init__(self, dim, heads=4, dim_head=32):
+ super(LinearAttention, self).__init__()
+ self.heads = heads
+ hidden_dim = dim_head * heads
+ self.to_qkv = torch.nn.Conv2d(dim, hidden_dim * 3, 1, bias=False)
+ self.to_out = torch.nn.Conv2d(hidden_dim, dim, 1)
+
+ def forward(self, x):
+ b, c, h, w = x.shape
+ qkv = self.to_qkv(x)
+ q, k, v = rearrange(qkv, 'b (qkv heads c) h w -> qkv b heads c (h w)',
+ heads = self.heads, qkv=3)
+ k = k.softmax(dim=-1)
+ context = torch.einsum('bhdn,bhen->bhde', k, v)
+ out = torch.einsum('bhde,bhdn->bhen', context, q)
+ out = rearrange(out, 'b heads c (h w) -> b (heads c) h w',
+ heads=self.heads, h=h, w=w)
+ return self.to_out(out)
+
+
+class Residual(BaseModule):
+ def __init__(self, fn):
+ super(Residual, self).__init__()
+ self.fn = fn
+
+ def forward(self, x, *args, **kwargs):
+ output = self.fn(x, *args, **kwargs) + x
+ return output
+
+
+class SinusoidalPosEmb(BaseModule):
+ def __init__(self, dim):
+ super(SinusoidalPosEmb, self).__init__()
+ self.dim = dim
+
+ def forward(self, x, scale=1000):
+ device = x.device
+ half_dim = self.dim // 2
+ emb = math.log(10000) / (half_dim - 1)
+ emb = torch.exp(torch.arange(half_dim, device=device).float() * -emb)
+ emb = scale * x.unsqueeze(1) * emb.unsqueeze(0)
+ emb = torch.cat((emb.sin(), emb.cos()), dim=-1)
+ return emb
+
+
+class GradLogPEstimator2d(BaseModule):
+ def __init__(self, dim, dim_mults=(1, 2, 4), emb_dim=64, n_mels=100,
+ groups=8, pe_scale=1000):
+ super(GradLogPEstimator2d, self).__init__()
+ self.dim = dim
+ self.dim_mults = dim_mults
+ self.emb_dim = emb_dim
+ self.groups = groups
+ self.pe_scale = pe_scale
+
+ self.spk_mlp = torch.nn.Sequential(torch.nn.Linear(emb_dim, emb_dim * 4), Mish(),
+ torch.nn.Linear(emb_dim * 4, n_mels))
+ self.time_pos_emb = SinusoidalPosEmb(dim)
+ self.mlp = torch.nn.Sequential(torch.nn.Linear(dim, dim * 4), Mish(),
+ torch.nn.Linear(dim * 4, dim))
+
+ dims = [2 + 1, *map(lambda m: dim * m, dim_mults)]
+ in_out = list(zip(dims[:-1], dims[1:]))
+ self.downs = torch.nn.ModuleList([])
+ self.ups = torch.nn.ModuleList([])
+ num_resolutions = len(in_out)
+
+ for ind, (dim_in, dim_out) in enumerate(in_out): # 2 downs
+ is_last = ind >= (num_resolutions - 1)
+ self.downs.append(torch.nn.ModuleList([
+ ResnetBlock(dim_in, dim_out, time_emb_dim=dim),
+ ResnetBlock(dim_out, dim_out, time_emb_dim=dim),
+ Residual(Rezero(LinearAttention(dim_out))),
+ Downsample(dim_out) if not is_last else torch.nn.Identity()]))
+
+ mid_dim = dims[-1]
+ self.mid_block1 = ResnetBlock(mid_dim, mid_dim, time_emb_dim=dim)
+ self.mid_attn = Residual(Rezero(LinearAttention(mid_dim)))
+ self.mid_block2 = ResnetBlock(mid_dim, mid_dim, time_emb_dim=dim)
+
+ for ind, (dim_in, dim_out) in enumerate(reversed(in_out[1:])): # 2 ups
+ self.ups.append(torch.nn.ModuleList([
+ ResnetBlock(dim_out * 2, dim_in, time_emb_dim=dim),
+ ResnetBlock(dim_in, dim_in, time_emb_dim=dim),
+ Residual(Rezero(LinearAttention(dim_in))),
+ Upsample(dim_in)]))
+ self.final_block = Block(dim, dim)
+ self.final_conv = torch.nn.Conv2d(dim, 1, 1)
+
+ def forward(self, spk, x, mask, mu, t):
+ s = self.spk_mlp(spk)
+
+ t = self.time_pos_emb(t, scale=self.pe_scale)
+ t = self.mlp(t)
+
+ s = s.unsqueeze(-1).repeat(1, 1, x.shape[-1])
+ x = torch.stack([mu, x, s], 1)
+ mask = mask.unsqueeze(1)
+
+ hiddens = []
+ masks = [mask]
+ for resnet1, resnet2, attn, downsample in self.downs:
+ mask_down = masks[-1]
+ x = resnet1(x, mask_down, t)
+ x = resnet2(x, mask_down, t)
+ x = attn(x)
+ hiddens.append(x)
+ x = downsample(x * mask_down)
+ masks.append(mask_down[:, :, :, ::2])
+
+ masks = masks[:-1]
+ mask_mid = masks[-1]
+ x = self.mid_block1(x, mask_mid, t)
+ x = self.mid_attn(x)
+ x = self.mid_block2(x, mask_mid, t)
+
+ for resnet1, resnet2, attn, upsample in self.ups:
+ mask_up = masks.pop()
+ x = torch.cat((x, hiddens.pop()), dim=1)
+ x = resnet1(x, mask_up, t)
+ x = resnet2(x, mask_up, t)
+ x = attn(x)
+ x = upsample(x * mask_up)
+
+ x = self.final_block(x, mask)
+ output = self.final_conv(x * mask)
+
+ return (output * mask).squeeze(1)
+
+
+def get_noise(t, beta_init, beta_term, cumulative=False):
+ if cumulative:
+ noise = beta_init*t + 0.5*(beta_term - beta_init)*(t**2)
+ else:
+ noise = beta_init + (beta_term - beta_init)*t
+ return noise
+
+
+class Diffusion(BaseModule):
+ def __init__(self, n_mels, dim, emb_dim=64,
+ beta_min=0.05, beta_max=20, pe_scale=1000):
+ super(Diffusion, self).__init__()
+ self.n_mels = n_mels
+ self.beta_min = beta_min
+ self.beta_max = beta_max
+ self.estimator = GradLogPEstimator2d(dim,
+ n_mels=n_mels,
+ emb_dim=emb_dim,
+ pe_scale=pe_scale)
+
+ def forward_diffusion(self, mel, mask, mu, t):
+ time = t.unsqueeze(-1).unsqueeze(-1)
+ cum_noise = get_noise(time, self.beta_min, self.beta_max, cumulative=True)
+ mean = mel*torch.exp(-0.5*cum_noise) + mu*(1.0 - torch.exp(-0.5*cum_noise))
+ variance = 1.0 - torch.exp(-cum_noise)
+ z = torch.randn(mel.shape, dtype=mel.dtype, device=mel.device,
+ requires_grad=False)
+ xt = mean + z * torch.sqrt(variance)
+ return xt * mask, z * mask
+
+ @torch.no_grad()
+ def reverse_diffusion(self, spk, z, mask, mu, n_timesteps, stoc=False):
+ h = 1.0 / n_timesteps
+ xt = z * mask
+ for i in range(n_timesteps):
+ t = (1.0 - (i + 0.5)*h) * torch.ones(z.shape[0], dtype=z.dtype,
+ device=z.device)
+ time = t.unsqueeze(-1).unsqueeze(-1)
+ noise_t = get_noise(time, self.beta_min, self.beta_max,
+ cumulative=False)
+ if stoc: # adds stochastic term
+ dxt_det = 0.5 * (mu - xt) - self.estimator(spk, xt, mask, mu, t)
+ dxt_det = dxt_det * noise_t * h
+ dxt_stoc = torch.randn(z.shape, dtype=z.dtype, device=z.device,
+ requires_grad=False)
+ dxt_stoc = dxt_stoc * torch.sqrt(noise_t * h)
+ dxt = dxt_det + dxt_stoc
+ else:
+ dxt = 0.5 * (mu - xt - self.estimator(spk, xt, mask, mu, t))
+ dxt = dxt * noise_t * h
+ xt = (xt - dxt) * mask
+ return xt
+
+ @torch.no_grad()
+ def forward(self, spk, z, mask, mu, n_timesteps, stoc=False):
+ return self.reverse_diffusion(spk, z, mask, mu, n_timesteps, stoc)
+
+ def loss_t(self, spk, mel, mask, mu, t):
+ xt, z = self.forward_diffusion(mel, mask, mu, t)
+ time = t.unsqueeze(-1).unsqueeze(-1)
+ cum_noise = get_noise(time, self.beta_min, self.beta_max, cumulative=True)
+ noise_estimation = self.estimator(spk, xt, mask, mu, t)
+ noise_estimation *= torch.sqrt(1.0 - torch.exp(-cum_noise))
+ loss = torch.sum((noise_estimation + z)**2) / (torch.sum(mask)*self.n_mels)
+ return loss, xt
+
+ def compute_loss(self, spk, mel, mask, mu, offset=1e-5):
+ t = torch.rand(mel.shape[0], dtype=mel.dtype, device=mel.device, requires_grad=False)
+ t = torch.clamp(t, offset, 1.0 - offset)
+ return self.loss_t(spk, mel, mask, mu, t)
diff --git a/grad/encoder.py b/grad/encoder.py
new file mode 100644
index 0000000..cb1e118
--- /dev/null
+++ b/grad/encoder.py
@@ -0,0 +1,300 @@
+import math
+import torch
+
+from grad.base import BaseModule
+from grad.utils import sequence_mask, convert_pad_shape
+
+
+class LayerNorm(BaseModule):
+ def __init__(self, channels, eps=1e-4):
+ super(LayerNorm, self).__init__()
+ self.channels = channels
+ self.eps = eps
+
+ self.gamma = torch.nn.Parameter(torch.ones(channels))
+ self.beta = torch.nn.Parameter(torch.zeros(channels))
+
+ def forward(self, x):
+ n_dims = len(x.shape)
+ mean = torch.mean(x, 1, keepdim=True)
+ variance = torch.mean((x - mean)**2, 1, keepdim=True)
+
+ x = (x - mean) * torch.rsqrt(variance + self.eps)
+
+ shape = [1, -1] + [1] * (n_dims - 2)
+ x = x * self.gamma.view(*shape) + self.beta.view(*shape)
+ return x
+
+
+class ConvReluNorm(BaseModule):
+ def __init__(self, in_channels, hidden_channels, out_channels, kernel_size,
+ n_layers, p_dropout):
+ super(ConvReluNorm, self).__init__()
+ self.in_channels = in_channels
+ self.hidden_channels = hidden_channels
+ self.out_channels = out_channels
+ self.kernel_size = kernel_size
+ self.n_layers = n_layers
+ self.p_dropout = p_dropout
+
+ self.conv_pre = torch.nn.Conv1d(in_channels, hidden_channels,
+ kernel_size, padding=kernel_size//2)
+ self.conv_layers = torch.nn.ModuleList()
+ self.norm_layers = torch.nn.ModuleList()
+ self.conv_layers.append(torch.nn.Conv1d(hidden_channels, hidden_channels,
+ kernel_size, padding=kernel_size//2))
+ self.norm_layers.append(LayerNorm(hidden_channels))
+ self.relu_drop = torch.nn.Sequential(torch.nn.ReLU(), torch.nn.Dropout(p_dropout))
+ for _ in range(n_layers - 1):
+ self.conv_layers.append(torch.nn.Conv1d(hidden_channels, hidden_channels,
+ kernel_size, padding=kernel_size//2))
+ self.norm_layers.append(LayerNorm(hidden_channels))
+ self.proj = torch.nn.Conv1d(hidden_channels, out_channels, 1)
+ self.proj.weight.data.zero_()
+ self.proj.bias.data.zero_()
+
+ def forward(self, x, x_mask):
+ x = self.conv_pre(x)
+ x_org = x
+ for i in range(self.n_layers):
+ x = self.conv_layers[i](x * x_mask)
+ x = self.norm_layers[i](x)
+ x = self.relu_drop(x)
+ x = x_org + self.proj(x)
+ return x * x_mask
+
+
+class MultiHeadAttention(BaseModule):
+ def __init__(self, channels, out_channels, n_heads, window_size=None,
+ heads_share=True, p_dropout=0.0, proximal_bias=False,
+ proximal_init=False):
+ super(MultiHeadAttention, self).__init__()
+ assert channels % n_heads == 0
+
+ self.channels = channels
+ self.out_channels = out_channels
+ self.n_heads = n_heads
+ self.window_size = window_size
+ self.heads_share = heads_share
+ self.proximal_bias = proximal_bias
+ self.p_dropout = p_dropout
+ self.attn = None
+
+ self.k_channels = channels // n_heads
+ self.conv_q = torch.nn.Conv1d(channels, channels, 1)
+ self.conv_k = torch.nn.Conv1d(channels, channels, 1)
+ self.conv_v = torch.nn.Conv1d(channels, channels, 1)
+ if window_size is not None:
+ n_heads_rel = 1 if heads_share else n_heads
+ rel_stddev = self.k_channels**-0.5
+ self.emb_rel_k = torch.nn.Parameter(torch.randn(n_heads_rel,
+ window_size * 2 + 1, self.k_channels) * rel_stddev)
+ self.emb_rel_v = torch.nn.Parameter(torch.randn(n_heads_rel,
+ window_size * 2 + 1, self.k_channels) * rel_stddev)
+ self.conv_o = torch.nn.Conv1d(channels, out_channels, 1)
+ self.drop = torch.nn.Dropout(p_dropout)
+
+ torch.nn.init.xavier_uniform_(self.conv_q.weight)
+ torch.nn.init.xavier_uniform_(self.conv_k.weight)
+ if proximal_init:
+ self.conv_k.weight.data.copy_(self.conv_q.weight.data)
+ self.conv_k.bias.data.copy_(self.conv_q.bias.data)
+ torch.nn.init.xavier_uniform_(self.conv_v.weight)
+
+ def forward(self, x, c, attn_mask=None):
+ q = self.conv_q(x)
+ k = self.conv_k(c)
+ v = self.conv_v(c)
+
+ x, self.attn = self.attention(q, k, v, mask=attn_mask)
+
+ x = self.conv_o(x)
+ return x
+
+ def attention(self, query, key, value, mask=None):
+ b, d, t_s, t_t = (*key.size(), query.size(2))
+ query = query.view(b, self.n_heads, self.k_channels, t_t).transpose(2, 3)
+ key = key.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
+ value = value.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
+
+ scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(self.k_channels)
+ if self.window_size is not None:
+ assert t_s == t_t, "Relative attention is only available for self-attention."
+ key_relative_embeddings = self._get_relative_embeddings(self.emb_rel_k, t_s)
+ rel_logits = self._matmul_with_relative_keys(query, key_relative_embeddings)
+ rel_logits = self._relative_position_to_absolute_position(rel_logits)
+ scores_local = rel_logits / math.sqrt(self.k_channels)
+ scores = scores + scores_local
+ if self.proximal_bias:
+ assert t_s == t_t, "Proximal bias is only available for self-attention."
+ scores = scores + self._attention_bias_proximal(t_s).to(device=scores.device,
+ dtype=scores.dtype)
+ if mask is not None:
+ scores = scores.masked_fill(mask == 0, -1e4)
+ p_attn = torch.nn.functional.softmax(scores, dim=-1)
+ p_attn = self.drop(p_attn)
+ output = torch.matmul(p_attn, value)
+ if self.window_size is not None:
+ relative_weights = self._absolute_position_to_relative_position(p_attn)
+ value_relative_embeddings = self._get_relative_embeddings(self.emb_rel_v, t_s)
+ output = output + self._matmul_with_relative_values(relative_weights,
+ value_relative_embeddings)
+ output = output.transpose(2, 3).contiguous().view(b, d, t_t)
+ return output, p_attn
+
+ def _matmul_with_relative_values(self, x, y):
+ ret = torch.matmul(x, y.unsqueeze(0))
+ return ret
+
+ def _matmul_with_relative_keys(self, x, y):
+ ret = torch.matmul(x, y.unsqueeze(0).transpose(-2, -1))
+ return ret
+
+ def _get_relative_embeddings(self, relative_embeddings, length):
+ pad_length = max(length - (self.window_size + 1), 0)
+ slice_start_position = max((self.window_size + 1) - length, 0)
+ slice_end_position = slice_start_position + 2 * length - 1
+ if pad_length > 0:
+ padded_relative_embeddings = torch.nn.functional.pad(
+ relative_embeddings, convert_pad_shape([[0, 0],
+ [pad_length, pad_length], [0, 0]]))
+ else:
+ padded_relative_embeddings = relative_embeddings
+ used_relative_embeddings = padded_relative_embeddings[:,
+ slice_start_position:slice_end_position]
+ return used_relative_embeddings
+
+ def _relative_position_to_absolute_position(self, x):
+ batch, heads, length, _ = x.size()
+ x = torch.nn.functional.pad(x, convert_pad_shape([[0,0],[0,0],[0,0],[0,1]]))
+ x_flat = x.view([batch, heads, length * 2 * length])
+ x_flat = torch.nn.functional.pad(x_flat, convert_pad_shape([[0,0],[0,0],[0,length-1]]))
+ x_final = x_flat.view([batch, heads, length+1, 2*length-1])[:, :, :length, length-1:]
+ return x_final
+
+ def _absolute_position_to_relative_position(self, x):
+ batch, heads, length, _ = x.size()
+ x = torch.nn.functional.pad(x, convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, length-1]]))
+ x_flat = x.view([batch, heads, length**2 + length*(length - 1)])
+ x_flat = torch.nn.functional.pad(x_flat, convert_pad_shape([[0, 0], [0, 0], [length, 0]]))
+ x_final = x_flat.view([batch, heads, length, 2*length])[:,:,:,1:]
+ return x_final
+
+ def _attention_bias_proximal(self, length):
+ r = torch.arange(length, dtype=torch.float32)
+ diff = torch.unsqueeze(r, 0) - torch.unsqueeze(r, 1)
+ return torch.unsqueeze(torch.unsqueeze(-torch.log1p(torch.abs(diff)), 0), 0)
+
+
+class FFN(BaseModule):
+ def __init__(self, in_channels, out_channels, filter_channels, kernel_size,
+ p_dropout=0.0):
+ super(FFN, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.filter_channels = filter_channels
+ self.kernel_size = kernel_size
+ self.p_dropout = p_dropout
+
+ self.conv_1 = torch.nn.Conv1d(in_channels, filter_channels, kernel_size,
+ padding=kernel_size//2)
+ self.conv_2 = torch.nn.Conv1d(filter_channels, out_channels, kernel_size,
+ padding=kernel_size//2)
+ self.drop = torch.nn.Dropout(p_dropout)
+
+ def forward(self, x, x_mask):
+ x = self.conv_1(x * x_mask)
+ x = torch.relu(x)
+ x = self.drop(x)
+ x = self.conv_2(x * x_mask)
+ return x * x_mask
+
+
+class Encoder(BaseModule):
+ def __init__(self, hidden_channels, filter_channels, n_heads, n_layers,
+ kernel_size=1, p_dropout=0.0, window_size=None, **kwargs):
+ super(Encoder, self).__init__()
+ self.hidden_channels = hidden_channels
+ self.filter_channels = filter_channels
+ self.n_heads = n_heads
+ self.n_layers = n_layers
+ self.kernel_size = kernel_size
+ self.p_dropout = p_dropout
+ self.window_size = window_size
+
+ self.drop = torch.nn.Dropout(p_dropout)
+ self.attn_layers = torch.nn.ModuleList()
+ self.norm_layers_1 = torch.nn.ModuleList()
+ self.ffn_layers = torch.nn.ModuleList()
+ self.norm_layers_2 = torch.nn.ModuleList()
+ for _ in range(self.n_layers):
+ self.attn_layers.append(MultiHeadAttention(hidden_channels, hidden_channels,
+ n_heads, window_size=window_size, p_dropout=p_dropout))
+ self.norm_layers_1.append(LayerNorm(hidden_channels))
+ self.ffn_layers.append(FFN(hidden_channels, hidden_channels,
+ filter_channels, kernel_size, p_dropout=p_dropout))
+ self.norm_layers_2.append(LayerNorm(hidden_channels))
+
+ def forward(self, x, x_mask):
+ attn_mask = x_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
+ for i in range(self.n_layers):
+ x = x * x_mask
+ y = self.attn_layers[i](x, x, attn_mask)
+ y = self.drop(y)
+ x = self.norm_layers_1[i](x + y)
+ y = self.ffn_layers[i](x, x_mask)
+ y = self.drop(y)
+ x = self.norm_layers_2[i](x + y)
+ x = x * x_mask
+ return x
+
+
+class TextEncoder(BaseModule):
+ def __init__(self, n_vecs, n_mels, n_embs,
+ n_channels,
+ filter_channels,
+ n_heads=2,
+ n_layers=6,
+ kernel_size=3,
+ p_dropout=0.1,
+ window_size=4):
+ super(TextEncoder, self).__init__()
+ self.n_vecs = n_vecs
+ self.n_mels = n_mels
+ self.n_embs = n_embs
+ self.n_channels = n_channels
+ self.filter_channels = filter_channels
+ self.n_heads = n_heads
+ self.n_layers = n_layers
+ self.kernel_size = kernel_size
+ self.p_dropout = p_dropout
+ self.window_size = window_size
+
+ self.prenet = ConvReluNorm(n_vecs,
+ n_channels,
+ n_channels,
+ kernel_size=5,
+ n_layers=3,
+ p_dropout=0.5)
+
+ self.encoder = Encoder(n_channels + n_embs + n_embs,
+ filter_channels,
+ n_heads,
+ n_layers,
+ kernel_size,
+ p_dropout,
+ window_size=window_size)
+
+ self.proj_m = torch.nn.Conv1d(n_channels + n_embs + n_embs, n_mels, 1)
+
+ def forward(self, x_lengths, x, pit, spk):
+ x_mask = torch.unsqueeze(sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype)
+ # despeaker
+ x = self.prenet(x, x_mask)
+ # pitch + speaker
+ spk = spk.unsqueeze(-1).repeat(1, 1, x.shape[-1])
+ x = torch.cat([x, pit], dim=1)
+ x = torch.cat([x, spk], dim=1)
+ x = self.encoder(x, x_mask)
+ mu = self.proj_m(x) * x_mask
+ return mu, x_mask
diff --git a/grad/model.py b/grad/model.py
new file mode 100644
index 0000000..9ce962e
--- /dev/null
+++ b/grad/model.py
@@ -0,0 +1,125 @@
+import math
+import torch
+
+from grad.base import BaseModule
+from grad.encoder import TextEncoder
+from grad.diffusion import Diffusion
+from grad.utils import f0_to_coarse, rand_ids_segments, slice_segments
+
+
+class GradTTS(BaseModule):
+ def __init__(self, n_mels, n_vecs, n_pits, n_spks, n_embs,
+ n_enc_channels, filter_channels,
+ dec_dim, beta_min, beta_max, pe_scale):
+ super(GradTTS, self).__init__()
+ # common
+ self.n_mels = n_mels
+ self.n_vecs = n_vecs
+ self.n_spks = n_spks
+ self.n_embs = n_embs
+ # encoder
+ self.n_enc_channels = n_enc_channels
+ self.filter_channels = filter_channels
+ # decoder
+ self.dec_dim = dec_dim
+ self.beta_min = beta_min
+ self.beta_max = beta_max
+ self.pe_scale = pe_scale
+
+ self.pit_emb = torch.nn.Embedding(n_pits, n_embs)
+ self.spk_emb = torch.nn.Linear(n_spks, n_embs)
+ self.encoder = TextEncoder(n_vecs,
+ n_mels,
+ n_embs,
+ n_enc_channels,
+ filter_channels)
+ self.decoder = Diffusion(n_mels, dec_dim, n_embs, beta_min, beta_max, pe_scale)
+
+ @torch.no_grad()
+ def forward(self, lengths, vec, pit, spk, n_timesteps, temperature=1.0, stoc=False):
+ """
+ Generates mel-spectrogram from vec. Returns:
+ 1. encoder outputs
+ 2. decoder outputs
+
+ Args:
+ lengths (torch.Tensor): lengths of texts in batch.
+ vec (torch.Tensor): batch of speech vec
+ pit (torch.Tensor): batch of speech pit
+ spk (torch.Tensor): batch of speaker
+
+ n_timesteps (int): number of steps to use for reverse diffusion in decoder.
+ temperature (float, optional): controls variance of terminal distribution.
+ stoc (bool, optional): flag that adds stochastic term to the decoder sampler.
+ Usually, does not provide synthesis improvements.
