-
Notifications
You must be signed in to change notification settings - Fork 185
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Merge pull request #541 from Xianyu39/doc-pkm-article
Doc pkm article
- Loading branch information
Showing
3 changed files
with
211 additions
and
2 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,206 @@ | ||
| --- | ||
| uid: 20231130211547 | ||
| title: 基于文章与卡片的笔记法 | ||
| tags: [笔记组织方法] | ||
| description: | ||
| author: 西郊有密林 | ||
| type: other | ||
| draft: false | ||
| editable: false | ||
| modified: 20231202221615 | ||
| --- | ||
|
|
||
| # 基于文章与卡片的笔记法 | ||
|
|
||
| 双链是 Obsidian 最引以为傲的卖点,其一定程度上也塑造了我们做笔记与思考的方式。 | ||
|
|
||
| 双链把笔记织成了一张网络,彼此之间互相关联了起来。彼此层层叠叠又相互联系的笔记看起来就像一个个相互连接的神经元,最大程度上激发了人脑的联想能力,帮助人们发现话题之间的潜在联系。 | ||
|
|
||
|  | ||
|
|
||
| 不过真的那么美好吗? | ||
|
|
||
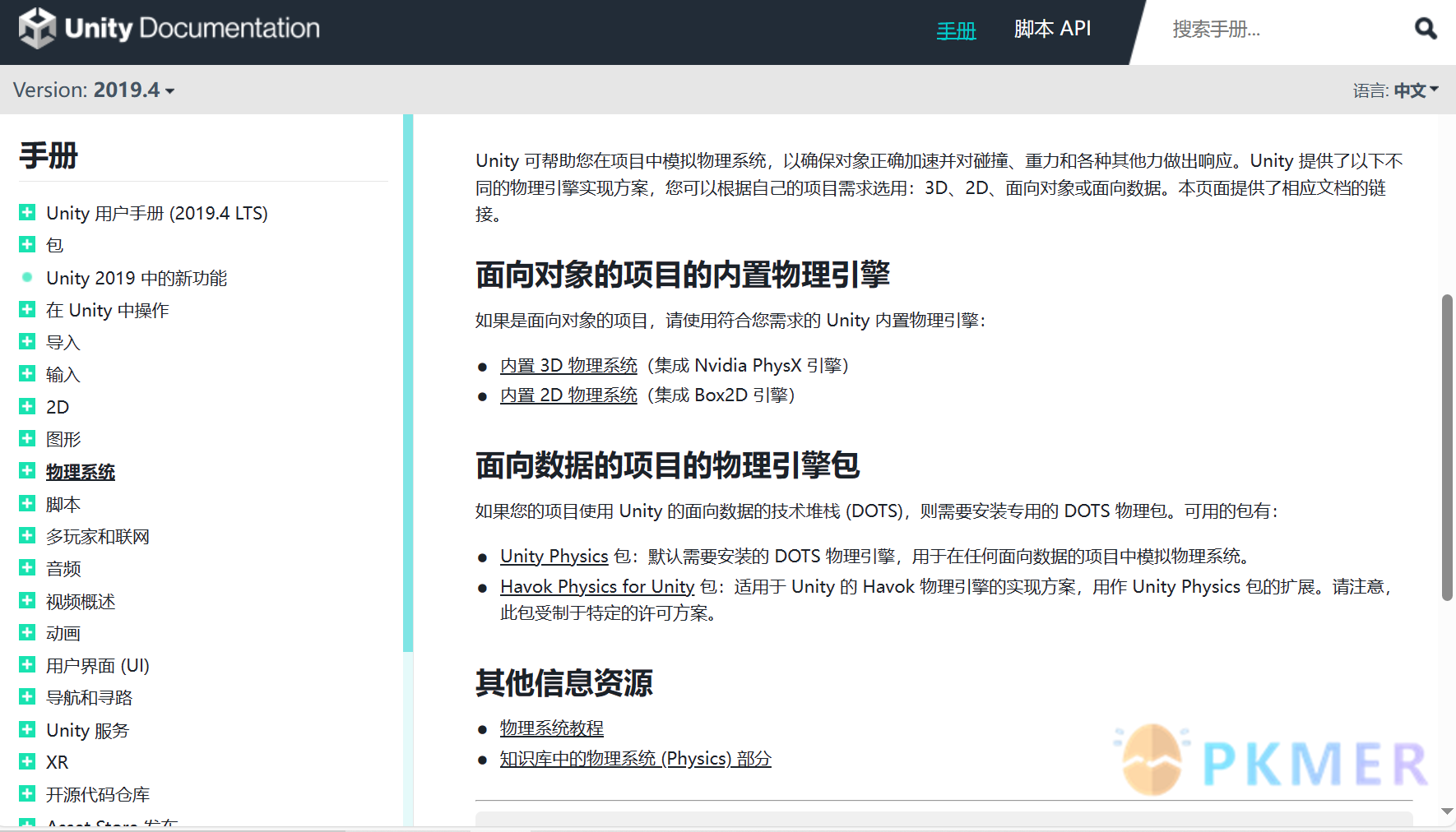
| 回忆一下,我最早接触这样的组织方法不是在 Obsidian,而应该是在 Unity 的文档网站上。 | ||
|
|
||
|  | ||
|
|
||
| Unity 的文档,或者说许多文档都采用了这种模式。就像这个介绍物理系统的页面,其本身只有简单介绍,文章剩余内容被按照章节拆解为了几个不同的页面用链接指引。当你点进其中一个链接,其中也是同样被分拆为若干个页面的文档。 | ||
|
|
||
| 如果这个文档有知识图谱的话,那也会是一张巨大的网。 | ||
|
|
||
| 这样的结构对于已经熟悉 Unity 、需要快速找到自己想要的那块内容的开发者来说也许有一些好处;但是对于不了解 Unity 的人来说,还是只能逐字逐句读下去,但是每个链接都是需要了解的内容,每个页面的内容都极少,阅读一千字可能需要跳转五六个链接,每跳转一次都会打断思维一次;而各个文章作为独立页面上下文完全不关联,如果想要回看之前读过的某个段落就需要记得从那篇文章到现在已经跳转了多少次,然后回退同样次数才能回去。 | ||
|
|
||
| 这样的文档几乎没有可读性。 | ||
|
|
||
| 当然,Unity 文档的作者大可说文档不是提供给初学者当教程的,需要教程可以移步他们的 Unity 课堂。但对于做笔记的人来讲,一份笔记总归是会有阅读需求的。可能是需要发布到平台,也可能是想打印分享给别人,亦或是自己很久没接触过的领域需要重新熟悉。通过双链把笔记库织成一张大网看起来似乎很美很科学,但对于阅读者来说,其只是一个找不到线头在哪的混乱线团。 | ||
