If you see this page, the nginx web server is successfully installed and +working. Further configuration is required.
+``` + +It works! Wait, so will you need to hardcode this VIP in your configuration? What if it changes from environment to environment? +Thankfully, K8s team thought about this as well, and we can simply do: + +```bash +$ kubectl run -i -t --rm cli --image=appropriate/curl --restart=Never /bin/sh +curl http://my-nginx + +... +``` + +K8s uses a [CoreDNS](https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/dns) service +that watches the services and pods and sets up appropriate `A` records. Our `sandbox` local DNS server is simply configured to point to the DNS service provided by K8s. + +That's very similar how K8s manages discovery in containers as well. Let's login into one of the nginx boxes and +discover `/etc/resolv.conf` there: + + +```bash +$ kubectl exec -ti my-nginx-3800858182-auusv -- /bin/bash +root@my-nginx-3800858182-auusv:/# cat /etc/resolv.conf + +nameserver 10.100.0.4 +search default.svc.cluster.local svc.cluster.local cluster.local hsd1.ca.comcast.net +options ndots:5 +``` + +`resolv.conf` is set up to point to the DNS resolution service managed by K8s. + +## Back to Deployments + +The power of Deployments comes from ability to run smart upgrades and rollbacks in case if something goes wrong. + +Let's update our deployment of nginx to the newer version. + +```bash +$ cat my-nginx-new.yaml +``` + +```yaml +apiVersion: apps/v1 +kind: Deployment +metadata: + labels: + run: my-nginx + name: my-nginx + namespace: default +spec: + replicas: 2 + selector: + matchLabels: + run: my-nginx + template: + metadata: + labels: + run: my-nginx + spec: + containers: + - image: nginx:1.17.5 + name: my-nginx + ports: + - containerPort: 80 + protocol: TCP +``` + +Let's apply our deployment: + +```bash +$ kubectl apply -f my-nginx-new.yaml --record +``` + +We can see that a new ReplicaSet has been created: + +```bash +$ kubectl get rs + +NAME DESIRED CURRENT AGE +my-nginx-1413250935 2 2 50s +my-nginx-3800858182 0 0 2h +``` + +If we look at the events section of the deployment we will see how it performed rolling update scaling up new ReplicaSet while scaling down the old one: + + +```bash +$ kubectl describe deployments/my-nginx +Name: my-nginx +Namespace: default +CreationTimestamp: Sun, 15 May 2016 19:37:01 +0000 +Labels: run=my-nginx +Selector: run=my-nginx +Replicas: 2 updated | 2 total | 2 available | 0 unavailable +StrategyType: RollingUpdate +MinReadySeconds: 0 +RollingUpdateStrategy: 1 max unavailable, 1 max surge +OldReplicaSets:%s
++
Pleasanton, CA +Saturday 8:00 PM +Partly Cloudy +12 C +Precipitation: 9% +Humidity: 74% +Wind: 14 km/h +
++
The server encountered an internal error and was unable to complete your request. Either the server is overloaded or there is an error in the application.
+``` + +However our frontend should be all good: + +```bash +$ kubectl run -ti --rm cli --image=appropriate/curl --restart=Never --command /bin/sh +$ curl http://frontend + + +weather unavailable
++
The server encountered an internal error and was unable to complete your request. Either the server is overloaded or there is an error in the application.