+ """
+ lengths, vec, pit, spk = self.relocate_input([lengths, vec, pit, spk])
+
+ # Get pitch embedding
+ pit = self.pit_emb(f0_to_coarse(pit))
+
+ # Get speaker embedding
+ spk = self.spk_emb(spk)
+
+ # Transpose
+ vec = torch.transpose(vec, 1, -1)
+ pit = torch.transpose(pit, 1, -1)
+
+ # Get encoder_outputs `mu_x`
+ mu_x, mask_x = self.encoder(lengths, vec, pit, spk)
+ encoder_outputs = mu_x
+
+ # Sample latent representation from terminal distribution N(mu_y, I)
+ z = mu_x + torch.randn_like(mu_x, device=mu_x.device) / temperature
+ # Generate sample by performing reverse dynamics
+ decoder_outputs = self.decoder(spk, z, mask_x, mu_x, n_timesteps, stoc)
+
+ return encoder_outputs, decoder_outputs
+
+ def compute_loss(self, lengths, vec, pit, spk, mel, out_size):
+ """
+ Computes 2 losses:
+ 1. prior loss: loss between mel-spectrogram and encoder outputs.
+ 2. diffusion loss: loss between gaussian noise and its reconstruction by diffusion-based decoder.
+
+ Args:
+ lengths (torch.Tensor): lengths of texts in batch.
+ vec (torch.Tensor): batch of speech vec
+ pit (torch.Tensor): batch of speech pit
+ spk (torch.Tensor): batch of speaker
+ mel (torch.Tensor): batch of corresponding mel-spectrogram
+
+ out_size (int, optional): length (in mel's sampling rate) of segment to cut, on which decoder will be trained.
+ Should be divisible by 2^{num of UNet downsamplings}. Needed to increase batch size.
+ """
+ lengths, vec, pit, spk, mel = self.relocate_input([lengths, vec, pit, spk, mel])
+
+ # Get pitch embedding
+ pit = self.pit_emb(f0_to_coarse(pit))
+
+ # Get speaker embedding
+ spk = self.spk_emb(spk)
+
+ # Transpose
+ vec = torch.transpose(vec, 1, -1)
+ pit = torch.transpose(pit, 1, -1)
+
+ # Get encoder_outputs `mu_x`
+ mu_x, mask_x = self.encoder(lengths, vec, pit, spk)
+
+ # Cut a small segment of mel-spectrogram in order to increase batch size
+ if not isinstance(out_size, type(None)):
+ ids = rand_ids_segments(lengths, out_size)
+ mel = slice_segments(mel, ids, out_size)
+
+ mask_y = slice_segments(mask_x, ids, out_size)
+ mu_y = slice_segments(mu_x, ids, out_size)
+
+ # Compute loss of score-based decoder
+ diff_loss, xt = self.decoder.compute_loss(spk, mel, mask_y, mu_y)
+
+ # Compute loss between aligned encoder outputs and mel-spectrogram
+ prior_loss = torch.sum(0.5 * ((mel - mu_y) ** 2 + math.log(2 * math.pi)) * mask_y)
+ prior_loss = prior_loss / (torch.sum(mask_y) * self.n_mels)
+
+ return prior_loss, diff_loss
diff --git a/grad/utils.py b/grad/utils.py
new file mode 100644
index 0000000..8432525
--- /dev/null
+++ b/grad/utils.py
@@ -0,0 +1,99 @@
+import torch
+import numpy as np
+import inspect
+
+
+def sequence_mask(length, max_length=None):
+ if max_length is None:
+ max_length = length.max()
+ x = torch.arange(int(max_length), dtype=length.dtype, device=length.device)
+ return x.unsqueeze(0) < length.unsqueeze(1)
+
+
+def fix_len_compatibility(length, num_downsamplings_in_unet=2):
+ while True:
+ if length % (2**num_downsamplings_in_unet) == 0:
+ return length
+ length += 1
+
+
+def convert_pad_shape(pad_shape):
+ l = pad_shape[::-1]
+ pad_shape = [item for sublist in l for item in sublist]
+ return pad_shape
+
+
+def generate_path(duration, mask):
+ device = duration.device
+
+ b, t_x, t_y = mask.shape
+ cum_duration = torch.cumsum(duration, 1)
+ path = torch.zeros(b, t_x, t_y, dtype=mask.dtype).to(device=device)
+
+ cum_duration_flat = cum_duration.view(b * t_x)
+ path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype)
+ path = path.view(b, t_x, t_y)
+ path = path - torch.nn.functional.pad(path, convert_pad_shape([[0, 0],
+ [1, 0], [0, 0]]))[:, :-1]
+ path = path * mask
+ return path
+
+
+def duration_loss(logw, logw_, lengths):
+ loss = torch.sum((logw - logw_)**2) / torch.sum(lengths)
+ return loss
+
+
+f0_bin = 256
+f0_max = 1100.0
+f0_min = 50.0
+f0_mel_min = 1127 * np.log(1 + f0_min / 700)
+f0_mel_max = 1127 * np.log(1 + f0_max / 700)
+
+
+def f0_to_coarse(f0):
+ is_torch = isinstance(f0, torch.Tensor)
+ f0_mel = 1127 * (1 + f0 / 700).log() if is_torch else 1127 * \
+ np.log(1 + f0 / 700)
+ f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - f0_mel_min) * \
+ (f0_bin - 2) / (f0_mel_max - f0_mel_min) + 1
+
+ f0_mel[f0_mel <= 1] = 1
+ f0_mel[f0_mel > f0_bin - 1] = f0_bin - 1
+ f0_coarse = (
+ f0_mel + 0.5).long() if is_torch else np.rint(f0_mel).astype(np.int)
+ assert f0_coarse.max() <= 255 and f0_coarse.min(
+ ) >= 1, (f0_coarse.max(), f0_coarse.min())
+ return f0_coarse
+
+
+def rand_ids_segments(lengths, segment_size=200):
+ b = lengths.shape[0]
+ ids_str_max = lengths - segment_size
+ ids_str = (torch.rand([b]).to(device=lengths.device) * ids_str_max).to(dtype=torch.long)
+ return ids_str
+
+
+def slice_segments(x, ids_str, segment_size=200):
+ ret = torch.zeros_like(x[:, :, :segment_size])
+ for i in range(x.size(0)):
+ idx_str = ids_str[i]
+ idx_end = idx_str + segment_size
+ ret[i] = x[i, :, idx_str:idx_end]
+ return ret
+
+
+def retrieve_name(var):
+ for fi in reversed(inspect.stack()):
+ names = [var_name for var_name,
+ var_val in fi.frame.f_locals.items() if var_val is var]
+ if len(names) > 0:
+ return names[0]
+
+
+Debug_Enable = True
+
+
+def debug_shapes(var):
+ if Debug_Enable:
+ print(retrieve_name(var), var.shape)
diff --git a/grad_extend/data.py b/grad_extend/data.py
new file mode 100644
index 0000000..b75625a
--- /dev/null
+++ b/grad_extend/data.py
@@ -0,0 +1,133 @@
+import os
+import random
+import numpy as np
+
+import torch
+
+from grad.utils import fix_len_compatibility
+from grad_extend.utils import parse_filelist
+
+
+class TextMelSpeakerDataset(torch.utils.data.Dataset):
+ def __init__(self, filelist_path):
+ super().__init__()
+ self.filelist = parse_filelist(filelist_path, split_char='|')
+ self._filter()
+ print(f'----------{len(self.filelist)}----------')
+
+ def _filter(self):
+ items_new = []
+ # segment = 200
+ items_min = 250 # 10ms * 250 = 2.5 S
+ items_max = 500 # 10ms * 400 = 5.0 S
+ for mel, vec, pit, spk in self.filelist:
+ if not os.path.isfile(mel):
+ continue
+ if not os.path.isfile(vec):
+ continue
+ if not os.path.isfile(pit):
+ continue
+ if not os.path.isfile(spk):
+ continue
+ temp = np.load(pit)
+ usel = int(temp.shape[0] - 1) # useful length
+ if (usel < items_min):
+ continue
+ if (usel >= items_max):
+ usel = items_max
+ items_new.append([mel, vec, pit, spk, usel])
+ self.filelist = items_new
+
+ def get_triplet(self, item):
+ # print(item)
+ mel = item[0]
+ vec = item[1]
+ pit = item[2]
+ spk = item[3]
+ use = item[4]
+
+ mel = torch.load(mel)
+ vec = np.load(vec)
+ vec = np.repeat(vec, 2, 0) # 320 VEC -> 160 * 2
+ pit = np.load(pit)
+ spk = np.load(spk)
+
+ vec = torch.FloatTensor(vec)
+ pit = torch.FloatTensor(pit)
+ spk = torch.FloatTensor(spk)
+
+ len_vec = vec.size()[0] - 2 # for safe
+ len_pit = pit.size()[0]
+ len_min = min(len_pit, len_vec)
+
+ mel = mel[:, :len_min]
+ vec = vec[:len_min, :]
+ pit = pit[:len_min]
+
+ if len_min > use:
+ max_frame_start = vec.size(0) - use - 1
+ frame_start = random.randint(0, max_frame_start)
+ frame_end = frame_start + use
+
+ mel = mel[:, frame_start:frame_end]
+ vec = vec[frame_start:frame_end, :]
+ pit = pit[frame_start:frame_end]
+ # print(mel.shape)
+ # print(vec.shape)
+ # print(pit.shape)
+ # print(spk.shape)
+ return (mel, vec, pit, spk)
+
+ def __getitem__(self, index):
+ mel, vec, pit, spk = self.get_triplet(self.filelist[index])
+ item = {'mel': mel, 'vec': vec, 'pit': pit, 'spk': spk}
+ return item
+
+ def __len__(self):
+ return len(self.filelist)
+
+ def sample_test_batch(self, size):
+ idx = np.random.choice(range(len(self)), size=size, replace=False)
+ test_batch = []
+ for index in idx:
+ test_batch.append(self.__getitem__(index))
+ return test_batch
+
+
+class TextMelSpeakerBatchCollate(object):
+ # mel: [freq, length]
+ # vec: [len, 256]
+ # pit: [len]
+ # spk: [256]
+ def __call__(self, batch):
+ B = len(batch)
+ mel_max_length = max([item['mel'].shape[-1] for item in batch])
+ max_length = fix_len_compatibility(mel_max_length)
+
+ d_mel = batch[0]['mel'].shape[0]
+ d_vec = batch[0]['vec'].shape[1]
+ d_spk = batch[0]['spk'].shape[0]
+ # print("d_mel", d_mel)
+ # print("d_vec", d_vec)
+ # print("d_spk", d_spk)
+ mel = torch.zeros((B, d_mel, max_length), dtype=torch.float32)
+ vec = torch.zeros((B, max_length, d_vec), dtype=torch.float32)
+ pit = torch.zeros((B, max_length), dtype=torch.float32)
+ spk = torch.zeros((B, d_spk), dtype=torch.float32)
+ lengths = torch.LongTensor(B)
+
+ for i, item in enumerate(batch):
+ y_, x_, p_, s_ = item['mel'], item['vec'], item['pit'], item['spk']
+
+ mel[i, :, :y_.shape[1]] = y_
+ vec[i, :x_.shape[0], :] = x_
+ pit[i, :p_.shape[0]] = p_
+ spk[i] = s_
+
+ lengths[i] = y_.shape[1]
+ # print("lengths", lengths.shape)
+ # print("vec", vec.shape)
+ # print("pit", pit.shape)
+ # print("spk", spk.shape)
+ # print("mel", mel.shape)
+ return {'lengths': lengths, 'vec': vec, 'pit': pit, 'spk': spk, 'mel': mel}
diff --git a/grad_extend/train.py b/grad_extend/train.py
new file mode 100644
index 0000000..32301ed
--- /dev/null
+++ b/grad_extend/train.py
@@ -0,0 +1,163 @@
+import os
+import torch
+import numpy as np
+
+from torch.utils.data import DataLoader
+from torch.utils.tensorboard import SummaryWriter
+
+from tqdm import tqdm
+from grad_extend.data import TextMelSpeakerDataset, TextMelSpeakerBatchCollate
+from grad_extend.utils import plot_tensor, save_plot, load_model
+from grad.utils import fix_len_compatibility
+from grad.model import GradTTS
+
+
+# 200 frames
+out_size = fix_len_compatibility(200)
+
+
+def train(hps, chkpt_path=None):
+
+ print('Initializing logger...')
+ logger = SummaryWriter(log_dir=hps.train.log_dir)
+
+ print('Initializing data loaders...')
+ train_dataset = TextMelSpeakerDataset(hps.train.train_files)
+ batch_collate = TextMelSpeakerBatchCollate()
+ loader = DataLoader(dataset=train_dataset,
+ batch_size=hps.train.batch_size,
+ collate_fn=batch_collate,
+ drop_last=True,
+ num_workers=8,
+ shuffle=True)
+ test_dataset = TextMelSpeakerDataset(hps.train.valid_files)
+
+ print('Initializing model...')
+ model = GradTTS(hps.grad.n_mels, hps.grad.n_vecs, hps.grad.n_pits, hps.grad.n_spks, hps.grad.n_embs,
+ hps.grad.n_enc_channels, hps.grad.filter_channels,
+ hps.grad.dec_dim, hps.grad.beta_min, hps.grad.beta_max, hps.grad.pe_scale).cuda()
+ print('Number of encoder parameters = %.2fm' % (model.encoder.nparams/1e6))
+ print('Number of decoder parameters = %.2fm' % (model.decoder.nparams/1e6))
+
+ # Load Pretrain
+ if os.path.isfile(hps.train.pretrain):
+ logger.info("Start from Grad_SVC pretrain model: %s" % hps.train.pretrain)
+ checkpoint = torch.load(hps.train.pretrain, map_location='cpu')
+ load_model(model, checkpoint['model'])
+
+ print('Initializing optimizer...')
+ optim = torch.optim.Adam(params=model.parameters(), lr=hps.train.learning_rate)
+
+ initepoch = 1
+ iteration = 0
+
+ # Load Continue
+ if chkpt_path is not None:
+ logger.info("Resuming from checkpoint: %s" % chkpt_path)
+ checkpoint = torch.load(chkpt_path, map_location='cpu')
+ model.load_state_dict(checkpoint['model'])
+ optim.load_state_dict(checkpoint['optim'])
+ initepoch = checkpoint['epoch']
+ iteration = checkpoint['steps']
+
+ print('Logging test batch...')
+ test_batch = test_dataset.sample_test_batch(size=hps.train.test_size)
+ for i, item in enumerate(test_batch):
+ mel = item['mel']
+ logger.add_image(f'image_{i}/ground_truth', plot_tensor(mel.squeeze()),
+ global_step=0, dataformats='HWC')
+ save_plot(mel.squeeze(), f'{hps.train.log_dir}/original_{i}.png')
+
+ print('Start training...')
+
+ for epoch in range(initepoch, hps.train.n_epochs + 1):
+ model.eval()
+ print('Synthesis...')
+
+ if epoch % hps.train.test_step == 0:
+ with torch.no_grad():
+ for i, item in enumerate(test_batch):
+ l_vec = item['vec'].shape[0]
+ d_vec = item['vec'].shape[1]
+
+ lengths_fix = fix_len_compatibility(l_vec)
+ lengths = torch.LongTensor([l_vec]).cuda()
+
+ vec = torch.zeros((1, lengths_fix, d_vec), dtype=torch.float32).cuda()
+ pit = torch.zeros((1, lengths_fix), dtype=torch.float32).cuda()
+ spk = item['spk'].to(torch.float32).unsqueeze(0).cuda()
+ vec[0, :l_vec, :] = item['vec']
+ pit[0, :l_vec] = item['pit']
+
+ y_enc, y_dec = model(lengths, vec, pit, spk, n_timesteps=50)
+
+ logger.add_image(f'image_{i}/generated_enc',
+ plot_tensor(y_enc.squeeze().cpu()),
+ global_step=iteration, dataformats='HWC')
+ logger.add_image(f'image_{i}/generated_dec',
+ plot_tensor(y_dec.squeeze().cpu()),
+ global_step=iteration, dataformats='HWC')
+ save_plot(y_enc.squeeze().cpu(),
+ f'{hps.train.log_dir}/generated_enc_{i}.png')
+ save_plot(y_dec.squeeze().cpu(),
+ f'{hps.train.log_dir}/generated_dec_{i}.png')
+
+ model.train()
+
+ prior_losses = []
+ diff_losses = []
+ with tqdm(loader, total=len(train_dataset)//hps.train.batch_size) as progress_bar:
+ for batch in progress_bar:
+ model.zero_grad()
+
+ lengths = batch['lengths'].cuda()
+ vec = batch['vec'].cuda()
+ pit = batch['pit'].cuda()
+ spk = batch['spk'].cuda()
+ mel = batch['mel'].cuda()
+
+ prior_loss, diff_loss = model.compute_loss(lengths, vec, pit, spk,
+ mel, out_size=out_size)
+ loss = sum([prior_loss, diff_loss])
+ loss.backward()
+
+ enc_grad_norm = torch.nn.utils.clip_grad_norm_(model.encoder.parameters(),
+ max_norm=1)
+ dec_grad_norm = torch.nn.utils.clip_grad_norm_(model.decoder.parameters(),
+ max_norm=1)
+ optim.step()
+
+ logger.add_scalar('training/prior_loss', prior_loss,
+ global_step=iteration)
+ logger.add_scalar('training/diffusion_loss', diff_loss,
+ global_step=iteration)
+ logger.add_scalar('training/encoder_grad_norm', enc_grad_norm,
+ global_step=iteration)
+ logger.add_scalar('training/decoder_grad_norm', dec_grad_norm,
+ global_step=iteration)
+
+ msg = f'Epoch: {epoch}, iteration: {iteration} | prior_loss: {prior_loss.item():.3f}, diff_loss: {diff_loss.item():.3f}'
+ progress_bar.set_description(msg)
+
+ prior_losses.append(prior_loss.item())
+ diff_losses.append(diff_loss.item())
+ iteration += 1
+
+ msg = 'Epoch %d: ' % (epoch)
+ msg += '| prior loss = %.3f ' % np.mean(prior_losses)
+ msg += '| diffusion loss = %.3f\n' % np.mean(diff_losses)
+ with open(f'{hps.train.log_dir}/train.log', 'a') as f:
+ f.write(msg)
+
+ if epoch % hps.train.save_step > 0:
+ continue
+
+ save_path = f"{hps.train.log_dir}/grad_svc_{epoch}.pt"
+ torch.save({
+ 'model': model.state_dict(),
+ 'optim': optim.state_dict(),
+ 'epoch': epoch,
+ 'steps': iteration,
+
+ }, save_path)
+ logger.info("Saved checkpoint to: %s" % save_path)
diff --git a/grad_extend/utils.py b/grad_extend/utils.py
new file mode 100644
index 0000000..d7cf538
--- /dev/null
+++ b/grad_extend/utils.py
@@ -0,0 +1,73 @@
+import os
+import glob
+import numpy as np
+import matplotlib.pyplot as plt
+
+import torch
+
+
+def parse_filelist(filelist_path, split_char="|"):
+ with open(filelist_path, encoding='utf-8') as f:
+ filepaths_and_text = [line.strip().split(split_char) for line in f]
+ return filepaths_and_text
+
+
+def load_model(model, saved_state_dict):
+ state_dict = model.state_dict()
+ new_state_dict = {}
+ for k, v in state_dict.items():
+ try:
+ new_state_dict[k] = saved_state_dict[k]
+ except:
+ print("%s is not in the checkpoint" % k)
+ new_state_dict[k] = v
+ model.load_state_dict(new_state_dict)
+ return model
+
+
+def latest_checkpoint_path(dir_path, regex="grad_svc_*.pt"):
+ f_list = glob.glob(os.path.join(dir_path, regex))
+ f_list.sort(key=lambda f: int("".join(filter(str.isdigit, f))))
+ x = f_list[-1]
+ return x
+
+
+def load_checkpoint(logdir, model, num=None):
+ if num is None:
+ model_path = latest_checkpoint_path(logdir, regex="grad_svc_*.pt")
+ else:
+ model_path = os.path.join(logdir, f"grad_svc_{num}.pt")
+ print(f'Loading checkpoint {model_path}...')
+ model_dict = torch.load(model_path, map_location=lambda loc, storage: loc)
+ model.load_state_dict(model_dict, strict=False)
+ return model
+
+
+def save_figure_to_numpy(fig):
+ data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='')
+ data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
+ return data
+
+
+def plot_tensor(tensor):
+ plt.style.use('default')
+ fig, ax = plt.subplots(figsize=(12, 3))
+ im = ax.imshow(tensor, aspect="auto", origin="lower", interpolation='none')
+ plt.colorbar(im, ax=ax)
+ plt.tight_layout()
+ fig.canvas.draw()
+ data = save_figure_to_numpy(fig)
+ plt.close()
+ return data
+
+
+def save_plot(tensor, savepath):
+ plt.style.use('default')
+ fig, ax = plt.subplots(figsize=(12, 3))
+ im = ax.imshow(tensor, aspect="auto", origin="lower", interpolation='none')
+ plt.colorbar(im, ax=ax)
+ plt.tight_layout()
+ fig.canvas.draw()
+ plt.savefig(savepath)
+ plt.close()
+ return
diff --git a/grad_pretrain/README.md b/grad_pretrain/README.md
new file mode 100644
index 0000000..8811790
--- /dev/null
+++ b/grad_pretrain/README.md
@@ -0,0 +1,3 @@
+Path for:
+
+ gvc.pretrain.pth
\ No newline at end of file
diff --git a/gvc_export.py b/gvc_export.py
new file mode 100644
index 0000000..7c58e75
--- /dev/null
+++ b/gvc_export.py
@@ -0,0 +1,48 @@
+import sys,os
+sys.path.append(os.path.dirname(os.path.abspath(__file__)))
+import torch
+import argparse
+from omegaconf import OmegaConf
+from grad.model import GradTTS
+
+
+def load_model(checkpoint_path, model):
+ assert os.path.isfile(checkpoint_path)
+ checkpoint_dict = torch.load(checkpoint_path, map_location="cpu")
+ saved_state_dict = checkpoint_dict["model"]
+
+ state_dict = model.state_dict()
+ new_state_dict = {}
+ for k, v in state_dict.items():
+ try:
+ new_state_dict[k] = saved_state_dict[k]
+ except:
+ print("%s is not in the checkpoint" % k)
+ new_state_dict[k] = v
+ model.load_state_dict(new_state_dict)
+
+
+def main(args):
+ hps = OmegaConf.load(args.config)
+
+ print('Initializing Grad-TTS...')
+ model = GradTTS(hps.grad.n_mels, hps.grad.n_vecs, hps.grad.n_pits, hps.grad.n_spks, hps.grad.n_embs,
+ hps.grad.n_enc_channels, hps.grad.filter_channels,
+ hps.grad.dec_dim, hps.grad.beta_min, hps.grad.beta_max, hps.grad.pe_scale)
+ print('Number of encoder parameters = %.2fm' % (model.encoder.nparams/1e6))
+ print('Number of decoder parameters = %.2fm' % (model.decoder.nparams/1e6))
+
+ load_model(args.checkpoint_path, model)
+ torch.save({'model': model.state_dict()}, "gvc.pth")
+ torch.save({'model': model.state_dict()}, "gvc.pretrain.pth")
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('-c', '--config', type=str, default='./configs/base.yaml',
+ help="yaml file for config.")
+ parser.add_argument('-p', '--checkpoint_path', type=str, required=True,
+ help="path of checkpoint pt file for evaluation")
+ args = parser.parse_args()
+
+ main(args)
diff --git a/gvc_inference.py b/gvc_inference.py
new file mode 100644
index 0000000..332b984
--- /dev/null
+++ b/gvc_inference.py
@@ -0,0 +1,153 @@
+import sys,os
+sys.path.append(os.path.dirname(os.path.abspath(__file__)))
+import torch
+import argparse
+import numpy as np
+
+from omegaconf import OmegaConf
+from pitch import load_csv_pitch
+from spec.inference import print_mel
+
+from grad.utils import fix_len_compatibility
+from grad.model import GradTTS
+
+
+def load_gvc_model(checkpoint_path, model):
+ assert os.path.isfile(checkpoint_path)
+ checkpoint_dict = torch.load(checkpoint_path, map_location="cpu")
+ saved_state_dict = checkpoint_dict
+ state_dict = model.state_dict()
+ new_state_dict = {}
+ for k, v in state_dict.items():
+ try:
+ new_state_dict[k] = saved_state_dict[k]
+ except:
+ print("%s is not in the checkpoint" % k)
+ new_state_dict[k] = v
+ model.load_state_dict(new_state_dict)
+ return model
+
+
+@torch.no_grad()
+def gvc_main(device, model, _vec, _pit, spk):
+ l_vec = _vec.shape[0]
+ d_vec = _vec.shape[1]
+ lengths_fix = fix_len_compatibility(l_vec)
+ lengths = torch.LongTensor([l_vec]).to(device)
+ vec = torch.zeros((1, lengths_fix, d_vec), dtype=torch.float32).to(device)
+ pit = torch.zeros((1, lengths_fix), dtype=torch.float32).to(device)
+ vec[0, :l_vec, :] = _vec
+ pit[0, :l_vec] = _pit
+ y_enc, y_dec = model(lengths, vec, pit, spk, n_timesteps=50)
+ y_dec = y_dec.squeeze(0)
+ y_dec = y_dec[:, :l_vec]
+ return y_dec
+
+
+def main(args):
+
+ if (args.vec == None):
+ args.vec = "gvc_tmp.vec.npy"
+ print(
+ f"Auto run : python hubert/inference.py -w {args.wave} -v {args.vec}")
+ os.system(f"python hubert/inference.py -w {args.wave} -v {args.vec}")
+
+ if (args.pit == None):
+ args.pit = "gvc_tmp.pit.csv"
+ print(
+ f"Auto run : python pitch/inference.py -w {args.wave} -p {args.pit}")
+ os.system(f"python pitch/inference.py -w {args.wave} -p {args.pit}")
+
+ device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
+ hps = OmegaConf.load(args.config)
+
+ print('Initializing Grad-TTS...')