|
|
||
| # 问题的根源 | ||
|
|
||
| 这个问题产生的原因是人类的脑不支持同时做好几件事。用计算机的术语来说,就是不支持并行。 | ||
|
|
||
| 因为不支持并行,所以不论你在文章组织上创新什么花样,也只能一个一个字往下阅读,读完一段看下一段。在这种情况下,不论多精巧的管理结构,在读者这里都被展开为了一个毫无美感的字符串,用树、图去组织笔记结果却起了反效果。 | ||
|
|
||
| 这就是为什么那么多年过去了,主流的书籍完成了从竹片变成纸质再变成数字的剧变,但其组织架构仍然是一个一个段落、一个一个章节往下,几乎没有什么改变。 | ||
|
|
||
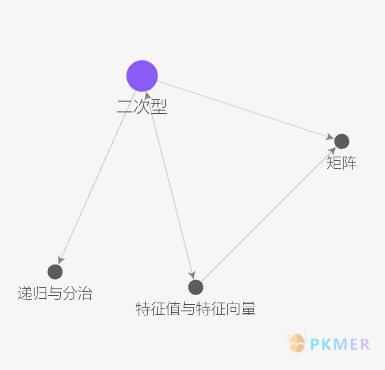
| 打个比方,我这里有一个关于二次型的局部知识图谱。A→B 意思是 A 内部包含了 B 的链接。 | ||
|
|
||
|  | ||
|
|
||
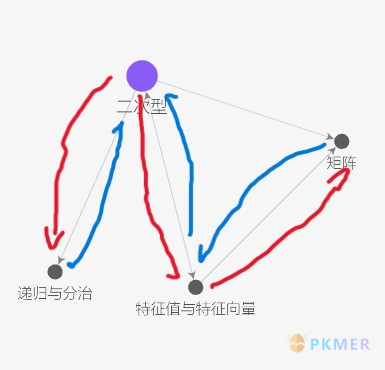
| 知识都组织起来了,好像很符合人脑擅长关联知识的特点。但是对于一个阅读者来说,因为每时每刻只能读一个文件,其阅读历程是这样的(红箭头代表跳转,蓝箭头代表回退): | ||
|
|
||
|  | ||
|
|
||
| 上面的阅读过程等同于读了一篇把 4 篇上下文联系不够多的文章拼接出来的一篇长文。这绝不会是读者想要的效果。 | ||
|
|
||
| 如果想要一定的阅读体验,就不能只有一个个互相链接、内容简短的「卡片」,而必须要有逻辑紧密、有一定篇幅的「文章」。 | ||
|
|
||
| # 卡片与文章 | ||
|
|
||
| 要解决这个问题需要恢复线性写作的传统,这样才能写出有可读性的文章;但是我们又想保留卡片笔记善于联想和查找概念的优势。所以我们可以把二者结合起来。 | ||
|
|
||
| 我把所有的文档分为两类 | ||
|
|
||
| 1. 知识卡片:只包含关于一件事物的内容,就像百度百科的某个词条,是比较简短的文档 | ||
| 2. 文章:许多内容组合起来的一篇长文,就像一本书,内部逻辑和上下文联系紧密。可以是一个文档,也可以是按章节分开的若干个文档 | ||
|
|
||
| 整个笔记库的内容组织要「以文章为树干,知识卡片为枝叶」的模式组织起来。 | ||
|
|
||
| 文章可以是你想写的一篇长文,也可以是你学习一本书的笔记,或者是课程笔记,应该说学习知识的主要就是通过写笔记文章实现的。文章里面会讲很多东西,提到非常多内容,但是考虑到文章需要分清内容的主次,主抓重点,所以不是所有内容都会详细论述;而对于那些非重点,或者本文不会重点讲解的基础概念,就插入一个链接给需要的读者。 | ||
|
|
||
| 知识卡片只详细讲述一个内容,可以是一个事物的介绍,也可以是两个事物之间的联系。 | ||
|
|
||
| 创作的流程是这样的 | ||
|
|
||
| 1. 学一门课或者看一本书的同时开始写一篇文章作为其笔记。这篇文章需要充分考虑读者的感受,要像写一本书一样规划内容 | ||
| 2. 遇见某些不是本文必须了解的概念(有探讨空间,或者不是本文重点但是也很有价值的知识)单独创建知识卡片,在卡片中详细探讨 | ||
