| title | date | categories | tags | permalink | |||||
|---|---|---|---|---|---|---|---|---|---|
分布式存储面试 |
2025-01-07 00:01:21 -0800 |
|
|
/pages/748c9d17/ |
扩展:
:::details 要点
缓存就是数据交换的缓冲区,用于将频繁访问的数据暂存在访问速度快的存储介质。
缓存的本质是一种利用空间换时间的设计:牺牲一定的数据实时性,使得访问更快、更近:
- 将数据存储到读取速度更快的存储(设备);
- 将数据存储到离应用最近的位置;
- 将数据存储到离用户最近的位置。
缓存是用于存储数据的硬件或软件的组成部分,以使得后续更快访问相应的数据。缓存中的数据可能是提前计算好的结果、数据的副本等。典型的应用场景:有 cpu cache, 磁盘 cache 等。本文中提及到缓存主要是指互联网应用中所使用的缓存组件。
缓存命中率是缓存的重要度量指标,命中率越高越好。
缓存命中率 = 从缓存中读取次数 / 总读取次数
:::
:::details 要点
引入缓存,会增加系统的复杂度,并牺牲一定的数据实时性。所以,引入缓存前,需要先权衡是否值得,考量点如下:
- CPU 开销 - 如果应用某个计算需要消耗大量 CPU,可以考虑缓存其计算结果。典型场景:复杂的、频繁调用的正则计算;分布式计算中间状态等。
- IO 开销 - 如果数据库连接池比较繁忙,可以考虑缓存其查询结果。
在数据层引入缓存,有以下几个好处:
- 提升数据读取速度。
- 提升系统扩展能力,通过扩展缓存,提升系统承载能力。
- 降低存储成本,Cache+DB 的方式可以承担原有需要多台 DB 才能承担的请求量,节省机器成本。
:::
:::details 要点
缓存从部署角度,可以分为客户端缓存和服务端缓存。
客户端缓存
- Http 缓存:HTTP/1.1 中的
Cache-Control、HTTP/1 中的Expires - 浏览器缓存:HTML5 提供的 SessionStorage 和 LocalStorage、Cookie
- APP 缓存
- Android
- IOS
服务端缓存
- CDN 缓存 - CDN 将数据缓存到离用户物理距离最近的服务器,使得用户可以就近获取请求内容。CDN 一般缓存静态资源文件(页面,脚本,图片,视频,文件等)。
- 反向代理缓存 - 反向代理(Reverse Proxy)方式是指以代理服务器来接受网络连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给客户端,此时代理服务器对外就表现为一个反向代理服务器。反向代理缓存一般针对的是静态资源,而将动态资源请求转发到应用服务器处理。
- 数据库缓存 - 数据库(如 Mysql)自身一般也有缓存,但因为命中率和更新频率问题,不推荐使用。
- 进程内缓存 - 缓存应用字典等常用数据。
- 分布式缓存 - 缓存数据库中的热点数据。
其中,CDN 缓存、反向代理缓存、数据库缓存一般由专职人员维护(运维、DBA)。
后端开发一般聚焦于进程内缓存、分布式缓存。
:::
:::details 要点
CDN 将数据缓存到离用户物理距离最近的服务器,使得用户可以就近获取请求内容。CDN 一般缓存静态资源文件(页面,脚本,图片,视频,文件等)。