+ model = GradTTS(hps.grad.n_mels, hps.grad.n_vecs, hps.grad.n_pits, hps.grad.n_spks, hps.grad.n_embs,
+ hps.grad.n_enc_channels, hps.grad.filter_channels,
+ hps.grad.dec_dim, hps.grad.beta_min, hps.grad.beta_max, hps.grad.pe_scale)
+ print('Number of encoder parameters = %.2fm' % (model.encoder.nparams/1e6))
+ print('Number of decoder parameters = %.2fm' % (model.decoder.nparams/1e6))
+
+ load_gvc_model(args.model, model)
+ model.eval()
+ model.to(device)
+
+ spk = np.load(args.spk)
+ spk = torch.FloatTensor(spk)
+
+ vec = np.load(args.vec)
+ vec = np.repeat(vec, 2, 0)
+ vec = torch.FloatTensor(vec)
+
+ pit = load_csv_pitch(args.pit)
+ pit = np.array(pit)
+ pit = pit * 2 ** (args.shift / 12)
+ pit = torch.FloatTensor(pit)
+
+ len_pit = pit.size()[0]
+ len_vec = vec.size()[0]
+ len_min = min(len_pit, len_vec)
+ pit = pit[:len_min]
+ vec = vec[:len_min, :]
+
+ with torch.no_grad():
+ spk = spk.unsqueeze(0).to(device)
+
+ all_frame = len_min
+ hop_frame = 8
+ out_chunk = 2400 # 24 S
+ out_index = 0
+ out_mel = None
+
+ while (out_index < all_frame):
+ if (out_index == 0): # start frame
+ cut_s = 0
+ cut_s_out = 0
+ else:
+ cut_s = out_index - hop_frame
+ cut_s_out = hop_frame
+
+ if (out_index + out_chunk + hop_frame > all_frame): # end frame
+ cut_e = all_frame
+ cut_e_out = -1
+ else:
+ cut_e = out_index + out_chunk + hop_frame
+ cut_e_out = -1 * hop_frame
+
+ sub_vec = vec[cut_s:cut_e, :].to(device)
+ sub_pit = pit[cut_s:cut_e].to(device)
+
+ sub_out = gvc_main(device, model, sub_vec, sub_pit, spk)
+ sub_out = sub_out[:, cut_s_out:cut_e_out]
+
+ out_index = out_index + out_chunk
+ if out_mel == None:
+ out_mel = sub_out
+ else:
+ out_mel = torch.cat((out_mel, sub_out), -1)
+ if cut_e == all_frame:
+ break
+
+ torch.save(out_mel, "gvc_out.mel.pt")
+ print_mel(out_mel, "gvc_out.mel.png")
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--config', type=str, default='./configs/base.yaml',
+ help="yaml file for config.")
+ parser.add_argument('--model', type=str, required=True,
+ help="path of model for evaluation")
+ parser.add_argument('--wave', type=str, required=True,
+ help="Path of raw audio.")
+ parser.add_argument('--spk', type=str, required=True,
+ help="Path of speaker.")
+ parser.add_argument('--vec', type=str,
+ help="Path of hubert vector.")
+ parser.add_argument('--pit', type=str,
+ help="Path of pitch csv file.")
+ parser.add_argument('--shift', type=int, default=0,
+ help="Pitch shift key.")
+ args = parser.parse_args()
+
+ main(args)
diff --git a/gvc_inference_wave.py b/gvc_inference_wave.py
new file mode 100644
index 0000000..9ed17b8
--- /dev/null
+++ b/gvc_inference_wave.py
@@ -0,0 +1,71 @@
+import sys,os
+sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+import torch
+import argparse
+
+from omegaconf import OmegaConf
+from scipy.io.wavfile import write
+from bigvgan.model.generator import Generator
+from pitch import load_csv_pitch
+
+
+def load_bigv_model(checkpoint_path, model):
+ assert os.path.isfile(checkpoint_path)
+ checkpoint_dict = torch.load(checkpoint_path, map_location="cpu")
+ saved_state_dict = checkpoint_dict["model_g"]
+ state_dict = model.state_dict()
+ new_state_dict = {}
+ for k, v in state_dict.items():
+ try:
+ new_state_dict[k] = saved_state_dict[k]
+ except:
+ print("%s is not in the checkpoint" % k)
+ new_state_dict[k] = v
+ model.load_state_dict(new_state_dict)
+ return model
+
+
+def main(args):
+ device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
+ hp = OmegaConf.load(args.config)
+ model = Generator(hp)
+ load_bigv_model(args.model, model)
+ model.eval()
+ model.to(device)
+
+ mel = torch.load(args.mel)
+
+ pit = load_csv_pitch(args.pit)
+ pit = torch.FloatTensor(pit)
+
+ len_pit = pit.size()[0]
+ len_mel = mel.size()[1]
+ len_min = min(len_pit, len_mel)
+ pit = pit[:len_min]
+ mel = mel[:, :len_min]
+
+ with torch.no_grad():
+ mel = mel.unsqueeze(0).to(device)
+ pit = pit.unsqueeze(0).to(device)
+ audio = model.inference(mel, pit)
+ audio = audio.cpu().detach().numpy()
+
+ pitwav = model.pitch2wav(pit)
+ pitwav = pitwav.cpu().detach().numpy()
+
+ write("gvc_out.wav", hp.audio.sampling_rate, audio)
+ write("gvc_pitch.wav", hp.audio.sampling_rate, pitwav)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--mel', type=str,
+ help="Path of content vector.")
+ parser.add_argument('--pit', type=str,
+ help="Path of pitch csv file.")
+ args = parser.parse_args()
+
+ args.config = "./bigvgan/configs/nsf_bigvgan.yaml"
+ args.model = "./bigvgan_pretrain/nsf_bigvgan_pretrain_32K.pth"
+
+ main(args)
diff --git a/gvc_trainer.py b/gvc_trainer.py
new file mode 100644
index 0000000..4802ada
--- /dev/null
+++ b/gvc_trainer.py
@@ -0,0 +1,30 @@
+import sys,os
+sys.path.append(os.path.dirname(os.path.abspath(__file__)))
+import argparse
+import torch
+import numpy as np
+
+from omegaconf import OmegaConf
+from grad_extend.train import train
+
+torch.backends.cudnn.benchmark = True
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('-c', '--config', type=str, default='./configs/base.yaml',
+ help="yaml file for configuration")
+ parser.add_argument('-p', '--checkpoint_path', type=str, default=None,
+ help="path of checkpoint pt file to resume training")
+ args = parser.parse_args()
+
+ assert torch.cuda.is_available()
+ print('Numbers of GPU :', torch.cuda.device_count())
+
+ hps = OmegaConf.load(args.config)
+
+ np.random.seed(hps.train.seed)
+ torch.manual_seed(hps.train.seed)
+ torch.cuda.manual_seed(hps.train.seed)
+
+ train(hps, args.checkpoint_path)
diff --git a/hubert/__init__.py b/hubert/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/hubert/hubert_model.py b/hubert/hubert_model.py
new file mode 100644
index 0000000..09df44c
--- /dev/null
+++ b/hubert/hubert_model.py
@@ -0,0 +1,229 @@
+import copy
+import random
+from typing import Optional, Tuple
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as t_func
+
+
+class Hubert(nn.Module):
+ def __init__(self, num_label_embeddings: int = 100, mask: bool = True):
+ super().__init__()
+ self._mask = mask
+ self.feature_extractor = FeatureExtractor()
+ self.feature_projection = FeatureProjection()
+ self.positional_embedding = PositionalConvEmbedding()
+ self.norm = nn.LayerNorm(768)
+ self.dropout = nn.Dropout(0.1)
+ self.encoder = TransformerEncoder(
+ nn.TransformerEncoderLayer(
+ 768, 12, 3072, activation="gelu", batch_first=True
+ ),
+ 12,
+ )
+ self.proj = nn.Linear(768, 256)
+
+ self.masked_spec_embed = nn.Parameter(torch.FloatTensor(768).uniform_())
+ self.label_embedding = nn.Embedding(num_label_embeddings, 256)
+
+ def mask(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
+ mask = None
+ if self.training and self._mask:
+ mask = _compute_mask((x.size(0), x.size(1)), 0.8, 10, x.device, 2)
+ x[mask] = self.masked_spec_embed.to(x.dtype)
+ return x, mask
+
+ def encode(
+ self, x: torch.Tensor, layer: Optional[int] = None
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ x = self.feature_extractor(x)
+ x = self.feature_projection(x.transpose(1, 2))
+ x, mask = self.mask(x)
+ x = x + self.positional_embedding(x)
+ x = self.dropout(self.norm(x))
+ x = self.encoder(x, output_layer=layer)
+ return x, mask
+
+ def logits(self, x: torch.Tensor) -> torch.Tensor:
+ logits = torch.cosine_similarity(
+ x.unsqueeze(2),
+ self.label_embedding.weight.unsqueeze(0).unsqueeze(0),
+ dim=-1,
+ )
+ return logits / 0.1
+
+ def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
+ x, mask = self.encode(x)
+ x = self.proj(x)
+ logits = self.logits(x)
+ return logits, mask
+
+
+class HubertSoft(Hubert):
+ def __init__(self):
+ super().__init__()
+
+ @torch.inference_mode()
+ def units(self, wav: torch.Tensor) -> torch.Tensor:
+ wav = t_func.pad(wav, ((400 - 320) // 2, (400 - 320) // 2))
+ x, _ = self.encode(wav)
+ return self.proj(x)
+
+
+class FeatureExtractor(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.conv0 = nn.Conv1d(1, 512, 10, 5, bias=False)
+ self.norm0 = nn.GroupNorm(512, 512)
+ self.conv1 = nn.Conv1d(512, 512, 3, 2, bias=False)
+ self.conv2 = nn.Conv1d(512, 512, 3, 2, bias=False)
+ self.conv3 = nn.Conv1d(512, 512, 3, 2, bias=False)
+ self.conv4 = nn.Conv1d(512, 512, 3, 2, bias=False)
+ self.conv5 = nn.Conv1d(512, 512, 2, 2, bias=False)
+ self.conv6 = nn.Conv1d(512, 512, 2, 2, bias=False)
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ x = t_func.gelu(self.norm0(self.conv0(x)))
+ x = t_func.gelu(self.conv1(x))
+ x = t_func.gelu(self.conv2(x))
+ x = t_func.gelu(self.conv3(x))
+ x = t_func.gelu(self.conv4(x))
+ x = t_func.gelu(self.conv5(x))
+ x = t_func.gelu(self.conv6(x))
+ return x
+
+
+class FeatureProjection(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.norm = nn.LayerNorm(512)
+ self.projection = nn.Linear(512, 768)
+ self.dropout = nn.Dropout(0.1)
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ x = self.norm(x)
+ x = self.projection(x)
+ x = self.dropout(x)
+ return x
+
+
+class PositionalConvEmbedding(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.conv = nn.Conv1d(
+ 768,
+ 768,
+ kernel_size=128,
+ padding=128 // 2,
+ groups=16,
+ )
+ self.conv = nn.utils.weight_norm(self.conv, name="weight", dim=2)
+
+ def forward(self, x: torch.Tensor) -> torch.Tensor:
+ x = self.conv(x.transpose(1, 2))
+ x = t_func.gelu(x[:, :, :-1])
+ return x.transpose(1, 2)
+
+
+class TransformerEncoder(nn.Module):
+ def __init__(
+ self, encoder_layer: nn.TransformerEncoderLayer, num_layers: int
+ ) -> None:
+ super(TransformerEncoder, self).__init__()
+ self.layers = nn.ModuleList(
+ [copy.deepcopy(encoder_layer) for _ in range(num_layers)]
+ )
+ self.num_layers = num_layers
+
+ def forward(
+ self,
+ src: torch.Tensor,
+ mask: torch.Tensor = None,
+ src_key_padding_mask: torch.Tensor = None,
+ output_layer: Optional[int] = None,
+ ) -> torch.Tensor:
+ output = src
+ for layer in self.layers[:output_layer]:
+ output = layer(
+ output, src_mask=mask, src_key_padding_mask=src_key_padding_mask
+ )
+ return output
+
+
+def _compute_mask(
+ shape: Tuple[int, int],
+ mask_prob: float,
+ mask_length: int,
+ device: torch.device,
+ min_masks: int = 0,
+) -> torch.Tensor:
+ batch_size, sequence_length = shape
+
+ if mask_length < 1:
+ raise ValueError("`mask_length` has to be bigger than 0.")
+
+ if mask_length > sequence_length:
+ raise ValueError(
+ f"`mask_length` has to be smaller than `sequence_length`, but got `mask_length`: {mask_length} and `sequence_length`: {sequence_length}`"
+ )
+
+ # compute number of masked spans in batch
+ num_masked_spans = int(mask_prob * sequence_length / mask_length + random.random())
+ num_masked_spans = max(num_masked_spans, min_masks)
+
+ # make sure num masked indices <= sequence_length
+ if num_masked_spans * mask_length > sequence_length:
+ num_masked_spans = sequence_length // mask_length
+
+ # SpecAugment mask to fill
+ mask = torch.zeros((batch_size, sequence_length), device=device, dtype=torch.bool)
+
+ # uniform distribution to sample from, make sure that offset samples are < sequence_length
+ uniform_dist = torch.ones(
+ (batch_size, sequence_length - (mask_length - 1)), device=device
+ )
+
+ # get random indices to mask
+ mask_indices = torch.multinomial(uniform_dist, num_masked_spans)
+
+ # expand masked indices to masked spans
+ mask_indices = (
+ mask_indices.unsqueeze(dim=-1)
+ .expand((batch_size, num_masked_spans, mask_length))
+ .reshape(batch_size, num_masked_spans * mask_length)
+ )
+ offsets = (
+ torch.arange(mask_length, device=device)[None, None, :]
+ .expand((batch_size, num_masked_spans, mask_length))
+ .reshape(batch_size, num_masked_spans * mask_length)
+ )
+ mask_idxs = mask_indices + offsets
+
+ # scatter indices to mask
+ mask = mask.scatter(1, mask_idxs, True)
+
+ return mask
+
+
+def consume_prefix(state_dict, prefix: str) -> None:
+ keys = sorted(state_dict.keys())
+ for key in keys:
+ if key.startswith(prefix):
+ newkey = key[len(prefix):]
+ state_dict[newkey] = state_dict.pop(key)
+
+
+def hubert_soft(
+ path: str,
+) -> HubertSoft:
+ r"""HuBERT-Soft from `"A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion"`.
+ Args:
+ path (str): path of a pretrained model
+ """
+ hubert = HubertSoft()
+ checkpoint = torch.load(path)
+ consume_prefix(checkpoint, "module.")
+ hubert.load_state_dict(checkpoint)
+ hubert.eval()
+ return hubert
diff --git a/hubert/inference.py b/hubert/inference.py
new file mode 100644
index 0000000..a40bdeb
--- /dev/null
+++ b/hubert/inference.py
@@ -0,0 +1,67 @@
+import sys,os
+sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+import numpy as np
+import argparse
+import torch
+import librosa
+
+from hubert import hubert_model
+
+
+def load_audio(file: str, sr: int = 16000):
+ x, sr = librosa.load(file, sr=sr)
+ return x
+
+
+def load_model(path, device):
+ model = hubert_model.hubert_soft(path)
+ model.eval()
+ if not (device == "cpu"):
+ model.half()
+ model.to(device)
+ return model
+
+
+def pred_vec(model, wavPath, vecPath, device):
+ audio = load_audio(wavPath)
+ audln = audio.shape[0]
+ vec_a = []
+ idx_s = 0
+ while (idx_s + 20 * 16000 < audln):
+ feats = audio[idx_s:idx_s + 20 * 16000]
+ feats = torch.from_numpy(feats).to(device)
+ feats = feats[None, None, :]
+ if not (device == "cpu"):
+ feats = feats.half()
+ with torch.no_grad():
+ vec = model.units(feats).squeeze().data.cpu().float().numpy()
+ vec_a.extend(vec)
+ idx_s = idx_s + 20 * 16000
+ if (idx_s < audln):
+ feats = audio[idx_s:audln]
+ feats = torch.from_numpy(feats).to(device)
+ feats = feats[None, None, :]
+ if not (device == "cpu"):
+ feats = feats.half()
+ with torch.no_grad():
+ vec = model.units(feats).squeeze().data.cpu().float().numpy()
+ # print(vec.shape) # [length, dim=256] hop=320
+ vec_a.extend(vec)
+ np.save(vecPath, vec_a, allow_pickle=False)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("-w", "--wav", help="wav", dest="wav")
+ parser.add_argument("-v", "--vec", help="vec", dest="vec")
+ args = parser.parse_args()
+ print(args.wav)
+ print(args.vec)
+
+ wavPath = args.wav
+ vecPath = args.vec
+
+ device = "cuda" if torch.cuda.is_available() else "cpu"
+ hubert = load_model(os.path.join(
+ "hubert_pretrain", "hubert-soft-0d54a1f4.pt"), device)
+ pred_vec(hubert, wavPath, vecPath, device)
diff --git a/hubert_pretrain/README.md b/hubert_pretrain/README.md
new file mode 100644
index 0000000..dbecfeb
--- /dev/null
+++ b/hubert_pretrain/README.md
@@ -0,0 +1,3 @@
+Path for:
+
+ hubert-soft-0d54a1f4.pt
\ No newline at end of file
diff --git a/pitch/__init__.py b/pitch/__init__.py
new file mode 100644
index 0000000..bc41814
--- /dev/null
+++ b/pitch/__init__.py
@@ -0,0 +1 @@
+from .inference import load_csv_pitch
\ No newline at end of file
diff --git a/pitch/inference.py b/pitch/inference.py
new file mode 100644
index 0000000..f5c6309
--- /dev/null
+++ b/pitch/inference.py
@@ -0,0 +1,54 @@
+import sys,os
+sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+import librosa
+import argparse
+import numpy as np
+import parselmouth
+# pip install praat-parselmouth
+
+def compute_f0_mouth(path):
+ x, sr = librosa.load(path, sr=16000)
+ assert sr == 16000
+ lpad = 1024 // 160
+ rpad = lpad
+ f0 = parselmouth.Sound(x, sr).to_pitch_ac(
+ time_step=160 / sr,
+ voicing_threshold=0.5,
+ pitch_floor=30,
+ pitch_ceiling=1000).selected_array['frequency']
+ f0 = np.pad(f0, [[lpad, rpad]], mode='constant')
+ return f0
+
+
+def save_csv_pitch(pitch, path):
+ with open(path, "w", encoding='utf-8') as pitch_file:
+ for i in range(len(pitch)):
+ t = i * 10
+ minute = t // 60000
+ seconds = (t - minute * 60000) // 1000
+ millisecond = t % 1000
+ print(
+ f"{minute}m {seconds}s {millisecond:3d},{int(pitch[i])}", file=pitch_file)
+
+
+def load_csv_pitch(path):
+ pitch = []
+ with open(path, "r", encoding='utf-8') as pitch_file:
+ for line in pitch_file.readlines():
+ pit = line.strip().split(",")[-1]
+ pitch.append(int(pit))
+ return pitch
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("-w", "--wav", help="wav", dest="wav")
+ parser.add_argument("-p", "--pit", help="pit", dest="pit") # csv for excel
+ args = parser.parse_args()
+ print(args.wav)
+ print(args.pit)
+
+ pitch = compute_f0_mouth(args.wav)
+ save_csv_pitch(pitch, args.pit)
+ #tmp = load_csv_pitch(args.pit)
+ #save_csv_pitch(tmp, "tmp.csv")
diff --git a/prepare/preprocess_a.py b/prepare/preprocess_a.py
new file mode 100644
index 0000000..87d03b5
--- /dev/null
+++ b/prepare/preprocess_a.py
@@ -0,0 +1,58 @@
+import os
+import librosa
+import argparse
+import numpy as np
+from tqdm import tqdm
+from concurrent.futures import ThreadPoolExecutor, as_completed
+from scipy.io import wavfile
+
+
+def resample_wave(wav_in, wav_out, sample_rate):
+ wav, _ = librosa.load(wav_in, sr=sample_rate)
+ wav = wav / np.abs(wav).max() * 0.6
+ wav = wav / max(0.01, np.max(np.abs(wav))) * 32767 * 0.6
+ wavfile.write(wav_out, sample_rate, wav.astype(np.int16))
+
+
+def process_file(file, wavPath, spks, outPath, sr):
+ if file.endswith(".wav"):
+ file = file[:-4]
+ resample_wave(f"{wavPath}/{spks}/{file}.wav", f"{outPath}/{spks}/{file}.wav", sr)
+
+
+def process_files_with_thread_pool(wavPath, spks, outPath, sr, thread_num=None):
+ files = [f for f in os.listdir(f"./{wavPath}/{spks}") if f.endswith(".wav")]
+
+ with ThreadPoolExecutor(max_workers=thread_num) as executor:
+ futures = {executor.submit(process_file, file, wavPath, spks, outPath, sr): file for file in files}
+
+ for future in tqdm(as_completed(futures), total=len(futures), desc=f'Processing {sr} {spks}'):
+ future.result()
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("-w", "--wav", help="wav", dest="wav", required=True)
+ parser.add_argument("-o", "--out", help="out", dest="out", required=True)
+ parser.add_argument("-s", "--sr", help="sample rate", dest="sr", type=int, required=True)
+ parser.add_argument("-t", "--thread_count", help="thread count to process, set 0 to use all cpu cores", dest="thread_count", type=int, default=1)
+
+ args = parser.parse_args()
+ print(args.wav)
+ print(args.out)
+ print(args.sr)
+
+ os.makedirs(args.out, exist_ok=True)
+ wavPath = args.wav
+ outPath = args.out
+
+ assert args.sr == 16000 or args.sr == 32000
+
+ for spks in os.listdir(wavPath):
+ if os.path.isdir(f"./{wavPath}/{spks}"):
+ os.makedirs(f"./{outPath}/{spks}", exist_ok=True)
+ if args.thread_count == 0:
+ process_num = os.cpu_count() // 2 + 1
+ else:
+ process_num = args.thread_count
+ process_files_with_thread_pool(wavPath, spks, outPath, args.sr, process_num)
diff --git a/prepare/preprocess_f0.py b/prepare/preprocess_f0.py
new file mode 100644
index 0000000..bdae0a0
--- /dev/null
+++ b/prepare/preprocess_f0.py
@@ -0,0 +1,64 @@
+import os
+import numpy as np
+import librosa
+import argparse
+import parselmouth
+# pip install praat-parselmouth
+from tqdm import tqdm
+from concurrent.futures import ProcessPoolExecutor, as_completed
+
+
+def compute_f0(path, save):
+ x, sr = librosa.load(path, sr=16000)
+ assert sr == 16000
+ lpad = 1024 // 160
+ rpad = lpad
+ f0 = parselmouth.Sound(x, sr).to_pitch_ac(
+ time_step=160 / sr,
+ voicing_threshold=0.5,
+ pitch_floor=30,
+ pitch_ceiling=1000).selected_array['frequency']
+ f0 = np.pad(f0, [[lpad, rpad]], mode='constant')
+ for index, pitch in enumerate(f0):
+ f0[index] = round(pitch, 1)
+ np.save(save, f0, allow_pickle=False)
+
+
+def process_file(file, wavPath, spks, pitPath):
+ if file.endswith(".wav"):
+ file = file[:-4]
+ compute_f0(f"{wavPath}/{spks}/{file}.wav", f"{pitPath}/{spks}/{file}.pit")
+
+
+def process_files_with_process_pool(wavPath, spks, pitPath, process_num=None):
+ files = [f for f in os.listdir(f"./{wavPath}/{spks}") if f.endswith(".wav")]
+
+ with ProcessPoolExecutor(max_workers=process_num) as executor:
+ futures = {executor.submit(process_file, file, wavPath, spks, pitPath): file for file in files}
+
+ for future in tqdm(as_completed(futures), total=len(futures), desc=f'Processing f0 {spks}'):
+ future.result()
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("-w", "--wav", help="wav", dest="wav", required=True)
+ parser.add_argument("-p", "--pit", help="pit", dest="pit", required=True)
+ parser.add_argument("-t", "--thread_count", help="thread count to process, set 0 to use all cpu cores", dest="thread_count", type=int, default=1)
+
+ args = parser.parse_args()
+ print(args.wav)
+ print(args.pit)
+
+ os.makedirs(args.pit, exist_ok=True)
+ wavPath = args.wav
+ pitPath = args.pit
+
+ for spks in os.listdir(wavPath):
+ if os.path.isdir(f"./{wavPath}/{spks}"):
+ os.makedirs(f"./{pitPath}/{spks}", exist_ok=True)
+ if args.thread_count == 0:
+ process_num = os.cpu_count() // 2 + 1
+ else:
+ process_num = args.thread_count
+ process_files_with_process_pool(wavPath, spks, pitPath, process_num)
diff --git a/prepare/preprocess_hubert.py b/prepare/preprocess_hubert.py
new file mode 100644
index 0000000..dd4265b
--- /dev/null
+++ b/prepare/preprocess_hubert.py
@@ -0,0 +1,58 @@
+import sys,os
+sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+import numpy as np
+import argparse
+import torch
+import librosa
+
+from tqdm import tqdm
+from hubert import hubert_model
+
+
+def load_audio(file: str, sr: int = 16000):
+ x, sr = librosa.load(file, sr=sr)
+ return x
+
+
+def load_model(path, device):
+ model = hubert_model.hubert_soft(path)
+ model.eval()
+ model.half()
+ model.to(device)
+ return model
+
+
+def pred_vec(model, wavPath, vecPath, device):
+ feats = load_audio(wavPath)
+ feats = torch.from_numpy(feats).to(device)
+ feats = feats[None, None, :].half()
+ with torch.no_grad():
+ vec = model.units(feats).squeeze().data.cpu().float().numpy()
+ # print(vec.shape) # [length, dim=256] hop=320
+ np.save(vecPath, vec, allow_pickle=False)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("-w", "--wav", help="wav", dest="wav", required=True)
+ parser.add_argument("-v", "--vec", help="vec", dest="vec", required=True)
+
+ args = parser.parse_args()
+ print(args.wav)
+ print(args.vec)
+ os.makedirs(args.vec, exist_ok=True)
+
+ wavPath = args.wav
+ vecPath = args.vec
+
+ device = "cuda" if torch.cuda.is_available() else "cpu"
+ hubert = load_model(os.path.join("hubert_pretrain", "hubert-soft-0d54a1f4.pt"), device)
+
+ for spks in os.listdir(wavPath):
+ if os.path.isdir(f"./{wavPath}/{spks}"):
+ os.makedirs(f"./{vecPath}/{spks}", exist_ok=True)
+
+ files = [f for f in os.listdir(f"./{wavPath}/{spks}") if f.endswith(".wav")]
+ for file in tqdm(files, desc=f'Processing vec {spks}'):
+ file = file[:-4]
+ pred_vec(hubert, f"{wavPath}/{spks}/{file}.wav", f"{vecPath}/{spks}/{file}.vec", device)
diff --git a/prepare/preprocess_random.py b/prepare/preprocess_random.py
new file mode 100644
index 0000000..f84977b
--- /dev/null
+++ b/prepare/preprocess_random.py
@@ -0,0 +1,23 @@
+import random
+
+
+if __name__ == "__main__":
+ all_items = []
+ fo = open("./files/train_all.txt", "r+", encoding='utf-8')
+ while (True):
+ try:
+ item = fo.readline().strip()
+ except Exception as e:
+ print('nothing of except:', e)
+ break
+ if (item == None or item == ""):
+ break
+ all_items.append(item)
+ fo.close()
+
+ random.shuffle(all_items)
+
+ fw = open("./files/train_all.txt", "w", encoding="utf-8")
+ for strs in all_items:
+ print(strs, file=fw)
+ fw.close()
diff --git a/prepare/preprocess_speaker.py b/prepare/preprocess_speaker.py
new file mode 100644
index 0000000..797b60e
--- /dev/null
+++ b/prepare/preprocess_speaker.py
@@ -0,0 +1,103 @@
+import sys,os
+sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+import torch
+import numpy as np
+import argparse
+
+from tqdm import tqdm
+from functools import partial
+from argparse import RawTextHelpFormatter
+from multiprocessing.pool import ThreadPool
+
+from speaker.models.lstm import LSTMSpeakerEncoder
+from speaker.config import SpeakerEncoderConfig
+from speaker.utils.audio import AudioProcessor
+from speaker.infer import read_json
+
+
+def get_spk_wavs(dataset_path, output_path):
+ wav_files = []
+ os.makedirs(f"./{output_path}", exist_ok=True)
+ for spks in os.listdir(dataset_path):
+ if os.path.isdir(f"./{dataset_path}/{spks}"):
+ os.makedirs(f"./{output_path}/{spks}", exist_ok=True)
+ for file in os.listdir(f"./{dataset_path}/{spks}"):
+ if file.endswith(".wav"):
+ wav_files.append(f"./{dataset_path}/{spks}/{file}")
+ elif spks.endswith(".wav"):
+ wav_files.append(f"./{dataset_path}/{spks}")
+ return wav_files
+
+
+def process_wav(wav_file, dataset_path, output_path, args, speaker_encoder_ap, speaker_encoder):
+ waveform = speaker_encoder_ap.load_wav(
+ wav_file, sr=speaker_encoder_ap.sample_rate
+ )
+ spec = speaker_encoder_ap.melspectrogram(waveform)
+ spec = torch.from_numpy(spec.T)
+ if args.use_cuda:
+ spec = spec.cuda()
+ spec = spec.unsqueeze(0)
+ embed = speaker_encoder.compute_embedding(spec).detach().cpu().numpy()
+ embed = embed.squeeze()
+ embed_path = wav_file.replace(dataset_path, output_path)
+ embed_path = embed_path.replace(".wav", ".spk")
+ np.save(embed_path, embed, allow_pickle=False)
+
+
+def extract_speaker_embeddings(wav_files, dataset_path, output_path, args, speaker_encoder_ap, speaker_encoder, concurrency):
+ bound_process_wav = partial(process_wav, dataset_path=dataset_path, output_path=output_path, args=args, speaker_encoder_ap=speaker_encoder_ap, speaker_encoder=speaker_encoder)
+
+ with ThreadPool(concurrency) as pool:
+ list(tqdm(pool.imap(bound_process_wav, wav_files), total=len(wav_files)))
+
+
+if __name__ == "__main__":
+
+ parser = argparse.ArgumentParser(
+ description="""Compute embedding vectors for each wav file in a dataset.""",
+ formatter_class=RawTextHelpFormatter,
+ )
+ parser.add_argument("dataset_path", type=str, help="Path to dataset waves.")