+``` + +The problem though, is that every request to frontend takes 10 seconds as well: + +```bash +$ curl http://frontend +``` + +This is a much more common type of outage - users leave in frustration as the service is unavailable. + +To fix this issue we are going to introduce a special proxy with [circuit breaker](http://vulcand.github.io/proxy.html#circuit-breakers). + +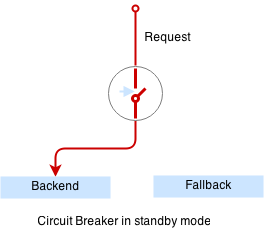 + +Circuit breaker is a special middleware that is designed to provide a fail-over action in case the service has degraded. It is very helpful to prevent cascading failures - where the failure of the one service leads to failure of another. Circuit breaker observes requests statistics and checks the stats against a special error condition. + +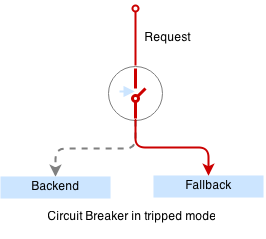 + +Here is our simple circuit breaker written in python: + +```python +from flask import Flask +import requests +from datetime import datetime, timedelta +from threading import Lock +import logging, sys + + +app = Flask(__name__) + +circuit_tripped_until = datetime.now() +mutex = Lock() + +def trip(): + global circuit_tripped_until + mutex.acquire() + try: + circuit_tripped_until = datetime.now() + timedelta(0,30) + app.logger.info("circuit tripped until %s" %(circuit_tripped_until)) + finally: + mutex.release() + +def is_tripped(): + global circuit_tripped_until + mutex.acquire() + try: + return datetime.now() < circuit_tripped_until + finally: + mutex.release() + + +@app.route("/") +def hello(): + weather = "weather unavailable" + try: + if is_tripped(): + return "circuit breaker: service unavailable (tripped)" + + r = requests.get('http://localhost:5000', timeout=1) + app.logger.info("requesting weather...") + start = datetime.now() + app.logger.info("got weather in %s ..." % (datetime.now() - start)) + if r.status_code == requests.codes.ok: + return r.text + else: + trip() + return "circuit breaker: service unavailable (tripping 1)" + except: + app.logger.info("exception: %s", sys.exc_info()[0]) + trip() + return "circuit breaker: service unavailable (tripping 2)" + +if __name__ == "__main__": + app.logger.addHandler(logging.StreamHandler(sys.stdout)) + app.logger.setLevel(logging.DEBUG) + app.run(host='0.0.0.0', port=6000) +``` + +Let's build and redeploy our circuit breaker: + +```bash +$ docker build -t $registry:5000/cbreaker:0.0.1 -f cbreaker.dockerfile . +$ docker push $registry:5000/cbreaker:0.0.1 +$ kubectl apply -f weather-cbreaker.yaml +deployment "weather" configured +$ kubectl apply -f weather-service.yaml +service "weather" configured +``` + +Circuit breaker runs as a separate container next to the weather service container in the same pod: + +```bash +$ cat weather-cbreaker.yaml +``` + +Note that we have reconfigured our service so requests are handled by the circuit breaker first which forwards requests to the weather service running in the same pod, and trips if the request fails. + +The circuit breaker will detect the service outage and the auxilliary weather service will not bring our mail service down anymore: + +```bash +$ kubectl run -ti --rm cli --image=appropriate/curl --restart=Never --command /bin/sh +$ curl http://frontend + + +circuit breaker: service unavailable (tripped)
++
| Metric Name + | +Description + | +|
| cpu + | +limit + | +CPU hard limit in millicores. + | +
| node_capacity + | +CPU capacity of a node. + | +|
| node_allocatable + | +CPU allocatable of a node. + | +|
| node_reservation + | +Share of CPU that is reserved on the node allocatable. + | +|
| node_utilization + | +CPU utilization as a share of node allocatable. + | +|
| request + | +CPU request (the guaranteed amount of resources) in millicores. + | +|
| usage + | +Cumulative amount of consumed CPU time on all cores in nanoseconds. + | +|
| usage_rate + | +CPU usage on all cores in millicores. + | +|
| load + | +CPU load in milliloads, i.e., runnable threads * 1000 + | +|
| ephemeral_storage + | +limit + | +Local ephemeral storage hard limit in bytes. + | +
| request + | +Local ephemeral storage request (the guaranteed amount of resources) in bytes. + | +|
| usage + | +Total local ephemeral storage usage. + | +|
