LSM-Tree 的全称为日志结构合并树(Log-Structured Merge Tree),核心思想是将内存中的缓存数据以记录日志的形式追加写入到存储介质,初衷是为了将小粒度的随机写聚合成大粒度的顺序追加写,从而减少机械磁盘悬臂的频繁机械运动,提升 I/O 效率。

LSM-Tree 的基本结构如上图,数据被分成了多层,其中 C0 存储在内存,其他层存储在外存,数据在每一层按照 Key 的大小依次排列,并且这些层的容量依次成倍增加。
当键值对写入 LSM-Tree 时,首先会被插入到位于内存中的 C0,当 C0 满了以后,C0 中的数据会和 C1 中的数据进行合并,合并后的结果会重新写入 C1。同理,当 Cn 满了时,Cn 也会和 Cn+1 合并,合并后的结果写入 Cn+1。这些合并操作被称为 Compaction 操作。
而在查找指定键时我们需要从新向旧,即从 C0 开始逐层向下进行查找,可能需要遍历多层才能找到。
这些是 LSM-Tree 的基本概念,在实际应用时需要考虑很多问题(如每一层以什么结构组织),为了让大家对 LSM-Tree 有一个更直观的理解,我们以业内常见的 LevelDB 的 LSM-Tree 实现为例进行详细介绍。

如图,LevelDB 主要由两部分组成,一部分是驻留在内存的 MemTable(内存表)和 Immutable MemTable(只读内存表),对应前面讲的 C0。
另一部分存储在外存并且分成了多层,从 L0 开始分别对应前面讲的 C1~Cn,其中每层含有许多的 SSTable(Sorted String Table,顺序字符串表)文件,而 Key-value 数据就被封装在这些 SSTable 文件里。除了 L0 层,其他层存放的 SSTable 都是按 Key 的顺序排列的,也就是说这些层中 SSTable 文件的 Key 范围是没有重叠的。
除了数据外,LevelDB 还有 Log、Mainfest 以及 Current 文件:
-
Log 文件存储最近的数据更新,采用追加的方式将每次的更新数据写到日志文件的末尾,每个日志文件对应当前的 MemTable,更新操作先写入日志文件然后更新内存表。当内存表被写入 SSTable 文件后,相应的日志文件会被删除。Log 文件也可做故障恢复。
-
Mainfest 文件存储当前数据库元数据,如每层包含哪些 SSTable 文件、每个文件中 key 的范围以及其他的元数据信息,如日志文件等。
-
Current 文件是一个简单的文本文件,记录当前使用的 Mainfest 文件名,通常通过判断当前文件是否存在来判断数据库是否已经创建。
LevelDB 的数据写入流程可以理解为两步:
-
追加一条日志记录到 Log 文件。
-
写入 MemTable,其中 MemTable 被实现为跳表,跳表的功能和平衡树类似,但实现更为简单,并且维持平衡的操作更轻量。
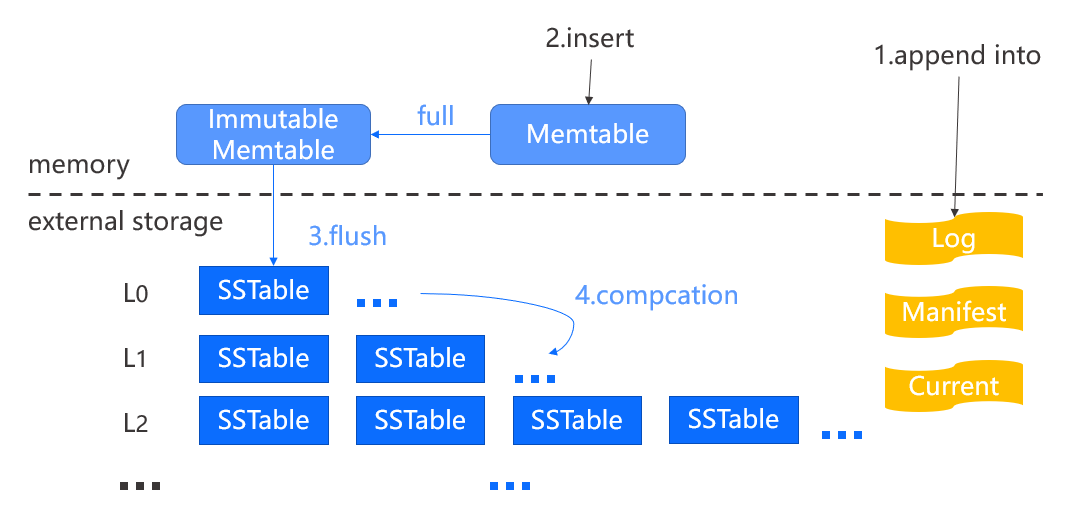
当 MemTable 容量达到上限时,它会转变为一个 Immutable MemTable,只允许读而不允许写,并创建一个新的 MemTable 提供写入。Immutable MemTable 未来将转换成 SSTable 文件并 flush 到 L0,为了更快速的下刷,L0 的 SSTable 是直接生成的,因此文件之间是可能重叠的。
而随着 MemTable 不断的被转化成 SSTable 文件并写入 L0 后,L0 的文件数量会超过容量限制,进而触发 Compaction 操作。

如上图所示,由于 L0 层的文件存在范围重叠,我们将从 L0 层读取所有文件,并在 L0 的下一层,即 L1 层找到 Key 范围与 L0 所读取文件有重叠的所有文件,然后将这些文件中的数据在内存进行合并排序后,重新生成新的 SSTable 文件写入 L1 层。由于可能有重复的新旧数据,合并过程中会删除旧数据,因此合并后一般能够减少文件的总量。其他层的合并也是类似的,只是每次只从当前层选取一个 SSTable 文件与下层进行合并。
Compaction 操作是 LSM-Tree 内部数据整合的机制,也是其中最复杂的过程之一,具体实现起来有很多细节与优化方法。
对于查询来说,首先是依次在 MemTable 和 Immutable MemTable 中查询,如果都没有找到,则在外存中继续查找。在外存中查找时,我们会从 mainfest 文件中读取各层中 SSTable 文件的 Key 范围,然后找出可能包含查询 Key 的 SSTable 文件,这个信息一般会被缓存在内存中。

除了 L0 层外,其他各层最多只有一个 SSTable 文件可能包含查询键。随后我们将这些文件按所在层排序,位于 L0 层的在前,L0 层内的文件按时间先后逆序排列,然后按照顺序依次在 SSTable 文件内查找。
SSTable 文件内的数据是排序的,并被切割成多个数据块,由内部的索引信息记录着各个数据块中 Key 的范围。因此查询一般首先通过索引信息确定可能包含 Key 的数据块,然后在数据块内查找。
LevelDB 在每个 SSTable 文件中为每个数据块建立了一个布隆过滤器,在数据块内的查找前可以通过布隆过滤器来提前检验,如果确定不存在,则继续到下一个 SSTable 文件进行查找。