+ parser.add_argument(
+ "output_path", type=str, help="path for output speaker/speaker_wavs.npy."
+ )
+ parser.add_argument("--use_cuda", type=bool, help="flag to set cuda.", default=True)
+ parser.add_argument("-t", "--thread_count", help="thread count to process, set 0 to use all cpu cores", dest="thread_count", type=int, default=1)
+ args = parser.parse_args()
+ dataset_path = args.dataset_path
+ output_path = args.output_path
+ thread_count = args.thread_count
+ # model
+ args.model_path = os.path.join("speaker_pretrain", "best_model.pth.tar")
+ args.config_path = os.path.join("speaker_pretrain", "config.json")
+ # config
+ config_dict = read_json(args.config_path)
+
+ # model
+ config = SpeakerEncoderConfig(config_dict)
+ config.from_dict(config_dict)
+
+ speaker_encoder = LSTMSpeakerEncoder(
+ config.model_params["input_dim"],
+ config.model_params["proj_dim"],
+ config.model_params["lstm_dim"],
+ config.model_params["num_lstm_layers"],
+ )
+
+ speaker_encoder.load_checkpoint(args.model_path, eval=True, use_cuda=args.use_cuda)
+
+ # preprocess
+ speaker_encoder_ap = AudioProcessor(**config.audio)
+ # normalize the input audio level and trim silences
+ speaker_encoder_ap.do_sound_norm = True
+ speaker_encoder_ap.do_trim_silence = True
+
+ wav_files = get_spk_wavs(dataset_path, output_path)
+
+ if thread_count == 0:
+ process_num = os.cpu_count()
+ else:
+ process_num = thread_count
+
+ extract_speaker_embeddings(wav_files, dataset_path, output_path, args, speaker_encoder_ap, speaker_encoder, process_num)
\ No newline at end of file
diff --git a/prepare/preprocess_speaker_ave.py b/prepare/preprocess_speaker_ave.py
new file mode 100644
index 0000000..9423f61
--- /dev/null
+++ b/prepare/preprocess_speaker_ave.py
@@ -0,0 +1,54 @@
+import os
+import torch
+import argparse
+import numpy as np
+from tqdm import tqdm
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("dataset_speaker", type=str)
+ parser.add_argument("dataset_singer", type=str)
+
+ data_speaker = parser.parse_args().dataset_speaker
+ data_singer = parser.parse_args().dataset_singer
+
+ os.makedirs(data_singer, exist_ok=True)
+
+ for speaker in os.listdir(data_speaker):
+ subfile_num = 0
+ speaker_ave = 0
+
+ for file in tqdm(os.listdir(os.path.join(data_speaker, speaker)), desc=f"average {speaker}"):
+ if not file.endswith(".npy"):
+ continue
+ source_embed = np.load(os.path.join(data_speaker, speaker, file))
+ source_embed = source_embed.astype(np.float32)
+ speaker_ave = speaker_ave + source_embed
+ subfile_num = subfile_num + 1
+ if subfile_num == 0:
+ continue
+ speaker_ave = speaker_ave / subfile_num
+
+ np.save(os.path.join(data_singer, f"{speaker}.spk.npy"),
+ speaker_ave, allow_pickle=False)
+
+ # rewrite timbre code by average, if similarity is larger than cmp_val
+ rewrite_timbre_code = False
+ if not rewrite_timbre_code:
+ continue
+ cmp_src = torch.FloatTensor(speaker_ave)
+ cmp_num = 0
+ cmp_val = 0.85
+ for file in tqdm(os.listdir(os.path.join(data_speaker, speaker)), desc=f"rewrite {speaker}"):
+ if not file.endswith(".npy"):
+ continue
+ cmp_tmp = np.load(os.path.join(data_speaker, speaker, file))
+ cmp_tmp = cmp_tmp.astype(np.float32)
+ cmp_tmp = torch.FloatTensor(cmp_tmp)
+ cmp_cos = torch.cosine_similarity(cmp_src, cmp_tmp, dim=0)
+ if (cmp_cos > cmp_val):
+ cmp_num += 1
+ np.save(os.path.join(data_speaker, speaker, file),
+ speaker_ave, allow_pickle=False)
+ print(f"rewrite timbre for {speaker} with :", cmp_num)
diff --git a/prepare/preprocess_spec.py b/prepare/preprocess_spec.py
new file mode 100644
index 0000000..8304f15
--- /dev/null
+++ b/prepare/preprocess_spec.py
@@ -0,0 +1,52 @@
+import sys,os
+sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+import torch
+import argparse
+from concurrent.futures import ThreadPoolExecutor
+from spec.inference import mel_spectrogram_file
+from tqdm import tqdm
+from omegaconf import OmegaConf
+
+
+def compute_spec(hps, filename, specname):
+ spec = mel_spectrogram_file(filename, hps)
+ spec = torch.squeeze(spec, 0)
+ # print(spec.shape)
+ torch.save(spec, specname)
+
+
+def process_file(file):
+ if file.endswith(".wav"):
+ file = file[:-4]
+ compute_spec(hps, f"{wavPath}/{spks}/{file}.wav", f"{spePath}/{spks}/{file}.mel.pt")
+
+
+def process_files_with_thread_pool(wavPath, spks, thread_num):
+ files = os.listdir(f"./{wavPath}/{spks}")
+ with ThreadPoolExecutor(max_workers=thread_num) as executor:
+ list(tqdm(executor.map(process_file, files), total=len(files), desc=f'Processing spec {spks}'))
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("-w", "--wav", help="wav", dest="wav", required=True)
+ parser.add_argument("-s", "--spe", help="spe", dest="spe", required=True)
+ parser.add_argument("-t", "--thread_count", help="thread count to process, set 0 to use all cpu cores", dest="thread_count", type=int, default=1)
+
+ args = parser.parse_args()
+ print(args.wav)
+ print(args.spe)
+
+ os.makedirs(args.spe, exist_ok=True)
+ wavPath = args.wav
+ spePath = args.spe
+ hps = OmegaConf.load("./configs/base.yaml")
+
+ for spks in os.listdir(wavPath):
+ if os.path.isdir(f"./{wavPath}/{spks}"):
+ os.makedirs(f"./{spePath}/{spks}", exist_ok=True)
+ if args.thread_count == 0:
+ process_num = os.cpu_count() // 2 + 1
+ else:
+ process_num = args.thread_count
+ process_files_with_thread_pool(wavPath, spks, process_num)
diff --git a/prepare/preprocess_train.py b/prepare/preprocess_train.py
new file mode 100644
index 0000000..6410a0b
--- /dev/null
+++ b/prepare/preprocess_train.py
@@ -0,0 +1,56 @@
+import os
+import random
+
+
+def print_error(info):
+ print(f"\033[31m File isn't existed: {info}\033[0m")
+
+
+if __name__ == "__main__":
+ os.makedirs("./files/", exist_ok=True)
+
+ rootPath = "./data_svc/waves-32k/"
+ all_items = []
+ for spks in os.listdir(f"./{rootPath}"):
+ if not os.path.isdir(f"./{rootPath}/{spks}"):
+ continue
+ print(f"./{rootPath}/{spks}")
+ for file in os.listdir(f"./{rootPath}/{spks}"):
+ if file.endswith(".wav"):
+ file = file[:-4]
+
+ path_mel = f"./data_svc/mel/{spks}/{file}.mel.pt"
+ path_vec = f"./data_svc/hubert/{spks}/{file}.vec.npy"
+ path_pit = f"./data_svc/pitch/{spks}/{file}.pit.npy"
+ path_spk = f"./data_svc/speaker/{spks}/{file}.spk.npy"
+
+ has_error = 0
+ if not os.path.isfile(path_mel):
+ print_error(path_mel)
+ has_error = 1
+ if not os.path.isfile(path_vec):
+ print_error(path_vec)
+ has_error = 1
+ if not os.path.isfile(path_pit):
+ print_error(path_pit)
+ has_error = 1
+ if not os.path.isfile(path_spk):
+ print_error(path_spk)
+ has_error = 1
+ if has_error == 0:
+ all_items.append(
+ f"{path_mel}|{path_vec}|{path_pit}|{path_spk}")
+
+ random.shuffle(all_items)
+ valids = all_items[:10]
+ valids.sort()
+ trains = all_items[10:]
+ # trains.sort()
+ fw = open("./files/valid.txt", "w", encoding="utf-8")
+ for strs in valids:
+ print(strs, file=fw)
+ fw.close()
+ fw = open("./files/train.txt", "w", encoding="utf-8")
+ for strs in trains:
+ print(strs, file=fw)
+ fw.close()
diff --git a/prepare/preprocess_zzz.py b/prepare/preprocess_zzz.py
new file mode 100644
index 0000000..03659e2
--- /dev/null
+++ b/prepare/preprocess_zzz.py
@@ -0,0 +1,30 @@
+import sys,os
+sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
+from tqdm import tqdm
+from torch.utils.data import DataLoader
+from grad_extend.data import TextMelSpeakerDataset, TextMelSpeakerBatchCollate
+
+
+filelist_path = "files/valid.txt"
+
+dataset = TextMelSpeakerDataset(filelist_path)
+collate = TextMelSpeakerBatchCollate()
+loader = DataLoader(dataset=dataset,
+ batch_size=2,
+ collate_fn=collate,
+ drop_last=True,
+ num_workers=1,
+ shuffle=True)
+
+for batch in tqdm(loader):
+ lengths = batch['lengths'].cuda()
+ vec = batch['vec'].cuda()
+ pit = batch['pit'].cuda()
+ spk = batch['spk'].cuda()
+ mel = batch['mel'].cuda()
+
+ print('len', lengths.shape)
+ print('vec', vec.shape)
+ print('pit', pit.shape)
+ print('spk', spk.shape)
+ print('mel', mel.shape)
\ No newline at end of file
diff --git a/requirements.txt b/requirements.txt
new file mode 100644
index 0000000..908feb5
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,10 @@
+librosa
+soundfile
+matplotlib
+tensorboard
+transformers
+tqdm
+einops
+fsspec
+omegaconf
+praat-parselmouth
\ No newline at end of file
diff --git a/speaker/__init__.py b/speaker/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/speaker/config.py b/speaker/config.py
new file mode 100644
index 0000000..7172ee2
--- /dev/null
+++ b/speaker/config.py
@@ -0,0 +1,64 @@
+from dataclasses import asdict, dataclass, field
+from typing import Dict, List
+
+from .utils.coqpit import MISSING
+from .utils.shared_configs import BaseAudioConfig, BaseDatasetConfig, BaseTrainingConfig
+
+
+@dataclass
+class SpeakerEncoderConfig(BaseTrainingConfig):
+ """Defines parameters for Speaker Encoder model."""
+
+ model: str = "speaker_encoder"
+ audio: BaseAudioConfig = field(default_factory=BaseAudioConfig)
+ datasets: List[BaseDatasetConfig] = field(default_factory=lambda: [BaseDatasetConfig()])
+ # model params
+ model_params: Dict = field(
+ default_factory=lambda: {
+ "model_name": "lstm",
+ "input_dim": 80,
+ "proj_dim": 256,
+ "lstm_dim": 768,
+ "num_lstm_layers": 3,
+ "use_lstm_with_projection": True,
+ }
+ )
+
+ audio_augmentation: Dict = field(default_factory=lambda: {})
+
+ storage: Dict = field(
+ default_factory=lambda: {
+ "sample_from_storage_p": 0.66, # the probability with which we'll sample from the DataSet in-memory storage
+ "storage_size": 15, # the size of the in-memory storage with respect to a single batch
+ }
+ )
+
+ # training params
+ max_train_step: int = 1000000 # end training when number of training steps reaches this value.
+ loss: str = "angleproto"
+ grad_clip: float = 3.0
+ lr: float = 0.0001
+ lr_decay: bool = False
+ warmup_steps: int = 4000
+ wd: float = 1e-6
+
+ # logging params
+ tb_model_param_stats: bool = False
+ steps_plot_stats: int = 10
+ checkpoint: bool = True
+ save_step: int = 1000
+ print_step: int = 20
+
+ # data loader
+ num_speakers_in_batch: int = MISSING
+ num_utters_per_speaker: int = MISSING
+ num_loader_workers: int = MISSING
+ skip_speakers: bool = False
+ voice_len: float = 1.6
+
+ def check_values(self):
+ super().check_values()
+ c = asdict(self)
+ assert (
+ c["model_params"]["input_dim"] == self.audio.num_mels
+ ), " [!] model input dimendion must be equal to melspectrogram dimension."
diff --git a/speaker/infer.py b/speaker/infer.py
new file mode 100644
index 0000000..b69b2ee
--- /dev/null
+++ b/speaker/infer.py
@@ -0,0 +1,108 @@
+import re
+import json
+import fsspec
+import torch
+import numpy as np
+import argparse
+
+from argparse import RawTextHelpFormatter
+from .models.lstm import LSTMSpeakerEncoder
+from .config import SpeakerEncoderConfig
+from .utils.audio import AudioProcessor
+
+
+def read_json(json_path):
+ config_dict = {}
+ try:
+ with fsspec.open(json_path, "r", encoding="utf-8") as f:
+ data = json.load(f)
+ except json.decoder.JSONDecodeError:
+ # backwards compat.
+ data = read_json_with_comments(json_path)
+ config_dict.update(data)
+ return config_dict
+
+
+def read_json_with_comments(json_path):
+ """for backward compat."""
+ # fallback to json
+ with fsspec.open(json_path, "r", encoding="utf-8") as f:
+ input_str = f.read()
+ # handle comments
+ input_str = re.sub(r"\\\n", "", input_str)
+ input_str = re.sub(r"//.*\n", "\n", input_str)
+ data = json.loads(input_str)
+ return data
+
+
+if __name__ == "__main__":
+
+ parser = argparse.ArgumentParser(
+ description="""Compute embedding vectors for each wav file in a dataset.""",
+ formatter_class=RawTextHelpFormatter,
+ )
+ parser.add_argument("model_path", type=str, help="Path to model checkpoint file.")