| node_capacity + | +Local ephemeral storage capacity of a node. + | +|
| node_allocatable + | +Local ephemeral storage allocatable of a node. + | +|
| node_reservation + | +Share of local ephemeral storage that is reserved on the node allocatable. + | +|
| node_utilization + | +Local ephemeral utilization as a share of ephemeral storage allocatable. + | +|
| filesystem + | +usage + | +Total number of bytes consumed on a filesystem. + | +
| limit + | +The total size of filesystem in bytes. + | +|
| available + | +The number of available bytes remaining in a the filesystem + | +|
| inodes + | +The number of available inodes in a the filesystem + | +|
| inodes_free + | +The number of free inodes remaining in a the filesystem + | +|
| disk + | +io_read_bytes + | +Number of bytes read from a disk partition + | +
| io_write_bytes + | +Number of bytes written to a disk partition + | +|
| io_read_bytes_rate + | +Number of bytes read from a disk partition per second + | +|
| io_write_bytes_rate + | +Number of bytes written to a disk partition per second + | +|
| memory + | +limit + | +Memory hard limit in bytes. + | +
| major_page_faults + | +Number of major page faults. + | +|
| major_page_faults_rate + | +Number of major page faults per second. + | +|
| node_capacity + | +Memory capacity of a node. + | +|
| node_allocatable + | +Memory allocatable of a node. + | +|
| node_reservation + | +Share of memory that is reserved on the node allocatable. + | +|
| node_utilization + | +Memory utilization as a share of memory allocatable. + | +|
| page_faults + | +Number of page faults. + | +|
| page_faults_rate + | +Number of page faults per second. + | +|
| request + | +Memory request (the guaranteed amount of resources) in bytes. + | +|
| usage + | +Total memory usage. + | +|
| cache + | +Cache memory usage. + | +|
| rss + | +RSS memory usage. + | +|
| working_set + | +Total working set usage. Working set is the memory being used and not easily dropped by the kernel. + | +|
| accelerator + | +memory_total + | +Memory capacity of an accelerator. + | +
| memory_used + | +Memory used of an accelerator. + | +|
| duty_cycle + | +Duty cycle of an accelerator. + | +|
| request + | +Number of accelerator devices requested by container. + | +|
| network + | +rx + | +Cumulative number of bytes received over the network. + | +
| rx_errors + | +Cumulative number of errors while receiving over the network. + | +|
| rx_errors_rate + | +Number of errors while receiving over the network per second. + | +|
| rx_rate + | +Number of bytes received over the network per second. + | +|
| tx + | +Cumulative number of bytes sent over the network + | +|
| tx_errors + | +Cumulative number of errors while sending over the network + | +|
| tx_errors_rate + | +Number of errors while sending over the network + | +|
| tx_rate + | +Number of bytes sent over the network per second. + | +|
| uptime + | +- + | +Number of milliseconds since the container was started. + | +
| Metric Name + | +Description + | +
| load1 (float) + | +Warning threshold for load over 1 min + | +
| load15 (float) + | +Warning threshold for load over 15 mins + | +
| load5 (float) + | +Warning threshold for load over 5 mins + | +
| n_users (integer) + | +Number of users + | +
| n_cpus (integer) + | +Number of CPU cores + | +
| uptime (integer, seconds) + | +Number of milliseconds since the system was started + | +
| Component + | +Alert + | +Description + | +
| CPU + | +High CPU usage + | +Warning at > 75% used
+ +Critical error at > 90% used + |
+
| Memory + | +High Memory usage + | +Warning at > 80% used
+ +Critical error at > 90% used + |
+
| Systemd + | +Individual + | +Error when unit not loaded/active + | +
| Overall systemd health + | +Error when systemd detects a failed service + | +|
| Filesystem + | +High disk space usage + | +Warning at > 80% used
+ +Critical error at > 90% used + |
+
| High inode usage + | +Warning at > 90% used
+ +Critical error at > 95% used + |
+ |
| System + | +Uptime + | +Warning node uptime < 5 mins + | +
| Kernel params + | +Error if param not set + | +|
| Etcd + | +Etcd instance health + | +Error when etcd master down > 5 mins + | +