国内网络异常复杂,跨运营商的网络访问会很慢。为了解决跨运营商或各地用户访问问题,可以在重要的城市,部署 CDN 应用。使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。
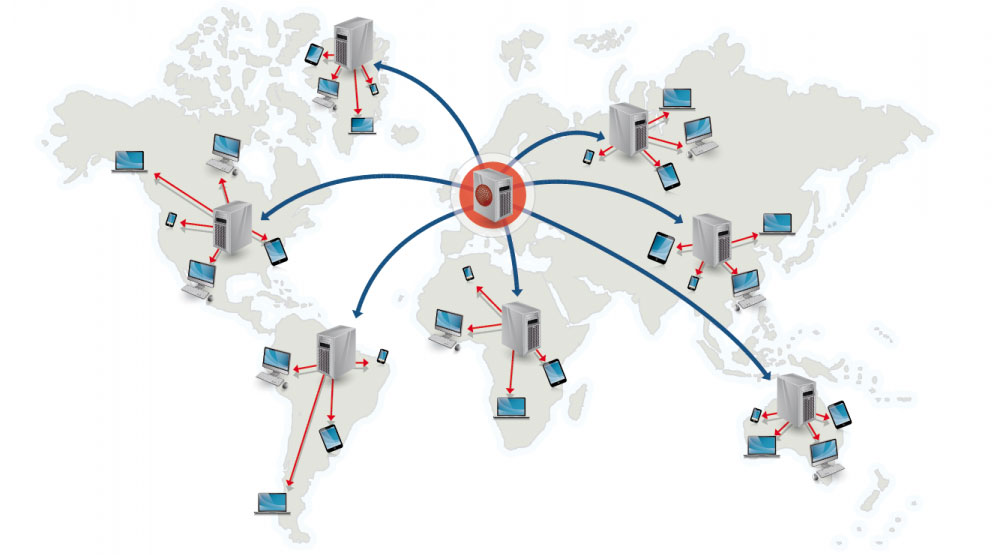
CDN 的基本原理是广泛采用各种缓存服务器,将这些缓存服务器分布到用户访问相对集中的地区或网络中,在用户访问网站时,利用全局负载技术将用户的访问指向距离最近的工作正常的缓存服务器上,由缓存服务器直接响应用户请求。
(1)未部署 CDN 应用前的网络路径:
- 请求:本机网络(局域网)=> 运营商网络 => 应用服务器机房
- 响应:应用服务器机房 => 运营商网络 => 本机网络(局域网)
在不考虑复杂网络的情况下,从请求到响应需要经过 3 个节点,6 个步骤完成一次用户访问操作。
(2)部署 CDN 应用后网络路径:
- 请求:本机网络(局域网) => 运营商网络
- 响应:运营商网络 => 本机网络(局域网)
在不考虑复杂网络的情况下,从请求到响应需要经过 2 个节点,2 个步骤完成一次用户访问操作。
与不部署 CDN 服务相比,减少了 1 个节点,4 个步骤的访问。极大的提高了系统的响应速度。
优点
- 本地 Cache 加速 - 提升访问速度,尤其含有大量图片和静态页面站点;
- 实现跨运营商的网络加速 - 消除了不同运营商之间互联的瓶颈造成的影响,实现了跨运营商的网络加速,保证不同网络中的用户都能得到良好的访问质量;
- 远程加速 - 远程访问用户根据 DNS 负载均衡技术智能自动选择 Cache 服务器,选择最快的 Cache 服务器,加快远程访问的速度;
- 带宽优化 - 自动生成服务器的远程 Mirror(镜像)cache 服务器,远程用户访问时从 cache 服务器上读取数据,减少远程访问的带宽、分担网络流量、减轻原站点 WEB 服务器负载等功能。
- 集群抗攻击 - 广泛分布的 CDN 节点加上节点之间的智能冗余机制,可以有效地预防黑客入侵以及降低各种 D.D.o.S 攻击对网站的影响,同时保证较好的服务质量。
缺点
- 不适宜缓存动态资源
- 解决方案:主要缓存静态资源,动态资源建立多级缓存或准实时同步;
- 存在数据的一致性问题
- 解决方案(主要是在性能和数据一致性二者间寻找一个平衡)
- 设置缓存失效时间(1 个小时,过期后同步数据)。
- 针对资源设置版本号。
:::
:::details 要点
反向代理(Reverse Proxy)方式是指以代理服务器来接受网络连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给客户端,此时代理服务器对外就表现为一个反向代理服务器。
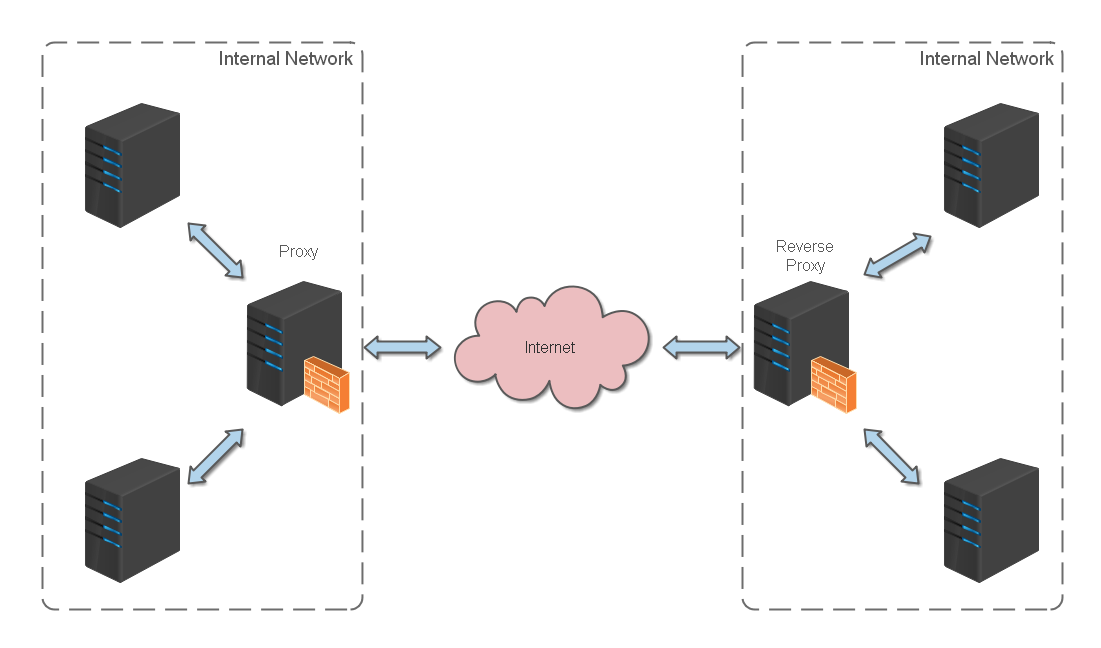
反向代理位于应用服务器同一网络,处理所有对 WEB 服务器的请求。
反向代理缓存的原理:
- 如果用户请求的页面在代理服务器上有缓存的话,代理服务器直接将缓存内容发送给用户。
- 如果没有缓存则先向 WEB 服务器发出请求,取回数据,本地缓存后再发送给用户。
这种方式通过降低向 WEB 服务器的请求数,从而降低了 WEB 服务器的负载。
反向代理缓存一般针对的是静态资源,而将动态资源请求转发到应用服务器处理。常用的缓存应用服务器有 Varnish,Ngnix,Squid。
:::
扩展:
:::details 要点