+ parser.add_argument(
+ "config_path",
+ type=str,
+ help="Path to model config file.",
+ )
+
+ parser.add_argument("-s", "--source", help="input wave", dest="source")
+ parser.add_argument(
+ "-t", "--target", help="output 256d speaker embeddimg", dest="target"
+ )
+
+ parser.add_argument("--use_cuda", type=bool, help="flag to set cuda.", default=True)
+ parser.add_argument("--eval", type=bool, help="compute eval.", default=True)
+
+ args = parser.parse_args()
+ source_file = args.source
+ target_file = args.target
+
+ # config
+ config_dict = read_json(args.config_path)
+ # print(config_dict)
+
+ # model
+ config = SpeakerEncoderConfig(config_dict)
+ config.from_dict(config_dict)
+
+ speaker_encoder = LSTMSpeakerEncoder(
+ config.model_params["input_dim"],
+ config.model_params["proj_dim"],
+ config.model_params["lstm_dim"],
+ config.model_params["num_lstm_layers"],
+ )
+
+ speaker_encoder.load_checkpoint(args.model_path, eval=True, use_cuda=args.use_cuda)
+
+ # preprocess
+ speaker_encoder_ap = AudioProcessor(**config.audio)
+ # normalize the input audio level and trim silences
+ speaker_encoder_ap.do_sound_norm = True
+ speaker_encoder_ap.do_trim_silence = True
+
+ # compute speaker embeddings
+
+ # extract the embedding
+ waveform = speaker_encoder_ap.load_wav(
+ source_file, sr=speaker_encoder_ap.sample_rate
+ )
+ spec = speaker_encoder_ap.melspectrogram(waveform)
+ spec = torch.from_numpy(spec.T)
+ if args.use_cuda:
+ spec = spec.cuda()
+ spec = spec.unsqueeze(0)
+ embed = speaker_encoder.compute_embedding(spec).detach().cpu().numpy()
+ embed = embed.squeeze()
+ # print(embed)
+ # print(embed.size)
+ np.save(target_file, embed, allow_pickle=False)
+
+
+ if hasattr(speaker_encoder, 'module'):
+ state_dict = speaker_encoder.module.state_dict()
+ else:
+ state_dict = speaker_encoder.state_dict()
+ torch.save({'model': state_dict}, "model_small.pth")
diff --git a/speaker/models/__init__.py b/speaker/models/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/speaker/models/lstm.py b/speaker/models/lstm.py
new file mode 100644
index 0000000..45e8cce
--- /dev/null
+++ b/speaker/models/lstm.py
@@ -0,0 +1,131 @@
+import numpy as np
+import torch
+from torch import nn
+
+from ..utils.io import load_fsspec
+
+
+class LSTMWithProjection(nn.Module):
+ def __init__(self, input_size, hidden_size, proj_size):
+ super().__init__()
+ self.input_size = input_size
+ self.hidden_size = hidden_size
+ self.proj_size = proj_size
+ self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
+ self.linear = nn.Linear(hidden_size, proj_size, bias=False)
+
+ def forward(self, x):
+ self.lstm.flatten_parameters()
+ o, (_, _) = self.lstm(x)
+ return self.linear(o)
+
+
+class LSTMWithoutProjection(nn.Module):
+ def __init__(self, input_dim, lstm_dim, proj_dim, num_lstm_layers):
+ super().__init__()
+ self.lstm = nn.LSTM(input_size=input_dim, hidden_size=lstm_dim, num_layers=num_lstm_layers, batch_first=True)
+ self.linear = nn.Linear(lstm_dim, proj_dim, bias=True)
+ self.relu = nn.ReLU()
+
+ def forward(self, x):
+ _, (hidden, _) = self.lstm(x)
+ return self.relu(self.linear(hidden[-1]))
+
+
+class LSTMSpeakerEncoder(nn.Module):
+ def __init__(self, input_dim, proj_dim=256, lstm_dim=768, num_lstm_layers=3, use_lstm_with_projection=True):
+ super().__init__()
+ self.use_lstm_with_projection = use_lstm_with_projection
+ layers = []
+ # choise LSTM layer
+ if use_lstm_with_projection:
+ layers.append(LSTMWithProjection(input_dim, lstm_dim, proj_dim))
+ for _ in range(num_lstm_layers - 1):
+ layers.append(LSTMWithProjection(proj_dim, lstm_dim, proj_dim))
+ self.layers = nn.Sequential(*layers)
+ else:
+ self.layers = LSTMWithoutProjection(input_dim, lstm_dim, proj_dim, num_lstm_layers)
+
+ self._init_layers()
+
+ def _init_layers(self):
+ for name, param in self.layers.named_parameters():
+ if "bias" in name:
+ nn.init.constant_(param, 0.0)
+ elif "weight" in name:
+ nn.init.xavier_normal_(param)
+
+ def forward(self, x):
+ # TODO: implement state passing for lstms
+ d = self.layers(x)
+ if self.use_lstm_with_projection:
+ d = torch.nn.functional.normalize(d[:, -1], p=2, dim=1)
+ else:
+ d = torch.nn.functional.normalize(d, p=2, dim=1)
+ return d
+
+ @torch.no_grad()
+ def inference(self, x):
+ d = self.layers.forward(x)
+ if self.use_lstm_with_projection:
+ d = torch.nn.functional.normalize(d[:, -1], p=2, dim=1)
+ else:
+ d = torch.nn.functional.normalize(d, p=2, dim=1)
+ return d
+
+ def compute_embedding(self, x, num_frames=250, num_eval=10, return_mean=True):
+ """
+ Generate embeddings for a batch of utterances
+ x: 1xTxD
+ """
+ max_len = x.shape[1]
+
+ if max_len < num_frames:
+ num_frames = max_len
+
+ offsets = np.linspace(0, max_len - num_frames, num=num_eval)
+
+ frames_batch = []
+ for offset in offsets:
+ offset = int(offset)
+ end_offset = int(offset + num_frames)
+ frames = x[:, offset:end_offset]
+ frames_batch.append(frames)
+
+ frames_batch = torch.cat(frames_batch, dim=0)
+ embeddings = self.inference(frames_batch)
+
+ if return_mean:
+ embeddings = torch.mean(embeddings, dim=0, keepdim=True)
+
+ return embeddings
+
+ def batch_compute_embedding(self, x, seq_lens, num_frames=160, overlap=0.5):
+ """
+ Generate embeddings for a batch of utterances
+ x: BxTxD
+ """
+ num_overlap = num_frames * overlap
+ max_len = x.shape[1]
+ embed = None
+ num_iters = seq_lens / (num_frames - num_overlap)
+ cur_iter = 0
+ for offset in range(0, max_len, num_frames - num_overlap):
+ cur_iter += 1
+ end_offset = min(x.shape[1], offset + num_frames)
+ frames = x[:, offset:end_offset]
+ if embed is None:
+ embed = self.inference(frames)
+ else:
+ embed[cur_iter <= num_iters, :] += self.inference(frames[cur_iter <= num_iters, :, :])
+ return embed / num_iters
+
+ # pylint: disable=unused-argument, redefined-builtin
+ def load_checkpoint(self, checkpoint_path: str, eval: bool = False, use_cuda: bool = False):
+ state = load_fsspec(checkpoint_path, map_location=torch.device("cpu"))
+ self.load_state_dict(state["model"])
+ if use_cuda:
+ self.cuda()
+ if eval:
+ self.eval()
+ assert not self.training
diff --git a/speaker/models/resnet.py b/speaker/models/resnet.py
new file mode 100644
index 0000000..fcc850d
--- /dev/null
+++ b/speaker/models/resnet.py
@@ -0,0 +1,212 @@
+import numpy as np
+import torch
+from torch import nn
+
+from TTS.utils.io import load_fsspec
+
+
+class SELayer(nn.Module):
+ def __init__(self, channel, reduction=8):
+ super(SELayer, self).__init__()
+ self.avg_pool = nn.AdaptiveAvgPool2d(1)
+ self.fc = nn.Sequential(
+ nn.Linear(channel, channel // reduction),
+ nn.ReLU(inplace=True),
+ nn.Linear(channel // reduction, channel),
+ nn.Sigmoid(),
+ )
+
+ def forward(self, x):
+ b, c, _, _ = x.size()
+ y = self.avg_pool(x).view(b, c)
+ y = self.fc(y).view(b, c, 1, 1)
+ return x * y
+
+
+class SEBasicBlock(nn.Module):
+ expansion = 1
+
+ def __init__(self, inplanes, planes, stride=1, downsample=None, reduction=8):
+ super(SEBasicBlock, self).__init__()
+ self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
+ self.bn1 = nn.BatchNorm2d(planes)
+ self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, padding=1, bias=False)
+ self.bn2 = nn.BatchNorm2d(planes)
+ self.relu = nn.ReLU(inplace=True)
+ self.se = SELayer(planes, reduction)
+ self.downsample = downsample
+ self.stride = stride
+
+ def forward(self, x):
+ residual = x
+
+ out = self.conv1(x)
+ out = self.relu(out)
+ out = self.bn1(out)
+
+ out = self.conv2(out)
+ out = self.bn2(out)
+ out = self.se(out)
+
+ if self.downsample is not None:
+ residual = self.downsample(x)
+
+ out += residual
+ out = self.relu(out)
+ return out
+
+
+class ResNetSpeakerEncoder(nn.Module):
+ """Implementation of the model H/ASP without batch normalization in speaker embedding. This model was proposed in: https://arxiv.org/abs/2009.14153
+ Adapted from: https://github.com/clovaai/voxceleb_trainer
+ """
+
+ # pylint: disable=W0102
+ def __init__(
+ self,
+ input_dim=64,
+ proj_dim=512,
+ layers=[3, 4, 6, 3],
+ num_filters=[32, 64, 128, 256],
+ encoder_type="ASP",
+ log_input=False,
+ ):
+ super(ResNetSpeakerEncoder, self).__init__()
+
+ self.encoder_type = encoder_type
+ self.input_dim = input_dim
+ self.log_input = log_input
+ self.conv1 = nn.Conv2d(1, num_filters[0], kernel_size=3, stride=1, padding=1)
+ self.relu = nn.ReLU(inplace=True)
+ self.bn1 = nn.BatchNorm2d(num_filters[0])
+
+ self.inplanes = num_filters[0]
+ self.layer1 = self.create_layer(SEBasicBlock, num_filters[0], layers[0])
+ self.layer2 = self.create_layer(SEBasicBlock, num_filters[1], layers[1], stride=(2, 2))
+ self.layer3 = self.create_layer(SEBasicBlock, num_filters[2], layers[2], stride=(2, 2))
+ self.layer4 = self.create_layer(SEBasicBlock, num_filters[3], layers[3], stride=(2, 2))
+
+ self.instancenorm = nn.InstanceNorm1d(input_dim)
+
+ outmap_size = int(self.input_dim / 8)
+
+ self.attention = nn.Sequential(
+ nn.Conv1d(num_filters[3] * outmap_size, 128, kernel_size=1),
+ nn.ReLU(),
+ nn.BatchNorm1d(128),
+ nn.Conv1d(128, num_filters[3] * outmap_size, kernel_size=1),
+ nn.Softmax(dim=2),
+ )
+
+ if self.encoder_type == "SAP":
+ out_dim = num_filters[3] * outmap_size
+ elif self.encoder_type == "ASP":
+ out_dim = num_filters[3] * outmap_size * 2
+ else:
+ raise ValueError("Undefined encoder")
+
+ self.fc = nn.Linear(out_dim, proj_dim)
+
+ self._init_layers()
+
+ def _init_layers(self):
+ for m in self.modules():
+ if isinstance(m, nn.Conv2d):
+ nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
+ elif isinstance(m, nn.BatchNorm2d):
+ nn.init.constant_(m.weight, 1)
+ nn.init.constant_(m.bias, 0)
+
+ def create_layer(self, block, planes, blocks, stride=1):
+ downsample = None
+ if stride != 1 or self.inplanes != planes * block.expansion:
+ downsample = nn.Sequential(
+ nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=1, stride=stride, bias=False),
+ nn.BatchNorm2d(planes * block.expansion),
+ )
+
+ layers = []
+ layers.append(block(self.inplanes, planes, stride, downsample))
+ self.inplanes = planes * block.expansion
+ for _ in range(1, blocks):
+ layers.append(block(self.inplanes, planes))
+
+ return nn.Sequential(*layers)
+
+ # pylint: disable=R0201
+ def new_parameter(self, *size):
+ out = nn.Parameter(torch.FloatTensor(*size))
+ nn.init.xavier_normal_(out)
+ return out
+
+ def forward(self, x, l2_norm=False):
+ x = x.transpose(1, 2)
+ with torch.no_grad():
+ with torch.cuda.amp.autocast(enabled=False):
+ if self.log_input:
+ x = (x + 1e-6).log()
+ x = self.instancenorm(x).unsqueeze(1)
+
+ x = self.conv1(x)
+ x = self.relu(x)
+ x = self.bn1(x)
+
+ x = self.layer1(x)
+ x = self.layer2(x)
+ x = self.layer3(x)
+ x = self.layer4(x)
+
+ x = x.reshape(x.size()[0], -1, x.size()[-1])
+
+ w = self.attention(x)
+
+ if self.encoder_type == "SAP":
+ x = torch.sum(x * w, dim=2)
+ elif self.encoder_type == "ASP":
+ mu = torch.sum(x * w, dim=2)
+ sg = torch.sqrt((torch.sum((x ** 2) * w, dim=2) - mu ** 2).clamp(min=1e-5))
+ x = torch.cat((mu, sg), 1)
+
+ x = x.view(x.size()[0], -1)
+ x = self.fc(x)
+
+ if l2_norm:
+ x = torch.nn.functional.normalize(x, p=2, dim=1)
+ return x
+
+ @torch.no_grad()
+ def compute_embedding(self, x, num_frames=250, num_eval=10, return_mean=True):
+ """
+ Generate embeddings for a batch of utterances
+ x: 1xTxD
+ """
+ max_len = x.shape[1]
+
+ if max_len < num_frames:
+ num_frames = max_len
+
+ offsets = np.linspace(0, max_len - num_frames, num=num_eval)
+
+ frames_batch = []
+ for offset in offsets:
+ offset = int(offset)
+ end_offset = int(offset + num_frames)
+ frames = x[:, offset:end_offset]
+ frames_batch.append(frames)
+
+ frames_batch = torch.cat(frames_batch, dim=0)
+ embeddings = self.forward(frames_batch, l2_norm=True)
+
+ if return_mean:
+ embeddings = torch.mean(embeddings, dim=0, keepdim=True)
+
+ return embeddings
+
+ def load_checkpoint(self, config: dict, checkpoint_path: str, eval: bool = False, use_cuda: bool = False):
+ state = load_fsspec(checkpoint_path, map_location=torch.device("cpu"))
+ self.load_state_dict(state["model"])
+ if use_cuda:
+ self.cuda()
+ if eval:
+ self.eval()
+ assert not self.training
diff --git a/speaker/utils/__init__.py b/speaker/utils/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/speaker/utils/audio.py b/speaker/utils/audio.py
new file mode 100644
index 0000000..e2c9627
--- /dev/null
+++ b/speaker/utils/audio.py
@@ -0,0 +1,822 @@
+from typing import Dict, Tuple
+
+import librosa
+import numpy as np
+import pyworld as pw
+import scipy.io.wavfile
+import scipy.signal
+import soundfile as sf
+import torch
+from torch import nn
+
+class StandardScaler:
+ """StandardScaler for mean-scale normalization with the given mean and scale values."""
+
+ def __init__(self, mean: np.ndarray = None, scale: np.ndarray = None) -> None:
+ self.mean_ = mean
+ self.scale_ = scale
+
+ def set_stats(self, mean, scale):
+ self.mean_ = mean
+ self.scale_ = scale
+
+ def reset_stats(self):
+ delattr(self, "mean_")
+ delattr(self, "scale_")
+
+ def transform(self, X):
+ X = np.asarray(X)
+ X -= self.mean_
+ X /= self.scale_
+ return X
+
+ def inverse_transform(self, X):
+ X = np.asarray(X)
+ X *= self.scale_
+ X += self.mean_
+ return X
+
+class TorchSTFT(nn.Module): # pylint: disable=abstract-method
+ """Some of the audio processing funtions using Torch for faster batch processing.
+
+ TODO: Merge this with audio.py
+ """
+
+ def __init__(
+ self,
+ n_fft,
+ hop_length,
+ win_length,
+ pad_wav=False,
+ window="hann_window",
+ sample_rate=None,
+ mel_fmin=0,
+ mel_fmax=None,
+ n_mels=80,
+ use_mel=False,
+ do_amp_to_db=False,
+ spec_gain=1.0,
+ ):
+ super().__init__()
+ self.n_fft = n_fft
+ self.hop_length = hop_length
+ self.win_length = win_length
+ self.pad_wav = pad_wav
+ self.sample_rate = sample_rate
+ self.mel_fmin = mel_fmin
+ self.mel_fmax = mel_fmax
+ self.n_mels = n_mels
+ self.use_mel = use_mel
+ self.do_amp_to_db = do_amp_to_db
+ self.spec_gain = spec_gain
+ self.window = nn.Parameter(getattr(torch, window)(win_length), requires_grad=False)
+ self.mel_basis = None
+ if use_mel:
+ self._build_mel_basis()
+
+ def __call__(self, x):
+ """Compute spectrogram frames by torch based stft.
+
+ Args:
+ x (Tensor): input waveform
+
+ Returns:
+ Tensor: spectrogram frames.
+
+ Shapes:
+ x: [B x T] or [:math:`[B, 1, T]`]
+ """
+ if x.ndim == 2:
+ x = x.unsqueeze(1)
+ if self.pad_wav:
+ padding = int((self.n_fft - self.hop_length) / 2)
+ x = torch.nn.functional.pad(x, (padding, padding), mode="reflect")
+ # B x D x T x 2
+ o = torch.stft(
+ x.squeeze(1),
+ self.n_fft,
+ self.hop_length,
+ self.win_length,
+ self.window,
+ center=True,
+ pad_mode="reflect", # compatible with audio.py
+ normalized=False,
+ onesided=True,
+ return_complex=False,
+ )
+ M = o[:, :, :, 0]
+ P = o[:, :, :, 1]
+ S = torch.sqrt(torch.clamp(M ** 2 + P ** 2, min=1e-8))
+ if self.use_mel:
+ S = torch.matmul(self.mel_basis.to(x), S)
+ if self.do_amp_to_db:
+ S = self._amp_to_db(S, spec_gain=self.spec_gain)
+ return S
+
+ def _build_mel_basis(self):
+ mel_basis = librosa.filters.mel(
+ sr=self.sample_rate, n_fft=self.n_fft, n_mels=self.n_mels, fmin=self.mel_fmin, fmax=self.mel_fmax
+ )
+ self.mel_basis = torch.from_numpy(mel_basis).float()
+
+ @staticmethod
+ def _amp_to_db(x, spec_gain=1.0):
+ return torch.log(torch.clamp(x, min=1e-5) * spec_gain)
+
+ @staticmethod
+ def _db_to_amp(x, spec_gain=1.0):
+ return torch.exp(x) / spec_gain
+
+
+# pylint: disable=too-many-public-methods
+class AudioProcessor(object):
+ """Audio Processor for TTS used by all the data pipelines.
+
+ Note:
+ All the class arguments are set to default values to enable a flexible initialization
+ of the class with the model config. They are not meaningful for all the arguments.
+
+ Args:
+ sample_rate (int, optional):
+ target audio sampling rate. Defaults to None.
+
+ resample (bool, optional):
+ enable/disable resampling of the audio clips when the target sampling rate does not match the original sampling rate. Defaults to False.
+
+ num_mels (int, optional):
+ number of melspectrogram dimensions. Defaults to None.
+
+ log_func (int, optional):
+ log exponent used for converting spectrogram aplitude to DB.
+
+ min_level_db (int, optional):
+ minimum db threshold for the computed melspectrograms. Defaults to None.
+
+ frame_shift_ms (int, optional):
+ milliseconds of frames between STFT columns. Defaults to None.
+
+ frame_length_ms (int, optional):
+ milliseconds of STFT window length. Defaults to None.
+
+ hop_length (int, optional):
+ number of frames between STFT columns. Used if ```frame_shift_ms``` is None. Defaults to None.
+
+ win_length (int, optional):
+ STFT window length. Used if ```frame_length_ms``` is None. Defaults to None.
+
+ ref_level_db (int, optional):
+ reference DB level to avoid background noise. In general <20DB corresponds to the air noise. Defaults to None.
+
+ fft_size (int, optional):
+ FFT window size for STFT. Defaults to 1024.
+
+ power (int, optional):
+ Exponent value applied to the spectrogram before GriffinLim. Defaults to None.
+
+ preemphasis (float, optional):
+ Preemphasis coefficient. Preemphasis is disabled if == 0.0. Defaults to 0.0.
+
+ signal_norm (bool, optional):
+ enable/disable signal normalization. Defaults to None.
+
+ symmetric_norm (bool, optional):
+ enable/disable symmetric normalization. If set True normalization is performed in the range [-k, k] else [0, k], Defaults to None.
+
+ max_norm (float, optional):
+ ```k``` defining the normalization range. Defaults to None.
+
+ mel_fmin (int, optional):
+ minimum filter frequency for computing melspectrograms. Defaults to None.
+
+ mel_fmax (int, optional):
+ maximum filter frequency for computing melspectrograms.. Defaults to None.
+
+ spec_gain (int, optional):
+ gain applied when converting amplitude to DB. Defaults to 20.
+
+ stft_pad_mode (str, optional):
+ Padding mode for STFT. Defaults to 'reflect'.
+
+ clip_norm (bool, optional):
+ enable/disable clipping the our of range values in the normalized audio signal. Defaults to True.
+
+ griffin_lim_iters (int, optional):
+ Number of GriffinLim iterations. Defaults to None.
+
+ do_trim_silence (bool, optional):
+ enable/disable silence trimming when loading the audio signal. Defaults to False.
+
+ trim_db (int, optional):
+ DB threshold used for silence trimming. Defaults to 60.
+
+ do_sound_norm (bool, optional):
+ enable/disable signal normalization. Defaults to False.
+
+ do_amp_to_db_linear (bool, optional):
+ enable/disable amplitude to dB conversion of linear spectrograms. Defaults to True.
+
+ do_amp_to_db_mel (bool, optional):
+ enable/disable amplitude to dB conversion of mel spectrograms. Defaults to True.
+
+ stats_path (str, optional):
+ Path to the computed stats file. Defaults to None.
+
+ verbose (bool, optional):
+ enable/disable logging. Defaults to True.
+
+ """
+
+ def __init__(
+ self,
+ sample_rate=None,
+ resample=False,
+ num_mels=None,
+ log_func="np.log10",
+ min_level_db=None,
+ frame_shift_ms=None,
+ frame_length_ms=None,
+ hop_length=None,
+ win_length=None,
+ ref_level_db=None,
+ fft_size=1024,
+ power=None,
+ preemphasis=0.0,
+ signal_norm=None,
+ symmetric_norm=None,
+ max_norm=None,
+ mel_fmin=None,
+ mel_fmax=None,
+ spec_gain=20,
+ stft_pad_mode="reflect",
+ clip_norm=True,
+ griffin_lim_iters=None,
+ do_trim_silence=False,
+ trim_db=60,
+ do_sound_norm=False,
+ do_amp_to_db_linear=True,
+ do_amp_to_db_mel=True,
+ stats_path=None,
+ verbose=True,
+ **_,
+ ):
+
+ # setup class attributed
+ self.sample_rate = sample_rate
+ self.resample = resample
+ self.num_mels = num_mels
+ self.log_func = log_func
+ self.min_level_db = min_level_db or 0
+ self.frame_shift_ms = frame_shift_ms
+ self.frame_length_ms = frame_length_ms
+ self.ref_level_db = ref_level_db
+ self.fft_size = fft_size
+ self.power = power
+ self.preemphasis = preemphasis
+ self.griffin_lim_iters = griffin_lim_iters
+ self.signal_norm = signal_norm
+ self.symmetric_norm = symmetric_norm
+ self.mel_fmin = mel_fmin or 0
+ self.mel_fmax = mel_fmax
+ self.spec_gain = float(spec_gain)
+ self.stft_pad_mode = stft_pad_mode
+ self.max_norm = 1.0 if max_norm is None else float(max_norm)
+ self.clip_norm = clip_norm
+ self.do_trim_silence = do_trim_silence
+ self.trim_db = trim_db
+ self.do_sound_norm = do_sound_norm
+ self.do_amp_to_db_linear = do_amp_to_db_linear
+ self.do_amp_to_db_mel = do_amp_to_db_mel
+ self.stats_path = stats_path
+ # setup exp_func for db to amp conversion
+ if log_func == "np.log":
+ self.base = np.e
+ elif log_func == "np.log10":
+ self.base = 10
+ else:
+ raise ValueError(" [!] unknown `log_func` value.")
+ # setup stft parameters
+ if hop_length is None:
+ # compute stft parameters from given time values
+ self.hop_length, self.win_length = self._stft_parameters()
+ else:
+ # use stft parameters from config file
+ self.hop_length = hop_length
+ self.win_length = win_length
+ assert min_level_db != 0.0, " [!] min_level_db is 0"
+ assert self.win_length <= self.fft_size, " [!] win_length cannot be larger than fft_size"
+ members = vars(self)
+ if verbose:
+ print(" > Setting up Audio Processor...")
+ for key, value in members.items():
+ print(" | > {}:{}".format(key, value))
+ # create spectrogram utils
+ self.mel_basis = self._build_mel_basis()
+ self.inv_mel_basis = np.linalg.pinv(self._build_mel_basis())
+ # setup scaler
+ if stats_path and signal_norm:
+ mel_mean, mel_std, linear_mean, linear_std, _ = self.load_stats(stats_path)
+ self.setup_scaler(mel_mean, mel_std, linear_mean, linear_std)
+ self.signal_norm = True
+ self.max_norm = None
+ self.clip_norm = None
+ self.symmetric_norm = None
+
+ ### setting up the parameters ###
+ def _build_mel_basis(
+ self,
+ ) -> np.ndarray:
+ """Build melspectrogram basis.
+
+ Returns:
+ np.ndarray: melspectrogram basis.
+ """
+ if self.mel_fmax is not None:
+ assert self.mel_fmax <= self.sample_rate // 2
+ return librosa.filters.mel(
+ sr=self.sample_rate, n_fft=self.fft_size, n_mels=self.num_mels, fmin=self.mel_fmin, fmax=self.mel_fmax
+ )
+
+ def _stft_parameters(
+ self,
+ ) -> Tuple[int, int]:
+ """Compute the real STFT parameters from the time values.
+
+ Returns:
+ Tuple[int, int]: hop length and window length for STFT.
+ """
+ factor = self.frame_length_ms / self.frame_shift_ms
+ assert (factor).is_integer(), " [!] frame_shift_ms should divide frame_length_ms"
+ hop_length = int(self.frame_shift_ms / 1000.0 * self.sample_rate)
+ win_length = int(hop_length * factor)
+ return hop_length, win_length
+
+ ### normalization ###
+ def normalize(self, S: np.ndarray) -> np.ndarray:
+ """Normalize values into `[0, self.max_norm]` or `[-self.max_norm, self.max_norm]`
+
+ Args:
+ S (np.ndarray): Spectrogram to normalize.
+
+ Raises:
+ RuntimeError: Mean and variance is computed from incompatible parameters.
+
+ Returns:
+ np.ndarray: Normalized spectrogram.
+ """
+ # pylint: disable=no-else-return
+ S = S.copy()
+ if self.signal_norm:
+ # mean-var scaling
+ if hasattr(self, "mel_scaler"):
+ if S.shape[0] == self.num_mels:
+ return self.mel_scaler.transform(S.T).T
+ elif S.shape[0] == self.fft_size / 2:
+ return self.linear_scaler.transform(S.T).T
+ else:
+ raise RuntimeError(" [!] Mean-Var stats does not match the given feature dimensions.")
+ # range normalization
+ S -= self.ref_level_db # discard certain range of DB assuming it is air noise
+ S_norm = (S - self.min_level_db) / (-self.min_level_db)
+ if self.symmetric_norm:
+ S_norm = ((2 * self.max_norm) * S_norm) - self.max_norm
+ if self.clip_norm:
+ S_norm = np.clip(
+ S_norm, -self.max_norm, self.max_norm # pylint: disable=invalid-unary-operand-type
+ )
+ return S_norm
+ else:
+ S_norm = self.max_norm * S_norm
+ if self.clip_norm:
+ S_norm = np.clip(S_norm, 0, self.max_norm)
+ return S_norm
+ else:
+ return S
+
+ def denormalize(self, S: np.ndarray) -> np.ndarray:
+ """Denormalize spectrogram values.
+
+ Args:
+ S (np.ndarray): Spectrogram to denormalize.
+
+ Raises:
+ RuntimeError: Mean and variance are incompatible.
+
+ Returns:
+ np.ndarray: Denormalized spectrogram.
+ """
+ # pylint: disable=no-else-return
+ S_denorm = S.copy()
+ if self.signal_norm:
+ # mean-var scaling
+ if hasattr(self, "mel_scaler"):
+ if S_denorm.shape[0] == self.num_mels:
+ return self.mel_scaler.inverse_transform(S_denorm.T).T
+ elif S_denorm.shape[0] == self.fft_size / 2:
+ return self.linear_scaler.inverse_transform(S_denorm.T).T
+ else:
+ raise RuntimeError(" [!] Mean-Var stats does not match the given feature dimensions.")
+ if self.symmetric_norm:
+ if self.clip_norm:
+ S_denorm = np.clip(
+ S_denorm, -self.max_norm, self.max_norm # pylint: disable=invalid-unary-operand-type
+ )
+ S_denorm = ((S_denorm + self.max_norm) * -self.min_level_db / (2 * self.max_norm)) + self.min_level_db
+ return S_denorm + self.ref_level_db
+ else:
+ if self.clip_norm:
+ S_denorm = np.clip(S_denorm, 0, self.max_norm)
+ S_denorm = (S_denorm * -self.min_level_db / self.max_norm) + self.min_level_db
+ return S_denorm + self.ref_level_db
+ else:
+ return S_denorm
+
+ ### Mean-STD scaling ###
+ def load_stats(self, stats_path: str) -> Tuple[np.array, np.array, np.array, np.array, Dict]:
+ """Loading mean and variance statistics from a `npy` file.