| Etcd latency check + | +Warning when follower <-> leader latency > 500 ms
+ +Error when > 1 sec over period of 1 min + |
+ |
| Docker + | +Docker daemon health + | +Error when docker daemon is down + | +
| InfluxDB + | +InfluxDB instance health + | +Error when InfluxDB is inaccessible + | +
| Kubernetes + | +Kubernetes node readiness + | +Error when the node is not ready + | +
Level: {{ .Level }}
+Nodename: {{ index .Tags "nodename" }}
+Usage: {{ index .Fields "avg_percent_used" | printf "%0.2f" }}%
+ ''') + .email() + .log('/var/lib/kapacitor/logs/high_cpu.log') + .mode(0644) +``` + +And create it : + +``` +$ gravity resource create -f formula.yaml +``` + +Custom alerts are being monitored by another “watcher” type of service that runs inside the Kapacitor pod: + +``` +$ kubectl -nmonitoring logs kapacitor-68f6d76878-8m26x watcher +time="2020-01-24T06:18:10Z" level=info msg="Detected event ADDED for configmap \"my-formula\"" label="monitoring in (alert)" watch=configmap +``` + +We can confirm the alert is running checking the logs after a few seconds: + +``` +$ kubectl -nmonitoring exec -ti kapacitor-68f6d76878-8m26x -c kapacitor cat -- /var/lib/kapacitor/logs/high_cpu.log +{"id":"percent_used:nodename=10.0.2.15","message":"WARNING / Node 10.0.2.15 has high cpu usage: 15%","details":"\n\u003cb\u003eWARNING / Node 10.0.2.15 has high cpu usage: 15%\u003c/b\u003e\n\u003cp\u003eLevel: WARNING\u003c/p\u003e\n\u003cp\u003eNodename: 10.0.2.15\u003c/p\u003e\n\u003cp\u003eUsage: 15.00%\u003c/p\u003e\n","time":"2020-01-24T06:30:00Z","duration":0,"level":"WARNING","data":{"series":[{"name":"percent_used","tags":{"nodename":"10.0.2.15"},"columns":["time","avg_percent_used"],"values":[["2020-01-24T06:30:00Z",15]]}]},"previousLevel":"OK","recoverable":true} +``` + +To view all currently configured custom alerts you can run: + +``` +$ gravity resource get alert my-formula +``` + +In order to remove a specific alert you can execute the following kapacitor command inside the designated pod: + +``` +$ kapacitor delete alert my-formula +``` + +This concludes our monitoring training. diff --git a/networking-workshop/monitoring-6.x.md b/networking-workshop/monitoring-6.x.md new file mode 100644 index 00000000..9d11fd82 --- /dev/null +++ b/networking-workshop/monitoring-6.x.md @@ -0,0 +1,815 @@ +# Gravity Monitoring & Alerts (for Gravity 6.0 and later) + +## Prerequisites + +Docker 101, Kubernetes 101, Gravity 101. + +## Introduction + +_Note: This part of the training pertains to Gravity 6.0 and later. In Gravity 6.0 Gravitational replaced InfluxDB/Kapacitor monitoring stack with Prometheus/Alertmanager._ + +Gravity Clusters come with a fully configured and customizable monitoring and alerting systems by default. The system consists of various components, which are automatically included into a Cluster Image that is built with a single command `tele build`. + +## Overview + +Before getting into Gravity’s monitoring and alerts capability in more detail, let’s first discuss the various components that are involved. + +There are 4 main components in the monitoring system: Prometheus, Grafana, Alertmanager and Satellite. + +### Prometheus + +Is an open source Kubernetes native monitoring system and time-series database that collects hardware and OS metrics, as well as metrics about various k8s resources (deployments, nodes, and pods). Prometheus exposes the cluster-internal service `prometheus-k8s.monitoring.svc.cluster.local:9090`. + +### Grafana + +Is an open source metrics suite which provides the dashboard in the Gravity monitoring and alerts system. The dashboard provides a visual to the information stored in Prometheus, which is exposed as the service `grafana.monitoring.svc.cluster.local:3000`. Credentials generated are placed into a secret `grafana` in the monitoring namespace + +Gravity is shipped with 2 pre-configured dashboards providing a visual of machine and pod-level overview of the installed cluster. Within the Gravity control panel, you can access the dashboard by navigating to the Monitoring page. + +By default, Grafana is running in anonymous read-only mode. Anyone who logs into Gravity