缓存一般存于访问速度较快的存储介质,快也就意味着资源昂贵并且有限。正所谓,好钢要用在刀刃上。因此,缓存要合理利用,需要设定一些机制,将一些访问频率偏低或过期的数据淘汰。
淘汰缓存首先要做的是,确定什么时候触发淘汰缓存,一般有以下几个思路:
- 基于空间 - 设置缓存空间大小。
- 基于容量 - 设置缓存存储记录数。
- 基于时间
- TTL(Time To Live,即存活期) - 缓存数据从创建到过期的时间。
- TTI(Time To Idle,即空闲期) - 缓存数据多久没被访问的时间。
接下来,就要确定如何淘汰缓存,常见的缓存淘汰算法有以下几个:
- FIFO(First In First Out,先进先出) - 淘汰最先进入的缓存数据。缓存的行为就像一个队列。
- 优点:这种方案非常简单
- 缺点:可能会导致缓存命中率低。因为,进入缓存的先后顺序和访问频率无关,这种算法可能会将访问频率高的数据给淘汰。
- LIFO(Last In First Out,后进先出) - 淘汰最后进入的缓存数据。缓存的行为就像一个栈。
- 优点:这种方案非常简单
- 缺点:和 FIFO 一样,也可能会导致缓存命中率低。因为,进入缓存的先后顺序和访问频率无关,这种算法可能会将访问频率高的数据给淘汰。
- MRU(Most Recently Used,最近最多使用) - 淘汰最近最多使用缓存。
- 优点:适用于一些特殊场景,例如数据访问具有较强的局部性。举个例子,用户访问一个信息流页面,已经看过的内容,他肯定不想再看到,此时就可以使用 MRU。
- 缺点:某些情况下,可能会导致频繁的淘汰缓存,从而降低缓存命中率
- LRU(Least Recently Used,最近最少使用) - 淘汰最近最少使用缓存。
- 优点:避免了 FIFO 缓存命中率低的问题。
- 缺点:存在临界区问题。假设,缓存只保留 1 分钟以内的热点数据。如果有个数据在 1 个小时的前 59 分钟访问了 1 万次(可见这是个热点数据),最后一分钟没有任何访问;而其他数据有被访问,就会导致这个热点数据被淘汰。
- LFU(Less Frequently Used,最近最少频率使用) - 该算法对 LRU 做了进一步优化:利用额外的空间记录每个数据的使用频率,然后淘汰使用频率最低的数据,如果所有数据使用频率相同,可以用 FIFO 淘汰最早的缓存数据。
- 优点:解决了 LRU 的临界区问题。
- 缺点:记录使用频率,会产生额外的空间开销
:::
:::details 要点

一般来说,系统如果不是严格要求缓存和数据库保持一致性的话,尽量不要将读请求和写请求串行化。串行化可以保证一定不会出现数据不一致的情况,但是它会导致系统的吞吐量大幅度下降。缓存更新的常见策略有以下几种:
- Cache Aside
- Wirte Through
- Read Though
- Wirte Behind
需要注意的是:以上几种缓存更新策略,都无法保证数据强一致。如果一定要保证强一致性,可以通过两阶段提交(2PC)或 Paxos 协议来实现。但是 2PC 太慢,而 Paxos 太复杂,所以如果不是非常重要的数据,不建议使用强一致性方案。
:::
:::details 要点
:::
:::details 要点
:::
:::details 要点
:::
:::details 要点
:::
:::details 要点
:::
:::details 要点
:::
:::details 要点
:::
:::details 要点
:::
:::details 要点
:::
:::details 要点
:::