+
+ Args:
+ stats_path (str): Path to the `npy` file containing
+
+ Returns:
+ Tuple[np.array, np.array, np.array, np.array, Dict]: loaded statistics and the config used to
+ compute them.
+ """
+ stats = np.load(stats_path, allow_pickle=True).item() # pylint: disable=unexpected-keyword-arg
+ mel_mean = stats["mel_mean"]
+ mel_std = stats["mel_std"]
+ linear_mean = stats["linear_mean"]
+ linear_std = stats["linear_std"]
+ stats_config = stats["audio_config"]
+ # check all audio parameters used for computing stats
+ skip_parameters = ["griffin_lim_iters", "stats_path", "do_trim_silence", "ref_level_db", "power"]
+ for key in stats_config.keys():
+ if key in skip_parameters:
+ continue
+ if key not in ["sample_rate", "trim_db"]:
+ assert (
+ stats_config[key] == self.__dict__[key]
+ ), f" [!] Audio param {key} does not match the value used for computing mean-var stats. {stats_config[key]} vs {self.__dict__[key]}"
+ return mel_mean, mel_std, linear_mean, linear_std, stats_config
+
+ # pylint: disable=attribute-defined-outside-init
+ def setup_scaler(
+ self, mel_mean: np.ndarray, mel_std: np.ndarray, linear_mean: np.ndarray, linear_std: np.ndarray
+ ) -> None:
+ """Initialize scaler objects used in mean-std normalization.
+
+ Args:
+ mel_mean (np.ndarray): Mean for melspectrograms.
+ mel_std (np.ndarray): STD for melspectrograms.
+ linear_mean (np.ndarray): Mean for full scale spectrograms.
+ linear_std (np.ndarray): STD for full scale spectrograms.
+ """
+ self.mel_scaler = StandardScaler()
+ self.mel_scaler.set_stats(mel_mean, mel_std)
+ self.linear_scaler = StandardScaler()
+ self.linear_scaler.set_stats(linear_mean, linear_std)
+
+ ### DB and AMP conversion ###
+ # pylint: disable=no-self-use
+ def _amp_to_db(self, x: np.ndarray) -> np.ndarray:
+ """Convert amplitude values to decibels.
+
+ Args:
+ x (np.ndarray): Amplitude spectrogram.
+
+ Returns:
+ np.ndarray: Decibels spectrogram.
+ """
+ return self.spec_gain * _log(np.maximum(1e-5, x), self.base)
+
+ # pylint: disable=no-self-use
+ def _db_to_amp(self, x: np.ndarray) -> np.ndarray:
+ """Convert decibels spectrogram to amplitude spectrogram.
+
+ Args:
+ x (np.ndarray): Decibels spectrogram.
+
+ Returns:
+ np.ndarray: Amplitude spectrogram.
+ """
+ return _exp(x / self.spec_gain, self.base)
+
+ ### Preemphasis ###
+ def apply_preemphasis(self, x: np.ndarray) -> np.ndarray:
+ """Apply pre-emphasis to the audio signal. Useful to reduce the correlation between neighbouring signal values.
+
+ Args:
+ x (np.ndarray): Audio signal.
+
+ Raises:
+ RuntimeError: Preemphasis coeff is set to 0.
+
+ Returns:
+ np.ndarray: Decorrelated audio signal.
+ """
+ if self.preemphasis == 0:
+ raise RuntimeError(" [!] Preemphasis is set 0.0.")
+ return scipy.signal.lfilter([1, -self.preemphasis], [1], x)
+
+ def apply_inv_preemphasis(self, x: np.ndarray) -> np.ndarray:
+ """Reverse pre-emphasis."""
+ if self.preemphasis == 0:
+ raise RuntimeError(" [!] Preemphasis is set 0.0.")
+ return scipy.signal.lfilter([1], [1, -self.preemphasis], x)
+
+ ### SPECTROGRAMs ###
+ def _linear_to_mel(self, spectrogram: np.ndarray) -> np.ndarray:
+ """Project a full scale spectrogram to a melspectrogram.
+
+ Args:
+ spectrogram (np.ndarray): Full scale spectrogram.
+
+ Returns:
+ np.ndarray: Melspectrogram
+ """
+ return np.dot(self.mel_basis, spectrogram)
+
+ def _mel_to_linear(self, mel_spec: np.ndarray) -> np.ndarray:
+ """Convert a melspectrogram to full scale spectrogram."""
+ return np.maximum(1e-10, np.dot(self.inv_mel_basis, mel_spec))
+
+ def spectrogram(self, y: np.ndarray) -> np.ndarray:
+ """Compute a spectrogram from a waveform.
+
+ Args:
+ y (np.ndarray): Waveform.
+
+ Returns:
+ np.ndarray: Spectrogram.
+ """
+ if self.preemphasis != 0:
+ D = self._stft(self.apply_preemphasis(y))
+ else:
+ D = self._stft(y)
+ if self.do_amp_to_db_linear:
+ S = self._amp_to_db(np.abs(D))
+ else:
+ S = np.abs(D)
+ return self.normalize(S).astype(np.float32)
+
+ def melspectrogram(self, y: np.ndarray) -> np.ndarray:
+ """Compute a melspectrogram from a waveform."""
+ if self.preemphasis != 0:
+ D = self._stft(self.apply_preemphasis(y))
+ else:
+ D = self._stft(y)
+ if self.do_amp_to_db_mel:
+ S = self._amp_to_db(self._linear_to_mel(np.abs(D)))
+ else:
+ S = self._linear_to_mel(np.abs(D))
+ return self.normalize(S).astype(np.float32)
+
+ def inv_spectrogram(self, spectrogram: np.ndarray) -> np.ndarray:
+ """Convert a spectrogram to a waveform using Griffi-Lim vocoder."""
+ S = self.denormalize(spectrogram)
+ S = self._db_to_amp(S)
+ # Reconstruct phase
+ if self.preemphasis != 0:
+ return self.apply_inv_preemphasis(self._griffin_lim(S ** self.power))
+ return self._griffin_lim(S ** self.power)
+
+ def inv_melspectrogram(self, mel_spectrogram: np.ndarray) -> np.ndarray:
+ """Convert a melspectrogram to a waveform using Griffi-Lim vocoder."""
+ D = self.denormalize(mel_spectrogram)
+ S = self._db_to_amp(D)
+ S = self._mel_to_linear(S) # Convert back to linear
+ if self.preemphasis != 0:
+ return self.apply_inv_preemphasis(self._griffin_lim(S ** self.power))
+ return self._griffin_lim(S ** self.power)
+
+ def out_linear_to_mel(self, linear_spec: np.ndarray) -> np.ndarray:
+ """Convert a full scale linear spectrogram output of a network to a melspectrogram.
+
+ Args:
+ linear_spec (np.ndarray): Normalized full scale linear spectrogram.
+
+ Returns:
+ np.ndarray: Normalized melspectrogram.
+ """
+ S = self.denormalize(linear_spec)
+ S = self._db_to_amp(S)
+ S = self._linear_to_mel(np.abs(S))
+ S = self._amp_to_db(S)
+ mel = self.normalize(S)
+ return mel
+
+ ### STFT and ISTFT ###
+ def _stft(self, y: np.ndarray) -> np.ndarray:
+ """Librosa STFT wrapper.
+
+ Args:
+ y (np.ndarray): Audio signal.
+
+ Returns:
+ np.ndarray: Complex number array.
+ """
+ return librosa.stft(
+ y=y,
+ n_fft=self.fft_size,
+ hop_length=self.hop_length,
+ win_length=self.win_length,
+ pad_mode=self.stft_pad_mode,
+ window="hann",
+ center=True,
+ )
+
+ def _istft(self, y: np.ndarray) -> np.ndarray:
+ """Librosa iSTFT wrapper."""
+ return librosa.istft(y, hop_length=self.hop_length, win_length=self.win_length)
+
+ def _griffin_lim(self, S):
+ angles = np.exp(2j * np.pi * np.random.rand(*S.shape))
+ S_complex = np.abs(S).astype(np.complex)
+ y = self._istft(S_complex * angles)
+ if not np.isfinite(y).all():
+ print(" [!] Waveform is not finite everywhere. Skipping the GL.")
+ return np.array([0.0])
+ for _ in range(self.griffin_lim_iters):
+ angles = np.exp(1j * np.angle(self._stft(y)))
+ y = self._istft(S_complex * angles)
+ return y
+
+ def compute_stft_paddings(self, x, pad_sides=1):
+ """Compute paddings used by Librosa's STFT. Compute right padding (final frame) or both sides padding
+ (first and final frames)"""
+ assert pad_sides in (1, 2)
+ pad = (x.shape[0] // self.hop_length + 1) * self.hop_length - x.shape[0]
+ if pad_sides == 1:
+ return 0, pad
+ return pad // 2, pad // 2 + pad % 2
+
+ def compute_f0(self, x: np.ndarray) -> np.ndarray:
+ """Compute pitch (f0) of a waveform using the same parameters used for computing melspectrogram.
+
+ Args:
+ x (np.ndarray): Waveform.
+
+ Returns:
+ np.ndarray: Pitch.
+
+ Examples:
+ >>> WAV_FILE = filename = librosa.util.example_audio_file()
+ >>> from TTS.config import BaseAudioConfig
+ >>> from TTS.utils.audio import AudioProcessor
+ >>> conf = BaseAudioConfig(mel_fmax=8000)
+ >>> ap = AudioProcessor(**conf)
+ >>> wav = ap.load_wav(WAV_FILE, sr=22050)[:5 * 22050]
+ >>> pitch = ap.compute_f0(wav)
+ """
+ f0, t = pw.dio(
+ x.astype(np.double),
+ fs=self.sample_rate,
+ f0_ceil=self.mel_fmax,
+ frame_period=1000 * self.hop_length / self.sample_rate,
+ )
+ f0 = pw.stonemask(x.astype(np.double), f0, t, self.sample_rate)
+ # pad = int((self.win_length / self.hop_length) / 2)
+ # f0 = [0.0] * pad + f0 + [0.0] * pad
+ # f0 = np.pad(f0, (pad, pad), mode="constant", constant_values=0)
+ # f0 = np.array(f0, dtype=np.float32)
+
+ # f01, _, _ = librosa.pyin(
+ # x,
+ # fmin=65 if self.mel_fmin == 0 else self.mel_fmin,
+ # fmax=self.mel_fmax,
+ # frame_length=self.win_length,
+ # sr=self.sample_rate,
+ # fill_na=0.0,
+ # )
+
+ # spec = self.melspectrogram(x)
+ return f0
+
+ ### Audio Processing ###
+ def find_endpoint(self, wav: np.ndarray, threshold_db=-40, min_silence_sec=0.8) -> int:
+ """Find the last point without silence at the end of a audio signal.
+
+ Args:
+ wav (np.ndarray): Audio signal.
+ threshold_db (int, optional): Silence threshold in decibels. Defaults to -40.
+ min_silence_sec (float, optional): Ignore silences that are shorter then this in secs. Defaults to 0.8.
+
+ Returns:
+ int: Last point without silence.
+ """
+ window_length = int(self.sample_rate * min_silence_sec)
+ hop_length = int(window_length / 4)
+ threshold = self._db_to_amp(threshold_db)
+ for x in range(hop_length, len(wav) - window_length, hop_length):
+ if np.max(wav[x : x + window_length]) < threshold:
+ return x + hop_length
+ return len(wav)
+
+ def trim_silence(self, wav):
+ """Trim silent parts with a threshold and 0.01 sec margin"""
+ margin = int(self.sample_rate * 0.01)
+ wav = wav[margin:-margin]
+ return librosa.effects.trim(wav, top_db=self.trim_db, frame_length=self.win_length, hop_length=self.hop_length)[
+ 0
+ ]
+
+ @staticmethod
+ def sound_norm(x: np.ndarray) -> np.ndarray:
+ """Normalize the volume of an audio signal.
+
+ Args:
+ x (np.ndarray): Raw waveform.
+
+ Returns:
+ np.ndarray: Volume normalized waveform.
+ """
+ return x / abs(x).max() * 0.95
+
+ ### save and load ###
+ def load_wav(self, filename: str, sr: int = None) -> np.ndarray:
+ """Read a wav file using Librosa and optionally resample, silence trim, volume normalize.
+
+ Args:
+ filename (str): Path to the wav file.
+ sr (int, optional): Sampling rate for resampling. Defaults to None.
+
+ Returns:
+ np.ndarray: Loaded waveform.
+ """
+ if self.resample:
+ x, sr = librosa.load(filename, sr=self.sample_rate)
+ elif sr is None:
+ x, sr = sf.read(filename)
+ assert self.sample_rate == sr, "%s vs %s" % (self.sample_rate, sr)
+ else:
+ x, sr = librosa.load(filename, sr=sr)
+ if self.do_trim_silence:
+ try:
+ x = self.trim_silence(x)
+ except ValueError:
+ print(f" [!] File cannot be trimmed for silence - {filename}")
+ if self.do_sound_norm:
+ x = self.sound_norm(x)
+ return x
+
+ def save_wav(self, wav: np.ndarray, path: str, sr: int = None) -> None:
+ """Save a waveform to a file using Scipy.
+
+ Args:
+ wav (np.ndarray): Waveform to save.
+ path (str): Path to a output file.
+ sr (int, optional): Sampling rate used for saving to the file. Defaults to None.
+ """
+ wav_norm = wav * (32767 / max(0.01, np.max(np.abs(wav))))
+ scipy.io.wavfile.write(path, sr if sr else self.sample_rate, wav_norm.astype(np.int16))
+
+ @staticmethod
+ def mulaw_encode(wav: np.ndarray, qc: int) -> np.ndarray:
+ mu = 2 ** qc - 1
+ # wav_abs = np.minimum(np.abs(wav), 1.0)
+ signal = np.sign(wav) * np.log(1 + mu * np.abs(wav)) / np.log(1.0 + mu)
+ # Quantize signal to the specified number of levels.
+ signal = (signal + 1) / 2 * mu + 0.5
+ return np.floor(
+ signal,
+ )
+
+ @staticmethod
+ def mulaw_decode(wav, qc):
+ """Recovers waveform from quantized values."""
+ mu = 2 ** qc - 1
+ x = np.sign(wav) / mu * ((1 + mu) ** np.abs(wav) - 1)
+ return x
+
+ @staticmethod
+ def encode_16bits(x):
+ return np.clip(x * 2 ** 15, -(2 ** 15), 2 ** 15 - 1).astype(np.int16)
+
+ @staticmethod
+ def quantize(x: np.ndarray, bits: int) -> np.ndarray:
+ """Quantize a waveform to a given number of bits.
+
+ Args:
+ x (np.ndarray): Waveform to quantize. Must be normalized into the range `[-1, 1]`.
+ bits (int): Number of quantization bits.
+
+ Returns:
+ np.ndarray: Quantized waveform.
+ """
+ return (x + 1.0) * (2 ** bits - 1) / 2
+
+ @staticmethod
+ def dequantize(x, bits):
+ """Dequantize a waveform from the given number of bits."""
+ return 2 * x / (2 ** bits - 1) - 1
+
+
+def _log(x, base):
+ if base == 10:
+ return np.log10(x)
+ return np.log(x)
+
+
+def _exp(x, base):
+ if base == 10:
+ return np.power(10, x)
+ return np.exp(x)
diff --git a/speaker/utils/coqpit.py b/speaker/utils/coqpit.py
new file mode 100644
index 0000000..e214c8b
--- /dev/null
+++ b/speaker/utils/coqpit.py
@@ -0,0 +1,954 @@
+import argparse
+import functools
+import json
+import operator
+import os
+from collections.abc import MutableMapping
+from dataclasses import MISSING as _MISSING
+from dataclasses import Field, asdict, dataclass, fields, is_dataclass, replace
+from pathlib import Path
+from pprint import pprint
+from typing import Any, Dict, Generic, List, Optional, Type, TypeVar, Union, get_type_hints
+
+T = TypeVar("T")
+MISSING: Any = "???"
+
+
+class _NoDefault(Generic[T]):
+ pass
+
+
+NoDefaultVar = Union[_NoDefault[T], T]
+no_default: NoDefaultVar = _NoDefault()
+
+
+def is_primitive_type(arg_type: Any) -> bool:
+ """Check if the input type is one of `int, float, str, bool`.
+
+ Args:
+ arg_type (typing.Any): input type to check.
+
+ Returns:
+ bool: True if input type is one of `int, float, str, bool`.
+ """
+ try:
+ return isinstance(arg_type(), (int, float, str, bool))
+ except (AttributeError, TypeError):
+ return False
+
+
+def is_list(arg_type: Any) -> bool:
+ """Check if the input type is `list`
+
+ Args:
+ arg_type (typing.Any): input type.
+
+ Returns:
+ bool: True if input type is `list`
+ """
+ try:
+ return arg_type is list or arg_type is List or arg_type.__origin__ is list or arg_type.__origin__ is List
+ except AttributeError:
+ return False
+
+
+def is_dict(arg_type: Any) -> bool:
+ """Check if the input type is `dict`
+
+ Args:
+ arg_type (typing.Any): input type.
+
+ Returns:
+ bool: True if input type is `dict`
+ """
+ try:
+ return arg_type is dict or arg_type is Dict or arg_type.__origin__ is dict
+ except AttributeError:
+ return False
+
+
+def is_union(arg_type: Any) -> bool:
+ """Check if the input type is `Union`.
+
+ Args:
+ arg_type (typing.Any): input type.
+
+ Returns:
+ bool: True if input type is `Union`
+ """
+ try:
+ return safe_issubclass(arg_type.__origin__, Union)
+ except AttributeError:
+ return False
+
+
+def safe_issubclass(cls, classinfo) -> bool:
+ """Check if the input type is a subclass of the given class.
+
+ Args:
+ cls (type): input type.
+ classinfo (type): parent class.
+
+ Returns:
+ bool: True if the input type is a subclass of the given class
+ """
+ try:
+ r = issubclass(cls, classinfo)
+ except Exception: # pylint: disable=broad-except
+ return cls is classinfo
+ else:
+ return r
+
+
+def _coqpit_json_default(obj: Any) -> Any:
+ if isinstance(obj, Path):
+ return str(obj)
+ raise TypeError(f"Can't encode object of type {type(obj).__name__}")
+
+
+def _default_value(x: Field):
+ """Return the default value of the input Field.
+
+ Args:
+ x (Field): input Field.
+
+ Returns:
+ object: default value of the input Field.
+ """
+ if x.default not in (MISSING, _MISSING):
+ return x.default
+ if x.default_factory not in (MISSING, _MISSING):
+ return x.default_factory()
+ return x.default
+
+
+def _is_optional_field(field) -> bool:
+ """Check if the input field is optional.
+
+ Args:
+ field (Field): input Field to check.
+
+ Returns:
+ bool: True if the input field is optional.
+ """
+ # return isinstance(field.type, _GenericAlias) and type(None) in getattr(field.type, "__args__")
+ return type(None) in getattr(field.type, "__args__")
+
+
+def my_get_type_hints(
+ cls,
+):
+ """Custom `get_type_hints` dealing with https://github.com/python/typing/issues/737
+
+ Returns:
+ [dataclass]: dataclass to get the type hints of its fields.
+ """
+ r_dict = {}
+ for base in cls.__class__.__bases__:
+ if base == object:
+ break
+ r_dict.update(my_get_type_hints(base))
+ r_dict.update(get_type_hints(cls))
+ return r_dict
+
+
+def _serialize(x):
+ """Pick the right serialization for the datatype of the given input.
+
+ Args:
+ x (object): input object.
+
+ Returns:
+ object: serialized object.
+ """
+ if isinstance(x, Path):
+ return str(x)
+ if isinstance(x, dict):
+ return {k: _serialize(v) for k, v in x.items()}
+ if isinstance(x, list):
+ return [_serialize(xi) for xi in x]
+ if isinstance(x, Serializable) or issubclass(type(x), Serializable):
+ return x.serialize()
+ if isinstance(x, type) and issubclass(x, Serializable):
+ return x.serialize(x)
+ return x
+
+
+def _deserialize_dict(x: Dict) -> Dict:
+ """Deserialize dict.
+
+ Args:
+ x (Dict): value to deserialized.
+
+ Returns:
+ Dict: deserialized dictionary.
+ """
+ out_dict = {}
+ for k, v in x.items():
+ if v is None: # if {'key':None}
+ out_dict[k] = None
+ else:
+ out_dict[k] = _deserialize(v, type(v))
+ return out_dict
+
+
+def _deserialize_list(x: List, field_type: Type) -> List:
+ """Deserialize values for List typed fields.
+
+ Args:
+ x (List): value to be deserialized
+ field_type (Type): field type.
+
+ Raises:
+ ValueError: Coqpit does not support multi type-hinted lists.
+
+ Returns:
+ [List]: deserialized list.
+ """
+ field_args = None
+ if hasattr(field_type, "__args__") and field_type.__args__:
+ field_args = field_type.__args__
+ elif hasattr(field_type, "__parameters__") and field_type.__parameters__:
+ # bandaid for python 3.6
+ field_args = field_type.__parameters__
+ if field_args:
+ if len(field_args) > 1:
+ raise ValueError(" [!] Coqpit does not support multi-type hinted 'List'")
+ field_arg = field_args[0]
+ # if field type is TypeVar set the current type by the value's type.
+ if isinstance(field_arg, TypeVar):
+ field_arg = type(x)
+ return [_deserialize(xi, field_arg) for xi in x]
+ return x
+
+
+def _deserialize_union(x: Any, field_type: Type) -> Any:
+ """Deserialize values for Union typed fields
+
+ Args:
+ x (Any): value to be deserialized.
+ field_type (Type): field type.
+
+ Returns:
+ [Any]: desrialized value.
+ """
+ for arg in field_type.__args__:
+ # stop after first matching type in Union
+ try:
+ x = _deserialize(x, arg)
+ break
+ except ValueError:
+ pass
+ return x
+
+
+def _deserialize_primitive_types(x: Union[int, float, str, bool], field_type: Type) -> Union[int, float, str, bool]:
+ """Deserialize python primitive types (float, int, str, bool).
+ It handles `inf` values exclusively and keeps them float against int fields since int does not support inf values.
+
+ Args:
+ x (Union[int, float, str, bool]): value to be deserialized.
+ field_type (Type): field type.
+
+ Returns:
+ Union[int, float, str, bool]: deserialized value.
+ """
+
+ if isinstance(x, (str, bool)):
+ return x
+ if isinstance(x, (int, float)):
+ if x == float("inf") or x == float("-inf"):
+ # if value type is inf return regardless.
+ return x
+ x = field_type(x)
+ return x
+ # TODO: Raise an error when x does not match the types.
+ return None
+
+
+def _deserialize(x: Any, field_type: Any) -> Any:
+ """Pick the right desrialization for the given object and the corresponding field type.
+
+ Args:
+ x (object): object to be deserialized.
+ field_type (type): expected type after deserialization.
+
+ Returns:
+ object: deserialized object
+
+ """
+ # pylint: disable=too-many-return-statements
+ if is_dict(field_type):
+ return _deserialize_dict(x)
+ if is_list(field_type):
+ return _deserialize_list(x, field_type)
+ if is_union(field_type):
+ return _deserialize_union(x, field_type)
+ if issubclass(field_type, Serializable):
+ return field_type.deserialize_immutable(x)
+ if is_primitive_type(field_type):
+ return _deserialize_primitive_types(x, field_type)
+ raise ValueError(f" [!] '{type(x)}' value type of '{x}' does not match '{field_type}' field type.")
+
+
+# Recursive setattr (supports dotted attr names)
+def rsetattr(obj, attr, val):
+ def _setitem(obj, attr, val):
+ return operator.setitem(obj, int(attr), val)
+
+ pre, _, post = attr.rpartition(".")
+ setfunc = _setitem if post.isnumeric() else setattr
+
+ return setfunc(rgetattr(obj, pre) if pre else obj, post, val)
+
+
+# Recursive getattr (supports dotted attr names)
+def rgetattr(obj, attr, *args):
+ def _getitem(obj, attr):
+ return operator.getitem(obj, int(attr), *args)
+
+ def _getattr(obj, attr):
+ getfunc = _getitem if attr.isnumeric() else getattr
+ return getfunc(obj, attr, *args)
+
+ return functools.reduce(_getattr, [obj] + attr.split("."))
+
+
+# Recursive setitem (supports dotted attr names)
+def rsetitem(obj, attr, val):
+ pre, _, post = attr.rpartition(".")
+ return operator.setitem(rgetitem(obj, pre) if pre else obj, post, val)
+
+
+# Recursive getitem (supports dotted attr names)
+def rgetitem(obj, attr, *args):
+ def _getitem(obj, attr):
+ return operator.getitem(obj, int(attr) if attr.isnumeric() else attr, *args)
+
+ return functools.reduce(_getitem, [obj] + attr.split("."))
+
+
+@dataclass
+class Serializable:
+ """Gives serialization ability to any inheriting dataclass."""