can view but not modify the dashboards. + +### Alertmanager + +Is a Prometheus component that handles alerts sent by client applications such as a Prometheus server. Alertmanager handles deduplicating, grouping and routing alerts to the correct receiver integration such as an email recipient. Alertmanager exposes the cluster-internal service `alertmanager-main.monitoring.svc.cluster.local:9093`. + +### Satellite + +[Satellite](https://github.com/gravitational/satellite) is an open-source tool prepared by Gravitational that collects health information related to the Kubernetes cluster. Satellite runs on each Gravity Cluster node and has various checks assessing the health of a Cluster. Any issues detected by Satellite are shown in the output of the gravity status command. + +## Metrics Overview + +All monitoring components are running in the “monitoring” namespace in Gravity. Let’s take a look at them: + +``` +$ kubectl -nmonitoring get pods +NAME READY STATUS RESTARTS AGE +alertmanager-main-0 3/3 Running 0 27m +alertmanager-main-1 3/3 Running 0 26m +alertmanager-main-2 3/3 Running 0 26m +grafana-6b645587d-chxxg 2/2 Running 0 27m +kube-state-metrics-69594c468-wcr4g 3/3 Running 0 27m +nethealth-4cjwh 1/1 Running 0 26m +node-exporter-hz972 2/2 Running 0 27m +prometheus-adapter-6586cf7b4f-hmwkf 1/1 Running 0 27m +prometheus-k8s-0 3/3 Running 1 26m +prometheus-k8s-1 0/3 Pending 0 26m +prometheus-operator-7bd7d57788-mf8xn 1/1 Running 0 27m +watcher-7b99cc55c-8qgms 1/1 Running 0 27m +``` + +Most of the cluster metrics are collected by Prometheus which uses the following in-cluster services: + +* [node-exporter](https://github.com/prometheus/node_exporter) (collects hardware and OS metrics) +* [kube-state-metrics](https://github.com/kubernetes/kube-state-metrics) (collects Kubernetes resource metrics - deployments, nodes, pods) + +kube-state-metrics collects metrics about various Kubernetes resources such as deployments, nodes and pods. It is a service that listens to the Kubernetes API server and generates metrics about the state of the objects. + +Further, kube-state-metrics exposes raw data that is unmodified from the Kubernetes API, which allows users to have all the data they require and perform heuristics as they see fit. In return, kubectl may not show the same values, as kubectl applies certain heuristics to display cleaner messages. + +Metrics from kube-state-metrics service are exported on the HTTP endpoint `/metrics` on the listening port (default 8080) and are designed to be consumed by Prometheus. + + + +(Source: https://medium.com/faun/production-grade-kubernetes-monitoring-using-prometheus-78144b835b60) + +All metrics collected by node-exporter and kube-state-metrics are stored as time series in Prometheus. See below for a list of metrics collected by Prometheus. Each metric is stored as a separate “series” in Prometheus. + +Prometheus allows users to differentiate on the things that are being measured. Label names should not be used in the metric name as that leads to some redundancy. + +* `api_http_requests_total` - differentiate request types: `operation="create|update|delete"` + +When troubleshooting problems with metrics, it is sometimes useful to look into the specified container logs where it can be seen if it experiences communication issues with Prometheus service or has other issues: + +``` +$ kubectl -nmonitoring logs prometheus-adapter-6586cf7b4f-hmwkf +``` + +``` +$ kubectl -nmonitoring logs kube-state-metrics-69594c468-wcr4g kube-state-metrics +``` + +``` +$ kubectl -nmonitoring logs node-exporter-hz972 node-exporter +``` + +In addition, any other apps that collect metrics should also submit them into the same DB in order for proper retention policies to be enforced. + +## Exploring Prometheus + +Like mentioned above, Prometheus is exposed via a cluster-local Kubernetes service `prometheus-k8s.monitoring.svc.cluster.local:9090` and serves its HTTP API on port `9090` so we can use it to explore the database from the CLI. + +Also, as seen above we have the following Prometheus pods: + +``` +prometheus-adapter-6586cf7b4f-hmwkf +prometheus-k8s-0 +prometheus-operator-7bd7d57788-mf8xn +``` +Prometheus operator for Kubernetes allows easy monitoring definitions for kubernetes services and deployment and management of Prometheus instances. + +Prometheus adapter is an API extension for kubernetes that users prometheus queries to populate kubernetes resources and custom metrics APIs. + +Let's enter the Gravity master container to make sure the services are resolvable and to get access to additional CLI tools: + +```bash +$ sudo gravity shell +``` + +Let's ping the database to make sure it's up and running: + +```bash +$ curl -sl http://prometheus-k8s.monitoring.svc.cluster.local:9090/api/v1/status/config +// Should return "status":"success" within currently loaded configuration file. +``` + +A list of alerting and recording rules that are currently loaded is available by executing: + +```bash +$ curl http://prometheus-k8s.monitoring.svc.cluster.local:9090/api/v1/rules | jq +``` +Also we can see all metric points, by executing the following command: + +```bash +$ curl http://prometheus-k8s.monitoring.svc.cluster.local:9090/api/v1/query?query=up | jq +``` + +Finally, we can query Prometheus using it's SQL-like query language (PromQL) to for example evaluate metrics identified under the expression `up` at the specified time: + +```bash +$ curl 'http://prometheus-k8s.monitoring.svc.cluster.local:9090/api/v1/query?query=up&time=2020-03-13T20:10:51.781Z' | jq +``` + +Refer to the Prometheus [API documentation](https://prometheus.io/docs/prometheus/latest/querying/basics/) if you want to learn more about querying the database. + +## Metric Retention Policy + +### Time based retention + +By default Gravitational configures Prometheus with a time based retention policy of 30 days. + +## Custom Dashboards + +Along with the dashboards mentioned above, your applications can use their own Grafana dashboards by using ConfigMaps. + +In order to create a custom dashboard, the ConfigMap should be created in the `monitoring` namespace, assigned a `monitoring` label with a value `dashboard`. + +Under the specified namespace, the ConfigMap will be recognized and loaded when installing the application. It is possible to add new ConfigMaps at a later time as the watcher will then pick it up and create it in Grafana. Similarly, if you delete the ConfigMap, the watcher will delete it from Grafana. + +Dashboard ConfigMaps may contain multiple keys with dashboards as key names are not relevant. + +An example ConfigMap is shown below: + +``` +apiVersion: v1 +kind: ConfigMap +metadata: + name: mydashboard + namespace: monitoring + labels: + monitoring: dashboard +data: + mydashboard: | + { ... dashboard JSON ... } +``` + +_Note: by default Grafana is run in read-only mode, a separate Grafana instance is required to create custom dashboards._ + +## Default Metrics + +The following are the default metrics captured by the Gravity Monitoring & Alerts system: + +### node-exporter Metrics + +Below are a list of metrics captured by node-exporter which are exported to the backend by based on OS: + +| Name + | +Description + | +OS + | +
| arp + | +Exposes ARP statistics from /proc/net/arp. + | +Linux + | +
| bcache + | +Exposes bcache statistics from /sys/fs/bcache/. + | +Linux + | +
| bonding + | +Exposes the number of configured and active slaves of Linux bonding interfaces. + | +Linux + | +
| boottime + | +Exposes system boot time derived from the kern.boottime sysctl. + | +Darwin, Dragonfly, FreeBSD, NetBSD, OpenBSD, Solaris + | +
| conntrack + | +Shows conntrack statistics (does nothing if no /proc/sys/net/netfilter/ present). + | +Linux + | +
| cpu + | +Exposes CPU statistics + | +Darwin, Dragonfly, FreeBSD, Linux, Solaris + | +
| cpufreq + | +Exposes CPU frequency statistics + | +Linux, Solaris + | +
| diskstats + | +Exposes disk I/O statistics. + | +Darwin, Linux, OpenBSD + | +
| edac + | +Exposes error detection and correction statistics. + | +Linux + | +
| entropy + | +Exposes available entropy. + | +Linux + | +
| exec + | +Exposes execution statistics. + | +Dragonfly, FreeBSD + | +
| filefd + | +Exposes file descriptor statistics from /proc/sys/fs/file-nr. + | +Linux + | +