+
+ def __post_init__(self):
+ self._validate_contracts()
+ for key, value in self.__dict__.items():
+ if value is no_default:
+ raise TypeError(f"__init__ missing 1 required argument: '{key}'")
+
+ def _validate_contracts(self):
+ dataclass_fields = fields(self)
+
+ for field in dataclass_fields:
+
+ value = getattr(self, field.name)
+
+ if value is None:
+ if not _is_optional_field(field):
+ raise TypeError(f"{field.name} is not optional")
+
+ contract = field.metadata.get("contract", None)
+
+ if contract is not None:
+ if value is not None and not contract(value):
+ raise ValueError(f"break the contract for {field.name}, {self.__class__.__name__}")
+
+ def validate(self):
+ """validate if object can serialize / deserialize correctly."""
+ self._validate_contracts()
+ if self != self.__class__.deserialize( # pylint: disable=no-value-for-parameter
+ json.loads(json.dumps(self.serialize()))
+ ):
+ raise ValueError("could not be deserialized with same value")
+
+ def to_dict(self) -> dict:
+ """Transform serializable object to dict."""
+ cls_fields = fields(self)
+ o = {}
+ for cls_field in cls_fields:
+ o[cls_field.name] = getattr(self, cls_field.name)
+ return o
+
+ def serialize(self) -> dict:
+ """Serialize object to be json serializable representation."""
+ if not is_dataclass(self):
+ raise TypeError("need to be decorated as dataclass")
+
+ dataclass_fields = fields(self)
+
+ o = {}
+
+ for field in dataclass_fields:
+ value = getattr(self, field.name)
+ value = _serialize(value)
+ o[field.name] = value
+ return o
+
+ def deserialize(self, data: dict) -> "Serializable":
+ """Parse input dictionary and desrialize its fields to a dataclass.
+
+ Returns:
+ self: deserialized `self`.
+ """
+ if not isinstance(data, dict):
+ raise ValueError()
+ data = data.copy()
+ init_kwargs = {}
+ for field in fields(self):
+ # if field.name == 'dataset_config':
+ if field.name not in data:
+ if field.name in vars(self):
+ init_kwargs[field.name] = vars(self)[field.name]
+ continue
+ raise ValueError(f' [!] Missing required field "{field.name}"')
+ value = data.get(field.name, _default_value(field))
+ if value is None:
+ init_kwargs[field.name] = value
+ continue
+ if value == MISSING:
+ raise ValueError(f"deserialized with unknown value for {field.name} in {self.__name__}")
+ value = _deserialize(value, field.type)
+ init_kwargs[field.name] = value
+ for k, v in init_kwargs.items():
+ setattr(self, k, v)
+ return self
+
+ @classmethod
+ def deserialize_immutable(cls, data: dict) -> "Serializable":
+ """Parse input dictionary and desrialize its fields to a dataclass.
+
+ Returns:
+ Newly created deserialized object.
+ """
+ if not isinstance(data, dict):
+ raise ValueError()
+ data = data.copy()
+ init_kwargs = {}
+ for field in fields(cls):
+ # if field.name == 'dataset_config':
+ if field.name not in data:
+ if field.name in vars(cls):
+ init_kwargs[field.name] = vars(cls)[field.name]
+ continue
+ # if not in cls and the default value is not Missing use it
+ default_value = _default_value(field)
+ if default_value not in (MISSING, _MISSING):
+ init_kwargs[field.name] = default_value
+ continue
+ raise ValueError(f' [!] Missing required field "{field.name}"')
+ value = data.get(field.name, _default_value(field))
+ if value is None:
+ init_kwargs[field.name] = value
+ continue
+ if value == MISSING:
+ raise ValueError(f"Deserialized with unknown value for {field.name} in {cls.__name__}")
+ value = _deserialize(value, field.type)
+ init_kwargs[field.name] = value
+ return cls(**init_kwargs)
+
+
+# ---------------------------------------------------------------------------- #
+# Argument Parsing from `argparse` #
+# ---------------------------------------------------------------------------- #
+
+
+def _get_help(field):
+ try:
+ field_help = field.metadata["help"]
+ except KeyError:
+ field_help = ""
+ return field_help
+
+
+def _init_argparse(
+ parser,
+ field_name,
+ field_type,
+ field_default,
+ field_default_factory,
+ field_help,
+ arg_prefix="",
+ help_prefix="",
+ relaxed_parser=False,
+):
+ has_default = False
+ default = None
+ if field_default:
+ has_default = True
+ default = field_default
+ elif field_default_factory not in (None, _MISSING):
+ has_default = True
+ default = field_default_factory()
+
+ if not has_default and not is_primitive_type(field_type) and not is_list(field_type):
+ # aggregate types (fields with a Coqpit subclass as type) are not supported without None
+ return parser
+ arg_prefix = field_name if arg_prefix == "" else f"{arg_prefix}.{field_name}"
+ help_prefix = field_help if help_prefix == "" else f"{help_prefix} - {field_help}"
+ if is_dict(field_type): # pylint: disable=no-else-raise
+ # NOTE: accept any string in json format as input to dict field.
+ parser.add_argument(
+ f"--{arg_prefix}",
+ dest=arg_prefix,
+ default=json.dumps(field_default) if field_default else None,
+ type=json.loads,
+ )
+ elif is_list(field_type):
+ # TODO: We need a more clear help msg for lists.
+ if hasattr(field_type, "__args__"): # if the list is hinted
+ if len(field_type.__args__) > 1 and not relaxed_parser:
+ raise ValueError(" [!] Coqpit does not support multi-type hinted 'List'")
+ list_field_type = field_type.__args__[0]
+ else:
+ raise ValueError(" [!] Coqpit does not support un-hinted 'List'")
+
+ # TODO: handle list of lists
+ if is_list(list_field_type) and relaxed_parser:
+ return parser
+
+ if not has_default or field_default_factory is list:
+ if not is_primitive_type(list_field_type) and not relaxed_parser:
+ raise NotImplementedError(" [!] Empty list with non primitive inner type is currently not supported.")
+
+ # If the list's default value is None, the user can specify the entire list by passing multiple parameters
+ parser.add_argument(
+ f"--{arg_prefix}",
+ nargs="*",
+ type=list_field_type,
+ help=f"Coqpit Field: {help_prefix}",
+ )
+ else:
+ # If a default value is defined, just enable editing the values from argparse
+ # TODO: allow inserting a new value/obj to the end of the list.
+ for idx, fv in enumerate(default):
+ parser = _init_argparse(
+ parser,
+ str(idx),
+ list_field_type,
+ fv,
+ field_default_factory,
+ field_help="",
+ help_prefix=f"{help_prefix} - ",
+ arg_prefix=f"{arg_prefix}",
+ relaxed_parser=relaxed_parser,
+ )
+ elif is_union(field_type):
+ # TODO: currently I don't know how to handle Union type on argparse
+ if not relaxed_parser:
+ raise NotImplementedError(
+ " [!] Parsing `Union` field from argparse is not yet implemented. Please create an issue."
+ )
+ elif issubclass(field_type, Serializable):
+ return default.init_argparse(
+ parser, arg_prefix=arg_prefix, help_prefix=help_prefix, relaxed_parser=relaxed_parser
+ )
+ elif isinstance(field_type(), bool):
+
+ def parse_bool(x):
+ if x not in ("true", "false"):
+ raise ValueError(f' [!] Value for boolean field must be either "true" or "false". Got "{x}".')
+ return x == "true"
+
+ parser.add_argument(
+ f"--{arg_prefix}",
+ type=parse_bool,
+ default=field_default,
+ help=f"Coqpit Field: {help_prefix}",
+ metavar="true/false",
+ )
+ elif is_primitive_type(field_type):
+ parser.add_argument(
+ f"--{arg_prefix}",
+ default=field_default,
+ type=field_type,
+ help=f"Coqpit Field: {help_prefix}",
+ )
+ else:
+ if not relaxed_parser:
+ raise NotImplementedError(f" [!] '{field_type}' is not supported by arg_parser. Please file a bug report.")
+ return parser
+
+
+# ---------------------------------------------------------------------------- #
+# Main Coqpit Class #
+# ---------------------------------------------------------------------------- #
+
+
+@dataclass
+class Coqpit(Serializable, MutableMapping):
+ """Coqpit base class to be inherited by any Coqpit dataclasses.
+ It overrides Python `dict` interface and provides `dict` compatible API.
+ It also enables serializing/deserializing a dataclass to/from a json file, plus some semi-dynamic type and value check.
+ Note that it does not support all datatypes and likely to fail in some cases.
+ """
+
+ _initialized = False
+
+ def _is_initialized(self):
+ """Check if Coqpit is initialized. Useful to prevent running some aux functions
+ at the initialization when no attribute has been defined."""
+ return "_initialized" in vars(self) and self._initialized
+
+ def __post_init__(self):
+ self._initialized = True
+ try:
+ self.check_values()
+ except AttributeError:
+ pass
+
+ ## `dict` API functions
+
+ def __iter__(self):
+ return iter(asdict(self))
+
+ def __len__(self):
+ return len(fields(self))
+
+ def __setitem__(self, arg: str, value: Any):
+ setattr(self, arg, value)
+
+ def __getitem__(self, arg: str):
+ """Access class attributes with ``[arg]``."""
+ return self.__dict__[arg]
+
+ def __delitem__(self, arg: str):
+ delattr(self, arg)
+
+ def _keytransform(self, key): # pylint: disable=no-self-use
+ return key
+
+ ## end `dict` API functions
+
+ def __getattribute__(self, arg: str): # pylint: disable=no-self-use
+ """Check if the mandatory field is defined when accessing it."""
+ value = super().__getattribute__(arg)
+ if isinstance(value, str) and value == "???":
+ raise AttributeError(f" [!] MISSING field {arg} must be defined.")
+ return value
+
+ def __contains__(self, arg: str):
+ return arg in self.to_dict()
+
+ def get(self, key: str, default: Any = None):
+ if self.has(key):
+ return asdict(self)[key]
+ return default
+
+ def items(self):
+ return asdict(self).items()
+
+ def merge(self, coqpits: Union["Coqpit", List["Coqpit"]]):
+ """Merge a coqpit instance or a list of coqpit instances to self.
+ Note that it does not pass the fields and overrides attributes with
+ the last Coqpit instance in the given List.
+ TODO: find a way to merge instances with all the class internals.
+
+ Args:
+ coqpits (Union[Coqpit, List[Coqpit]]): coqpit instance or list of instances to be merged.
+ """
+
+ def _merge(coqpit):
+ self.__dict__.update(coqpit.__dict__)
+ self.__annotations__.update(coqpit.__annotations__)
+ self.__dataclass_fields__.update(coqpit.__dataclass_fields__)
+
+ if isinstance(coqpits, list):
+ for coqpit in coqpits:
+ _merge(coqpit)
+ else:
+ _merge(coqpits)
+
+ def check_values(self):
+ pass
+
+ def has(self, arg: str) -> bool:
+ return arg in vars(self)
+
+ def copy(self):
+ return replace(self)
+
+ def update(self, new: dict, allow_new=False) -> None:
+ """Update Coqpit fields by the input ```dict```.
+
+ Args:
+ new (dict): dictionary with new values.
+ allow_new (bool, optional): allow new fields to add. Defaults to False.
+ """
+ for key, value in new.items():
+ if allow_new:
+ setattr(self, key, value)
+ else:
+ if hasattr(self, key):
+ setattr(self, key, value)
+ else:
+ raise KeyError(f" [!] No key - {key}")
+
+ def pprint(self) -> None:
+ """Print Coqpit fields in a format."""
+ pprint(asdict(self))
+
+ def to_dict(self) -> dict:
+ # return asdict(self)
+ return self.serialize()
+
+ def from_dict(self, data: dict) -> None:
+ self = self.deserialize(data) # pylint: disable=self-cls-assignment
+
+ @classmethod
+ def new_from_dict(cls: Serializable, data: dict) -> "Coqpit":
+ return cls.deserialize_immutable(data)
+
+ def to_json(self) -> str:
+ """Returns a JSON string representation."""
+ return json.dumps(asdict(self), indent=4, default=_coqpit_json_default)
+
+ def save_json(self, file_name: str) -> None:
+ """Save Coqpit to a json file.
+
+ Args:
+ file_name (str): path to the output json file.
+ """
+ with open(file_name, "w", encoding="utf8") as f:
+ json.dump(asdict(self), f, indent=4)
+
+ def load_json(self, file_name: str) -> None:
+ """Load a json file and update matching config fields with type checking.
+ Non-matching parameters in the json file are ignored.
+
+ Args:
+ file_name (str): path to the json file.
+
+ Returns:
+ Coqpit: new Coqpit with updated config fields.
+ """
+ with open(file_name, "r", encoding="utf8") as f:
+ input_str = f.read()
+ dump_dict = json.loads(input_str)
+ # TODO: this looks stupid 💆
+ self = self.deserialize(dump_dict) # pylint: disable=self-cls-assignment
+ self.check_values()
+
+ @classmethod
+ def init_from_argparse(
+ cls, args: Optional[Union[argparse.Namespace, List[str]]] = None, arg_prefix: str = "coqpit"
+ ) -> "Coqpit":
+ """Create a new Coqpit instance from argparse input.
+
+ Args:
+ args (namespace or list of str, optional): parsed argparse.Namespace or list of command line parameters. If unspecified will use a newly created parser with ```init_argparse()```.
+ arg_prefix: prefix to add to CLI parameters. Gets forwarded to ```init_argparse``` when ```args``` is not passed.
+ """
+ if not args:
+ # If args was not specified, parse from sys.argv
+ parser = cls.init_argparse(cls, arg_prefix=arg_prefix)
+ args = parser.parse_args() # pylint: disable=E1120, E1111
+ if isinstance(args, list):
+ # If a list was passed in (eg. the second result of `parse_known_args`, run that through argparse first to get a parsed Namespace
+ parser = cls.init_argparse(cls, arg_prefix=arg_prefix)
+ args = parser.parse_args(args) # pylint: disable=E1120, E1111
+
+ # Handle list and object attributes with defaults, which can be modified
+ # directly (eg. --coqpit.list.0.val_a 1), by constructing real objects
+ # from defaults and passing those to `cls.__init__`
+ args_with_lists_processed = {}
+ class_fields = fields(cls)
+ for field in class_fields:
+ has_default = False
+ default = None
+ field_default = field.default if field.default is not _MISSING else None
+ field_default_factory = field.default_factory if field.default_factory is not _MISSING else None
+ if field_default:
+ has_default = True
+ default = field_default
+ elif field_default_factory:
+ has_default = True
+ default = field_default_factory()
+
+ if has_default and (not is_primitive_type(field.type) or is_list(field.type)):
+ args_with_lists_processed[field.name] = default
+
+ args_dict = vars(args)
+ for k, v in args_dict.items():
+ # Remove argparse prefix (eg. "--coqpit." if present)
+ if k.startswith(f"{arg_prefix}."):
+ k = k[len(f"{arg_prefix}.") :]
+
+ rsetitem(args_with_lists_processed, k, v)
+
+ return cls(**args_with_lists_processed)
+
+ def parse_args(
+ self, args: Optional[Union[argparse.Namespace, List[str]]] = None, arg_prefix: str = "coqpit"
+ ) -> None:
+ """Update config values from argparse arguments with some meta-programming ✨.
+
+ Args:
+ args (namespace or list of str, optional): parsed argparse.Namespace or list of command line parameters. If unspecified will use a newly created parser with ```init_argparse()```.
+ arg_prefix: prefix to add to CLI parameters. Gets forwarded to ```init_argparse``` when ```args``` is not passed.
+ """
+ if not args:
+ # If args was not specified, parse from sys.argv
+ parser = self.init_argparse(arg_prefix=arg_prefix)
+ args = parser.parse_args()
+ if isinstance(args, list):
+ # If a list was passed in (eg. the second result of `parse_known_args`, run that through argparse first to get a parsed Namespace
+ parser = self.init_argparse(arg_prefix=arg_prefix)
+ args = parser.parse_args(args)
+
+ args_dict = vars(args)
+
+ for k, v in args_dict.items():
+ if k.startswith(f"{arg_prefix}."):
+ k = k[len(f"{arg_prefix}.") :]
+ try:
+ rgetattr(self, k)
+ except (TypeError, AttributeError) as e:
+ raise Exception(f" [!] '{k}' not exist to override from argparse.") from e
+
+ rsetattr(self, k, v)
+
+ self.check_values()
+
+ def parse_known_args(
+ self,
+ args: Optional[Union[argparse.Namespace, List[str]]] = None,
+ arg_prefix: str = "coqpit",
+ relaxed_parser=False,
+ ) -> List[str]:
+ """Update config values from argparse arguments. Ignore unknown arguments.
+ This is analog to argparse.ArgumentParser.parse_known_args (vs parse_args).
+
+ Args:
+ args (namespace or list of str, optional): parsed argparse.Namespace or list of command line parameters. If unspecified will use a newly created parser with ```init_argparse()```.
+ arg_prefix: prefix to add to CLI parameters. Gets forwarded to ```init_argparse``` when ```args``` is not passed.
+ relaxed_parser (bool, optional): If True, do not force all the fields to have compatible types with the argparser. Defaults to False.
+
+ Returns:
+ List of unknown parameters.
+ """
+ if not args:
+ # If args was not specified, parse from sys.argv
+ parser = self.init_argparse(arg_prefix=arg_prefix, relaxed_parser=relaxed_parser)
+ args, unknown = parser.parse_known_args()
+ if isinstance(args, list):
+ # If a list was passed in (eg. the second result of `parse_known_args`, run that through argparse first to get a parsed Namespace
+ parser = self.init_argparse(arg_prefix=arg_prefix, relaxed_parser=relaxed_parser)
+ args, unknown = parser.parse_known_args(args)
+
+ self.parse_args(args)
+ return unknown
+
+ def init_argparse(
+ self,
+ parser: Optional[argparse.ArgumentParser] = None,
+ arg_prefix="coqpit",
+ help_prefix="",
+ relaxed_parser=False,
+ ) -> argparse.ArgumentParser:
+ """Pass Coqpit fields as argparse arguments. This allows to edit values through command-line.
+
+ Args:
+ parser (argparse.ArgumentParser, optional): argparse.ArgumentParser instance. If unspecified a new one will be created.
+ arg_prefix (str, optional): Prefix to be used for the argument name. Defaults to 'coqpit'.
+ help_prefix (str, optional): Prefix to be used for the argument description. Defaults to ''.
+ relaxed_parser (bool, optional): If True, do not force all the fields to have compatible types with the argparser. Defaults to False.
+
+ Returns:
+ argparse.ArgumentParser: parser instance with the new arguments.
+ """
+ if not parser:
+ parser = argparse.ArgumentParser()
+ class_fields = fields(self)
+ for field in class_fields:
+ if field.name in vars(self):
+ # use the current value of the field
+ # prevent dropping the current value
+ field_default = vars(self)[field.name]
+ else:
+ # use the default value of the field
+ field_default = field.default if field.default is not _MISSING else None
+ field_type = field.type
+ field_default_factory = field.default_factory
+ field_help = _get_help(field)
+ _init_argparse(
+ parser,
+ field.name,
+ field_type,
+ field_default,
+ field_default_factory,
+ field_help,
+ arg_prefix,
+ help_prefix,
+ relaxed_parser,
+ )
+ return parser
+
+
+def check_argument(
+ name,
+ c,
+ is_path: bool = False,
+ prerequest: str = None,
+ enum_list: list = None,
+ max_val: float = None,
+ min_val: float = None,
+ restricted: bool = False,
+ alternative: str = None,
+ allow_none: bool = True,
+) -> None:
+ """Simple type and value checking for Coqpit.
+ It is intended to be used under ```__post_init__()``` of config dataclasses.
+
+ Args:
+ name (str): name of the field to be checked.
+ c (dict): config dictionary.
+ is_path (bool, optional): if ```True``` check if the path is exist. Defaults to False.
+ prerequest (list or str, optional): a list of field name that are prerequestedby the target field name.
+ Defaults to ```[]```.
+ enum_list (list, optional): list of possible values for the target field. Defaults to None.
+ max_val (float, optional): maximum possible value for the target field. Defaults to None.
+ min_val (float, optional): minimum possible value for the target field. Defaults to None.
+ restricted (bool, optional): if ```True``` the target field has to be defined. Defaults to False.
+ alternative (str, optional): a field name superceding the target field. Defaults to None.
+ allow_none (bool, optional): if ```True``` allow the target field to be ```None```. Defaults to False.
+
+
+ Example:
+ >>> num_mels = 5
+ >>> check_argument('num_mels', c, restricted=True, min_val=10, max_val=2056)
+ >>> fft_size = 128
+ >>> check_argument('fft_size', c, restricted=True, min_val=128, max_val=4058)
+ """
+ # check if None allowed
+ if allow_none and c[name] is None:
+ return
+ if not allow_none:
+ assert c[name] is not None, f" [!] None value is not allowed for {name}."
+ # check if restricted and it it is check if it exists
+ if isinstance(restricted, bool) and restricted:
+ assert name in c.keys(), f" [!] {name} not defined in config.json"
+ # check prerequest fields are defined
+ if isinstance(prerequest, list):
+ assert any(
+ f not in c.keys() for f in prerequest
+ ), f" [!] prequested fields {prerequest} for {name} are not defined."
+ else:
+ assert (
+ prerequest is None or prerequest in c.keys()
+ ), f" [!] prequested fields {prerequest} for {name} are not defined."
+ # check if the path exists
+ if is_path:
+ assert os.path.exists(c[name]), f' [!] path for {name} ("{c[name]}") does not exist.'
+ # skip the rest if the alternative field is defined.
+ if alternative in c.keys() and c[alternative] is not None:
+ return
+ # check value constraints
+ if name in c.keys():
+ if max_val is not None:
+ assert c[name] <= max_val, f" [!] {name} is larger than max value {max_val}"
+ if min_val is not None:
+ assert c[name] >= min_val, f" [!] {name} is smaller than min value {min_val}"
+ if enum_list is not None:
+ assert c[name].lower() in enum_list, f" [!] {name} is not a valid value"
diff --git a/speaker/utils/io.py b/speaker/utils/io.py
new file mode 100644
index 0000000..1d4c079
--- /dev/null
+++ b/speaker/utils/io.py
@@ -0,0 +1,198 @@
+import datetime
+import json
+import os
+import pickle as pickle_tts
+import shutil
+from typing import Any, Callable, Dict, Union
+
+import fsspec
+import torch
+from .coqpit import Coqpit
+
+
+class RenamingUnpickler(pickle_tts.Unpickler):
+ """Overload default pickler to solve module renaming problem"""
+
+ def find_class(self, module, name):
+ return super().find_class(module.replace("mozilla_voice_tts", "TTS"), name)
+
+
+class AttrDict(dict):
+ """A custom dict which converts dict keys
+ to class attributes"""
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.__dict__ = self
+
+
+def copy_model_files(config: Coqpit, out_path, new_fields):
+ """Copy config.json and other model files to training folder and add
+ new fields.
+
+ Args:
+ config (Coqpit): Coqpit config defining the training run.
+ out_path (str): output path to copy the file.
+ new_fields (dict): new fileds to be added or edited
+ in the config file.
+ """
+ copy_config_path = os.path.join(out_path, "config.json")
+ # add extra information fields
+ config.update(new_fields, allow_new=True)
+ # TODO: Revert to config.save_json() once Coqpit supports arbitrary paths.
+ with fsspec.open(copy_config_path, "w", encoding="utf8") as f:
+ json.dump(config.to_dict(), f, indent=4)
+
+ # copy model stats file if available
+ if config.audio.stats_path is not None:
+ copy_stats_path = os.path.join(out_path, "scale_stats.npy")
+ filesystem = fsspec.get_mapper(copy_stats_path).fs
+ if not filesystem.exists(copy_stats_path):
+ with fsspec.open(config.audio.stats_path, "rb") as source_file:
+ with fsspec.open(copy_stats_path, "wb") as target_file:
+ shutil.copyfileobj(source_file, target_file)
+
+
+def load_fsspec(
+ path: str,
+ map_location: Union[str, Callable, torch.device, Dict[Union[str, torch.device], Union[str, torch.device]]] = None,
+ **kwargs,
+) -> Any:
+ """Like torch.load but can load from other locations (e.g. s3:// , gs://).
+
+ Args:
+ path: Any path or url supported by fsspec.
+ map_location: torch.device or str.
+ **kwargs: Keyword arguments forwarded to torch.load.
+
+ Returns:
+ Object stored in path.
+ """
+ with fsspec.open(path, "rb") as f:
+ return torch.load(f, map_location=map_location, **kwargs)
+
+
+def load_checkpoint(model, checkpoint_path, use_cuda=False, eval=False): # pylint: disable=redefined-builtin
+ try:
+ state = load_fsspec(checkpoint_path, map_location=torch.device("cpu"))
+ except ModuleNotFoundError:
+ pickle_tts.Unpickler = RenamingUnpickler
+ state = load_fsspec(checkpoint_path, map_location=torch.device("cpu"), pickle_module=pickle_tts)
+ model.load_state_dict(state["model"])
+ if use_cuda:
+ model.cuda()
+ if eval:
+ model.eval()
+ return model, state
+
+
+def save_fsspec(state: Any, path: str, **kwargs):
+ """Like torch.save but can save to other locations (e.g. s3:// , gs://).
+
+ Args:
+ state: State object to save
+ path: Any path or url supported by fsspec.
+ **kwargs: Keyword arguments forwarded to torch.save.