| filesystem + | +Exposes filesystem statistics, such as disk space used. + | +Darwin, Dragonfly, FreeBSD, Linux, OpenBSD + | +
| hwmon + | +Expose hardware monitoring and sensor data from /sys/class/hwmon/. + | +Linux + | +
| infiniband + | +Exposes network statistics specific to InfiniBand and Intel OmniPath configurations. + | +Linux + | +
| ipvs + | +Exposes IPVS status from /proc/net/ip_vs and stats from /proc/net/ip_vs_stats. + | +Linux + | +
| loadavg + | +Exposes load average. + | +Darwin, Dragonfly, FreeBSD, Linux, NetBSD, OpenBSD, Solaris + | +
| mdadm + | +Exposes statistics about devices in /proc/mdstat (does nothing if no /proc/mdstat present). + | +Linux + | +
| meminfo + | +Exposes memory statistics. + | +Darwin, Dragonfly, FreeBSD, Linux, OpenBSD + | +
| netclass + | +Exposes network interface info from /sys/class/net/ + | +Linux + | +
| netdev + | +Exposes network interface statistics such as bytes transferred. + | +Darwin, Dragonfly, FreeBSD, Linux, OpenBSD + | +
| netstat + | +Exposes network statistics from /proc/net/netstat. This is the same information as netstat -s. + | +Linux + | +
| nfs + | +Exposes NFS client statistics from /proc/net/rpc/nfs. This is the same information as nfsstat -c. + | +Linux + | +
| nfsd + | +Exposes NFS kernel server statistics from /proc/net/rpc/nfsd. This is the same information as nfsstat -s. + | +Linux + | +
| pressure + | +Exposes pressure stall statistics from /proc/pressure/. + | +Linux (kernel 4.20+ and/or CONFIG_PSI) + | +
| rapl + | +Exposes various statistics from /sys/class/powercap. + | +Linux + | +
| schedstat + | +Exposes task scheduler statistics from /proc/schedstat. + | +Linux + | +
| sockstat + | +Exposes various statistics from /proc/net/sockstat. + | +Linux + | +
| softnet + | +Exposes statistics from /proc/net/softnet_stat. + | +Linux + | +
| stat + | +Exposes various statistics from /proc/stat. This includes boot time, forks and interrupts. + | +Linux + | +
| textfile + | +Exposes statistics read from local disk. The --collector.textfile.directory flag must be set. + | +any + | +
| thermal_zone + | +Exposes thermal zone & cooling device statistics from /sys/class/thermal. + | +Linux + | +
| time + | +Exposes the current system time. + | +any + | +
| timex + | +Exposes selected adjtimex(2) system call stats. + | +Linux + | +
| uname + | +Exposes system information as provided by the uname system call. + | +Darwin, FreeBSD, Linux, OpenBSD + | +
| vmstat + | +Exposes statistics from /proc/vmstat. + | +Linux + | +
| xfs + | +Exposes XFS runtime statistics. + | +Linux (kernel 4.4+) + | +
| zfs + | +Exposes ZFS performance statistics. + | +Linux, Solaris + | +
| Metric name + | +Metric type + | +Labels/tags + | +Status + | +
| kube_configmap_info + | +Gauge + | +configmap=<configmap-name>
+ +namespace=<configmap-namespace> + |
+ STABLE + | +
| kube_configmap_created + | +Gauge + | +configmap=<configmap-name>
+ +namespace=<configmap-namespace> + |
+ STABLE + | +
| kube_configmap_metadata_resource_version + | +Gauge + | +configmap=<configmap-name>
+ +namespace=<configmap-namespace> + |
+ EXPERIMENTAL + | +
| Component + | +Alert + | +Description + | +
| CPU + | +High CPU usage + | +Warning at > 75% used
+ +Critical error at > 90% used + |
+
| Memory + | +High Memory usage + | +Warning at > 80% used
+ +Critical error at > 90% used + |
+
| Systemd + | +Individual + | +Error when unit not loaded/active + | +
| Overall systemd health + | +Error when systemd detects a failed service + | +|
| Filesystem + | +High disk space usage + | +Warning at > 80% used
+ +Critical error at > 90% used + |
+
| High inode usage + | +Warning at > 90% used
+ +Critical error at > 95% used + |
+ |
| System + | +Uptime + | +Warning node uptime < 5 mins + | +
| Kernel params + | +Error if param not set + | +|
| Etcd + | +Etcd instance health + | +Error when etcd master down > 5 mins + | +
| Etcd latency check + | +Warning when follower <-> leader latency > 500 ms
+ +Error when > 1 sec over period of 1 min + |
+ |
| Docker + | +Docker daemon health + | +Error when docker daemon is down + | +
| Kubernetes + | +Kubernetes node readiness + | +Error when the node is not ready + | +
%s
++