+ """
+ with fsspec.open(path, "wb") as f:
+ torch.save(state, f, **kwargs)
+
+
+def save_model(config, model, optimizer, scaler, current_step, epoch, output_path, **kwargs):
+ if hasattr(model, "module"):
+ model_state = model.module.state_dict()
+ else:
+ model_state = model.state_dict()
+ if isinstance(optimizer, list):
+ optimizer_state = [optim.state_dict() for optim in optimizer]
+ else:
+ optimizer_state = optimizer.state_dict() if optimizer is not None else None
+
+ if isinstance(scaler, list):
+ scaler_state = [s.state_dict() for s in scaler]
+ else:
+ scaler_state = scaler.state_dict() if scaler is not None else None
+
+ if isinstance(config, Coqpit):
+ config = config.to_dict()
+
+ state = {
+ "config": config,
+ "model": model_state,
+ "optimizer": optimizer_state,
+ "scaler": scaler_state,
+ "step": current_step,
+ "epoch": epoch,
+ "date": datetime.date.today().strftime("%B %d, %Y"),
+ }
+ state.update(kwargs)
+ save_fsspec(state, output_path)
+
+
+def save_checkpoint(
+ config,
+ model,
+ optimizer,
+ scaler,
+ current_step,
+ epoch,
+ output_folder,
+ **kwargs,
+):
+ file_name = "checkpoint_{}.pth.tar".format(current_step)
+ checkpoint_path = os.path.join(output_folder, file_name)
+ print("\n > CHECKPOINT : {}".format(checkpoint_path))
+ save_model(
+ config,
+ model,
+ optimizer,
+ scaler,
+ current_step,
+ epoch,
+ checkpoint_path,
+ **kwargs,
+ )
+
+
+def save_best_model(
+ current_loss,
+ best_loss,
+ config,
+ model,
+ optimizer,
+ scaler,
+ current_step,
+ epoch,
+ out_path,
+ keep_all_best=False,
+ keep_after=10000,
+ **kwargs,
+):
+ if current_loss < best_loss:
+ best_model_name = f"best_model_{current_step}.pth.tar"
+ checkpoint_path = os.path.join(out_path, best_model_name)
+ print(" > BEST MODEL : {}".format(checkpoint_path))
+ save_model(
+ config,
+ model,
+ optimizer,
+ scaler,
+ current_step,
+ epoch,
+ checkpoint_path,
+ model_loss=current_loss,
+ **kwargs,
+ )
+ fs = fsspec.get_mapper(out_path).fs
+ # only delete previous if current is saved successfully
+ if not keep_all_best or (current_step < keep_after):
+ model_names = fs.glob(os.path.join(out_path, "best_model*.pth.tar"))
+ for model_name in model_names:
+ if os.path.basename(model_name) != best_model_name:
+ fs.rm(model_name)
+ # create a shortcut which always points to the currently best model
+ shortcut_name = "best_model.pth.tar"
+ shortcut_path = os.path.join(out_path, shortcut_name)
+ fs.copy(checkpoint_path, shortcut_path)
+ best_loss = current_loss
+ return best_loss
diff --git a/speaker/utils/shared_configs.py b/speaker/utils/shared_configs.py
new file mode 100644
index 0000000..a89d3a9
--- /dev/null
+++ b/speaker/utils/shared_configs.py
@@ -0,0 +1,342 @@
+from dataclasses import asdict, dataclass
+from typing import List
+
+from .coqpit import Coqpit, check_argument
+
+
+@dataclass
+class BaseAudioConfig(Coqpit):
+ """Base config to definge audio processing parameters. It is used to initialize
+ ```TTS.utils.audio.AudioProcessor.```
+
+ Args:
+ fft_size (int):
+ Number of STFT frequency levels aka.size of the linear spectogram frame. Defaults to 1024.
+
+ win_length (int):
+ Each frame of audio is windowed by window of length ```win_length``` and then padded with zeros to match
+ ```fft_size```. Defaults to 1024.
+
+ hop_length (int):
+ Number of audio samples between adjacent STFT columns. Defaults to 1024.
+
+ frame_shift_ms (int):
+ Set ```hop_length``` based on milliseconds and sampling rate.
+
+ frame_length_ms (int):
+ Set ```win_length``` based on milliseconds and sampling rate.
+
+ stft_pad_mode (str):
+ Padding method used in STFT. 'reflect' or 'center'. Defaults to 'reflect'.
+
+ sample_rate (int):
+ Audio sampling rate. Defaults to 22050.
+
+ resample (bool):
+ Enable / Disable resampling audio to ```sample_rate```. Defaults to ```False```.
+
+ preemphasis (float):
+ Preemphasis coefficient. Defaults to 0.0.
+
+ ref_level_db (int): 20
+ Reference Db level to rebase the audio signal and ignore the level below. 20Db is assumed the sound of air.
+ Defaults to 20.
+
+ do_sound_norm (bool):
+ Enable / Disable sound normalization to reconcile the volume differences among samples. Defaults to False.
+
+ log_func (str):
+ Numpy log function used for amplitude to DB conversion. Defaults to 'np.log10'.
+
+ do_trim_silence (bool):
+ Enable / Disable trimming silences at the beginning and the end of the audio clip. Defaults to ```True```.
+
+ do_amp_to_db_linear (bool, optional):
+ enable/disable amplitude to dB conversion of linear spectrograms. Defaults to True.
+
+ do_amp_to_db_mel (bool, optional):
+ enable/disable amplitude to dB conversion of mel spectrograms. Defaults to True.
+
+ trim_db (int):
+ Silence threshold used for silence trimming. Defaults to 45.
+
+ power (float):
+ Exponent used for expanding spectrogra levels before running Griffin Lim. It helps to reduce the
+ artifacts in the synthesized voice. Defaults to 1.5.
+
+ griffin_lim_iters (int):
+ Number of Griffing Lim iterations. Defaults to 60.
+
+ num_mels (int):
+ Number of mel-basis frames that defines the frame lengths of each mel-spectrogram frame. Defaults to 80.
+
+ mel_fmin (float): Min frequency level used for the mel-basis filters. ~50 for male and ~95 for female voices.
+ It needs to be adjusted for a dataset. Defaults to 0.
+
+ mel_fmax (float):
+ Max frequency level used for the mel-basis filters. It needs to be adjusted for a dataset.
+
+ spec_gain (int):
+ Gain applied when converting amplitude to DB. Defaults to 20.
+
+ signal_norm (bool):
+ enable/disable signal normalization. Defaults to True.
+
+ min_level_db (int):
+ minimum db threshold for the computed melspectrograms. Defaults to -100.
+
+ symmetric_norm (bool):
+ enable/disable symmetric normalization. If set True normalization is performed in the range [-k, k] else
+ [0, k], Defaults to True.
+
+ max_norm (float):
+ ```k``` defining the normalization range. Defaults to 4.0.
+
+ clip_norm (bool):
+ enable/disable clipping the our of range values in the normalized audio signal. Defaults to True.
+
+ stats_path (str):
+ Path to the computed stats file. Defaults to None.
+ """
+
+ # stft parameters
+ fft_size: int = 1024
+ win_length: int = 1024
+ hop_length: int = 256
+ frame_shift_ms: int = None
+ frame_length_ms: int = None
+ stft_pad_mode: str = "reflect"
+ # audio processing parameters
+ sample_rate: int = 22050
+ resample: bool = False
+ preemphasis: float = 0.0
+ ref_level_db: int = 20
+ do_sound_norm: bool = False
+ log_func: str = "np.log10"
+ # silence trimming
+ do_trim_silence: bool = True
+ trim_db: int = 45
+ # griffin-lim params
+ power: float = 1.5
+ griffin_lim_iters: int = 60
+ # mel-spec params
+ num_mels: int = 80
+ mel_fmin: float = 0.0
+ mel_fmax: float = None
+ spec_gain: int = 20
+ do_amp_to_db_linear: bool = True
+ do_amp_to_db_mel: bool = True
+ # normalization params
+ signal_norm: bool = True
+ min_level_db: int = -100
+ symmetric_norm: bool = True
+ max_norm: float = 4.0
+ clip_norm: bool = True
+ stats_path: str = None
+
+ def check_values(
+ self,
+ ):
+ """Check config fields"""
+ c = asdict(self)
+ check_argument("num_mels", c, restricted=True, min_val=10, max_val=2056)
+ check_argument("fft_size", c, restricted=True, min_val=128, max_val=4058)
+ check_argument("sample_rate", c, restricted=True, min_val=512, max_val=100000)
+ check_argument(
+ "frame_length_ms",
+ c,
+ restricted=True,
+ min_val=10,
+ max_val=1000,
+ alternative="win_length",
+ )
+ check_argument("frame_shift_ms", c, restricted=True, min_val=1, max_val=1000, alternative="hop_length")
+ check_argument("preemphasis", c, restricted=True, min_val=0, max_val=1)
+ check_argument("min_level_db", c, restricted=True, min_val=-1000, max_val=10)
+ check_argument("ref_level_db", c, restricted=True, min_val=0, max_val=1000)
+ check_argument("power", c, restricted=True, min_val=1, max_val=5)
+ check_argument("griffin_lim_iters", c, restricted=True, min_val=10, max_val=1000)
+
+ # normalization parameters
+ check_argument("signal_norm", c, restricted=True)
+ check_argument("symmetric_norm", c, restricted=True)
+ check_argument("max_norm", c, restricted=True, min_val=0.1, max_val=1000)
+ check_argument("clip_norm", c, restricted=True)
+ check_argument("mel_fmin", c, restricted=True, min_val=0.0, max_val=1000)
+ check_argument("mel_fmax", c, restricted=True, min_val=500.0, allow_none=True)
+ check_argument("spec_gain", c, restricted=True, min_val=1, max_val=100)
+ check_argument("do_trim_silence", c, restricted=True)
+ check_argument("trim_db", c, restricted=True)
+
+
+@dataclass
+class BaseDatasetConfig(Coqpit):
+ """Base config for TTS datasets.
+
+ Args:
+ name (str):
+ Dataset name that defines the preprocessor in use. Defaults to None.
+
+ path (str):
+ Root path to the dataset files. Defaults to None.
+
+ meta_file_train (str):
+ Name of the dataset meta file. Or a list of speakers to be ignored at training for multi-speaker datasets.
+ Defaults to None.
+
+ unused_speakers (List):
+ List of speakers IDs that are not used at the training. Default None.
+
+ meta_file_val (str):
+ Name of the dataset meta file that defines the instances used at validation.
+
+ meta_file_attn_mask (str):
+ Path to the file that lists the attention mask files used with models that require attention masks to
+ train the duration predictor.
+ """
+
+ name: str = ""
+ path: str = ""
+ meta_file_train: str = ""
+ ununsed_speakers: List[str] = None
+ meta_file_val: str = ""
+ meta_file_attn_mask: str = ""
+
+ def check_values(
+ self,
+ ):
+ """Check config fields"""
+ c = asdict(self)
+ check_argument("name", c, restricted=True)
+ check_argument("path", c, restricted=True)
+ check_argument("meta_file_train", c, restricted=True)
+ check_argument("meta_file_val", c, restricted=False)
+ check_argument("meta_file_attn_mask", c, restricted=False)
+
+
+@dataclass
+class BaseTrainingConfig(Coqpit):
+ """Base config to define the basic training parameters that are shared
+ among all the models.
+
+ Args:
+ model (str):
+ Name of the model that is used in the training.
+
+ run_name (str):
+ Name of the experiment. This prefixes the output folder name. Defaults to `coqui_tts`.
+
+ run_description (str):
+ Short description of the experiment.
+
+ epochs (int):
+ Number training epochs. Defaults to 10000.
+
+ batch_size (int):
+ Training batch size.
+
+ eval_batch_size (int):
+ Validation batch size.
+
+ mixed_precision (bool):
+ Enable / Disable mixed precision training. It reduces the VRAM use and allows larger batch sizes, however
+ it may also cause numerical unstability in some cases.
+
+ scheduler_after_epoch (bool):
+ If true, run the scheduler step after each epoch else run it after each model step.
+
+ run_eval (bool):
+ Enable / Disable evaluation (validation) run. Defaults to True.
+
+ test_delay_epochs (int):
+ Number of epochs before starting to use evaluation runs. Initially, models do not generate meaningful
+ results, hence waiting for a couple of epochs might save some time.
+
+ print_eval (bool):
+ Enable / Disable console logging for evalutaion steps. If disabled then it only shows the final values at
+ the end of the evaluation. Default to ```False```.
+
+ print_step (int):
+ Number of steps required to print the next training log.
+
+ log_dashboard (str): "tensorboard" or "wandb"
+ Set the experiment tracking tool
+
+ plot_step (int):
+ Number of steps required to log training on Tensorboard.
+
+ model_param_stats (bool):
+ Enable / Disable logging internal model stats for model diagnostic. It might be useful for model debugging.
+ Defaults to ```False```.
+
+ project_name (str):
+ Name of the project. Defaults to config.model
+
+ wandb_entity (str):
+ Name of W&B entity/team. Enables collaboration across a team or org.
+
+ log_model_step (int):
+ Number of steps required to log a checkpoint as W&B artifact
+
+ save_step (int):ipt
+ Number of steps required to save the next checkpoint.
+
+ checkpoint (bool):
+ Enable / Disable checkpointing.
+
+ keep_all_best (bool):
+ Enable / Disable keeping all the saved best models instead of overwriting the previous one. Defaults
+ to ```False```.
+
+ keep_after (int):
+ Number of steps to wait before saving all the best models. In use if ```keep_all_best == True```. Defaults
+ to 10000.
+
+ num_loader_workers (int):
+ Number of workers for training time dataloader.
+
+ num_eval_loader_workers (int):
+ Number of workers for evaluation time dataloader.
+
+ output_path (str):
+ Path for training output folder, either a local file path or other
+ URLs supported by both fsspec and tensorboardX, e.g. GCS (gs://) or
+ S3 (s3://) paths. The nonexist part of the given path is created
+ automatically. All training artefacts are saved there.
+ """
+
+ model: str = None
+ run_name: str = "coqui_tts"
+ run_description: str = ""
+ # training params
+ epochs: int = 10000
+ batch_size: int = None
+ eval_batch_size: int = None
+ mixed_precision: bool = False
+ scheduler_after_epoch: bool = False
+ # eval params
+ run_eval: bool = True
+ test_delay_epochs: int = 0
+ print_eval: bool = False
+ # logging
+ dashboard_logger: str = "tensorboard"
+ print_step: int = 25
+ plot_step: int = 100
+ model_param_stats: bool = False
+ project_name: str = None
+ log_model_step: int = None
+ wandb_entity: str = None
+ # checkpointing
+ save_step: int = 10000
+ checkpoint: bool = True
+ keep_all_best: bool = False
+ keep_after: int = 10000
+ # dataloading
+ num_loader_workers: int = 0
+ num_eval_loader_workers: int = 0
+ use_noise_augment: bool = False
+ # paths
+ output_path: str = None
+ # distributed
+ distributed_backend: str = "nccl"
+ distributed_url: str = "tcp://localhost:54321"
diff --git a/speaker_pretrain/README.md b/speaker_pretrain/README.md
new file mode 100644
index 0000000..1cc5960
--- /dev/null
+++ b/speaker_pretrain/README.md
@@ -0,0 +1,5 @@
+Path for:
+
+ best_model.pth.tar
+
+ config.json
\ No newline at end of file
diff --git a/speaker_pretrain/config.json b/speaker_pretrain/config.json
new file mode 100644
index 0000000..e330aab
--- /dev/null
+++ b/speaker_pretrain/config.json
@@ -0,0 +1,104 @@
+{
+ "model_name": "lstm",
+ "run_name": "mueller91",
+ "run_description": "train speaker encoder with voxceleb1, voxceleb2 and libriSpeech ",
+ "audio":{
+ // Audio processing parameters
+ "num_mels": 80, // size of the mel spec frame.
+ "fft_size": 1024, // number of stft frequency levels. Size of the linear spectogram frame.
+ "sample_rate": 16000, // DATASET-RELATED: wav sample-rate. If different than the original data, it is resampled.
+ "win_length": 1024, // stft window length in ms.
+ "hop_length": 256, // stft window hop-lengh in ms.
+ "frame_length_ms": null, // stft window length in ms.If null, 'win_length' is used.
+ "frame_shift_ms": null, // stft window hop-lengh in ms. If null, 'hop_length' is used.
+ "preemphasis": 0.98, // pre-emphasis to reduce spec noise and make it more structured. If 0.0, no -pre-emphasis.
+ "min_level_db": -100, // normalization range
+ "ref_level_db": 20, // reference level db, theoretically 20db is the sound of air.
+ "power": 1.5, // value to sharpen wav signals after GL algorithm.
+ "griffin_lim_iters": 60,// #griffin-lim iterations. 30-60 is a good range. Larger the value, slower the generation.
+ // Normalization parameters
+ "signal_norm": true, // normalize the spec values in range [0, 1]
+ "symmetric_norm": true, // move normalization to range [-1, 1]
+ "max_norm": 4.0, // scale normalization to range [-max_norm, max_norm] or [0, max_norm]
+ "clip_norm": true, // clip normalized values into the range.
+ "mel_fmin": 0.0, // minimum freq level for mel-spec. ~50 for male and ~95 for female voices. Tune for dataset!!
+ "mel_fmax": 8000.0, // maximum freq level for mel-spec. Tune for dataset!!
+ "do_trim_silence": true, // enable trimming of slience of audio as you load it. LJspeech (false), TWEB (false), Nancy (true)
+ "trim_db": 60 // threshold for timming silence. Set this according to your dataset.
+ },
+ "reinit_layers": [],
+ "loss": "angleproto", // "ge2e" to use Generalized End-to-End loss and "angleproto" to use Angular Prototypical loss (new SOTA)
+ "grad_clip": 3.0, // upper limit for gradients for clipping.
+ "epochs": 1000, // total number of epochs to train.
+ "lr": 0.0001, // Initial learning rate. If Noam decay is active, maximum learning rate.
+ "lr_decay": false, // if true, Noam learning rate decaying is applied through training.
+ "warmup_steps": 4000, // Noam decay steps to increase the learning rate from 0 to "lr"
+ "tb_model_param_stats": false, // true, plots param stats per layer on tensorboard. Might be memory consuming, but good for debugging.
+ "steps_plot_stats": 10, // number of steps to plot embeddings.
+ "num_speakers_in_batch": 64, // Batch size for training. Lower values than 32 might cause hard to learn attention. It is overwritten by 'gradual_training'.
+ "voice_len": 2.0, // size of the voice
+ "num_utters_per_speaker": 10, //
+ "num_loader_workers": 8, // number of training data loader processes. Don't set it too big. 4-8 are good values.
+ "wd": 0.000001, // Weight decay weight.
+ "checkpoint": true, // If true, it saves checkpoints per "save_step"
+ "save_step": 1000, // Number of training steps expected to save traning stats and checkpoints.
+ "print_step": 20, // Number of steps to log traning on console.
+ "output_path": "../../OutputsMozilla/checkpoints/speaker_encoder/", // DATASET-RELATED: output path for all training outputs.
+ "model": {
+ "input_dim": 80,
+ "proj_dim": 256,
+ "lstm_dim": 768,
+ "num_lstm_layers": 3,
+ "use_lstm_with_projection": true
+ },
+ "storage": {
+ "sample_from_storage_p": 0.9, // the probability with which we'll sample from the DataSet in-memory storage
+ "storage_size": 25, // the size of the in-memory storage with respect to a single batch
+ "additive_noise": 1e-5 // add very small gaussian noise to the data in order to increase robustness
+ },
+ "datasets":
+ [
+ {
+ "name": "vctk_slim",
+ "path": "../../../audio-datasets/en/VCTK-Corpus/",
+ "meta_file_train": null,
+ "meta_file_val": null
+ },
+ {
+ "name": "libri_tts",
+ "path": "../../../audio-datasets/en/LibriTTS/train-clean-100",
+ "meta_file_train": null,
+ "meta_file_val": null
+ },
+ {
+ "name": "libri_tts",
+ "path": "../../../audio-datasets/en/LibriTTS/train-clean-360",
+ "meta_file_train": null,
+ "meta_file_val": null
+ },
+ {
+ "name": "libri_tts",
+ "path": "../../../audio-datasets/en/LibriTTS/train-other-500",
+ "meta_file_train": null,
+ "meta_file_val": null
+ },
+ {
+ "name": "voxceleb1",
+ "path": "../../../audio-datasets/en/voxceleb1/",
+ "meta_file_train": null,
+ "meta_file_val": null
+ },
+ {
+ "name": "voxceleb2",
+ "path": "../../../audio-datasets/en/voxceleb2/",
+ "meta_file_train": null,
+ "meta_file_val": null
+ },
+ {
+ "name": "common_voice",
+ "path": "../../../audio-datasets/en/MozillaCommonVoice",
+ "meta_file_train": "train.tsv",
+ "meta_file_val": "test.tsv"
+ }
+ ]
+}
\ No newline at end of file
diff --git a/spec/inference.py b/spec/inference.py
new file mode 100644
index 0000000..6cc4042
--- /dev/null
+++ b/spec/inference.py
@@ -0,0 +1,113 @@
+import argparse
+import torch
+import torch.utils.data
+import numpy as np
+import librosa
+from omegaconf import OmegaConf
+from librosa.filters import mel as librosa_mel_fn
+
+
+MAX_WAV_VALUE = 32768.0
+
+
+def load_wav_to_torch(full_path, sample_rate):
+ wav, _ = librosa.load(full_path, sr=sample_rate)
+ wav = wav / np.abs(wav).max() * 0.6
+ return torch.FloatTensor(wav)
+
+
+def dynamic_range_compression(x, C=1, clip_val=1e-5):
+ return np.log(np.clip(x, a_min=clip_val, a_max=None) * C)
+
+
+def dynamic_range_decompression(x, C=1):
+ return np.exp(x) / C
+
+
+def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
+ return torch.log(torch.clamp(x, min=clip_val) * C)
+
+
+def dynamic_range_decompression_torch(x, C=1):
+ return torch.exp(x) / C
+
+
+def spectral_normalize_torch(magnitudes):
+ output = dynamic_range_compression_torch(magnitudes)
+ return output
+
+
+def spectral_de_normalize_torch(magnitudes):
+ output = dynamic_range_decompression_torch(magnitudes)
+ return output
+
+
+mel_basis = {}
+hann_window = {}
+
+
+def mel_spectrogram(y, n_fft, num_mels, sampling_rate, hop_size, win_size, fmin, fmax, center=False):
+ if torch.min(y) < -1.:
+ print('min value is ', torch.min(y))
+ if torch.max(y) > 1.:
+ print('max value is ', torch.max(y))
+
+ global mel_basis, hann_window
+ if fmax not in mel_basis:
+ mel = librosa_mel_fn(sr=sampling_rate, n_fft=n_fft, n_mels=num_mels, fmin=fmin, fmax=fmax)
+ mel_basis[str(fmax)+'_'+str(y.device)] = torch.from_numpy(mel).float().to(y.device)
+ hann_window[str(y.device)] = torch.hann_window(win_size).to(y.device)
+
+ y = torch.nn.functional.pad(y.unsqueeze(1), (int((n_fft-hop_size)/2), int((n_fft-hop_size)/2)), mode='reflect')
+ y = y.squeeze(1)
+
+ # complex tensor as default, then use view_as_real for future pytorch compatibility
+ spec = torch.stft(y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[str(y.device)],
+ center=center, pad_mode='reflect', normalized=False, onesided=True, return_complex=True)
+ spec = torch.view_as_real(spec)
+ spec = torch.sqrt(spec.pow(2).sum(-1)+(1e-9))
+
+ spec = torch.matmul(mel_basis[str(fmax)+'_'+str(y.device)], spec)
+ spec = spectral_normalize_torch(spec)
+
+ return spec
+
+
+def mel_spectrogram_file(path, hps):
+ audio = load_wav_to_torch(path, hps.data.sampling_rate)
+ audio = audio.unsqueeze(0)
+
+ # match audio length to self.hop_length * n for evaluation
+ if (audio.size(1) % hps.data.hop_length) != 0:
+ audio = audio[:, :-(audio.size(1) % hps.data.hop_length)]
+ mel = mel_spectrogram(audio, hps.data.filter_length, hps.data.mel_channels, hps.data.sampling_rate,
+ hps.data.hop_length, hps.data.win_length, hps.data.mel_fmin, hps.data.mel_fmax, center=False)
+ return mel
+
+
+def print_mel(mel, path="mel.png"):
+ import matplotlib.pyplot as plt
+ fig = plt.figure(figsize=(12, 4))
+ if isinstance(mel, torch.Tensor):
+ mel = mel.cpu().numpy()
+ plt.pcolor(mel)
+ plt.savefig(path, format="png")
+ plt.close(fig)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("-w", "--wav", help="wav", dest="wav")
+ parser.add_argument("-m", "--mel", help="mel", dest="mel") # csv for excel
+ args = parser.parse_args()
+ print(args.wav)
+ print(args.mel)
+
+ hps = OmegaConf.load(f"./configs/base.yaml")
+
+ mel = mel_spectrogram_file(args.wav, hps)
+ # TODO
+ mel = torch.squeeze(mel, 0)
+ # [100, length]
+ torch.save(mel, args.mel)
+ print_mel(mel, "debug.mel.png")