| 3. 在文章中引用知识卡片,可以直接把链接附在文中提到这个词的文本上,也可以单独在文中写「更多关于 xxx 的信息可以参考 \[xxx\]\(xxx\) 」 | ||
|
|
||
| 通过这样的方法,读者就可以抓住文章这条主线不受打扰地往下阅读,只有在遇到不了解的单独概念时才需要阅读链接的卡片。在 Obsidian 中可以通过把光标放在链接文本上预览卡片内容,无需跳转到其他文档,避免了阅读进程被打断。 | ||
|
|
||
| 接下来我将举一个例子来演示这个思路,在例子之后再说明使用这个方法需要注意的原则。 | ||
|
|
||
| # 示例:贝叶斯决策论 | ||
|
|
||
| 这是机器学习笔记文章中的一个章节的节选部分。 | ||
|
|
||
| > [!EXAMPLE] | ||
| > # 贝叶斯决策论 | ||
| >有请我们的~~华强同志~~。 | ||
| > | ||
| > 华强希望有个东西帮他判断一个瓜是不是生瓜蛋子。现在我们用 $c_{1},c_{2}$ 两个标签分别代表生瓜或者熟瓜。现在他从瓜摊老板那里弄来了一组数据,可以支持我们搞统计。我们解决的思路为: | ||
| > 求每个瓜是生瓜的概率和不是生瓜的概率,选择概率大的作为我们的判断。 | ||
| > | ||
| > 建立两个随机变量: | ||
| > - C:标签(生瓜、熟瓜); | ||
| >- X:西瓜特征向量 | ||
| > | ||
| >一个瓜有 n 个特征,用一个特征向量 $x$ 表示,包含瓜的色泽、条纹等信息。 | ||
| > | ||
| > | ||
| > 我们的问题也就是求**瓜是 x 的时候,标签为 $c_{i}$ 的概率**,即 $P(C=c_{i}|X=x)$,选择概率最大的标签作为回答。但是这个概率不能直接统计得到,所 以使用 [[贝叶斯公式]]: | ||
| > | ||
| > $$ | ||
| > P(c_{i}|x)=\frac{P(x|c_{i})P(c_{i})}{P(x)} | ||
| > | ||
| > $$ | ||
| > | ||
| >$P(x)$ 在这里不影响各个标签比大小 (因为不管 i 是几大家都一样),问题变成了如何用数据集统计得到 $P(x|c_{i}),P(c_{i})$。其中,$P(c_{i})$ 可以直接从数据集里面统计得到一个比较靠谱的先验概率;但 $P (x|c_{i})$ 就不行,因为 x 属性很多,很多 x 可能数据集中根本没有出现。华强基本上不可能弄到大到能这样做的数据集。 | ||
| > | ||
| > # 最大似然估计 | ||
| > 要想办法得到 $P(x|c_{i})$,可以先假定其概率分布模型,然后做实验 估计出参数。这里用的是 [[最大似然估计]]。我们先引入一些假设: | ||
| > - 估计的参数是客观存在的确定值,我们只需要找到它(频率主义观点); | ||
| > - 样本相互独立且同分布; | ||
| >- 样本分布是**正态分布**。 | ||
| > | ||
| > | ||
| > 对于标签为 $c_{i}$ 的所有西瓜 $(x,c_{i})$,我们的似然函数就是: | ||
| > | ||
| > $$ | ||
| > L(\mu_{c},\sigma _{c})=\sum_{(x,c_{i})}\ln P(x|c_{i})=\sum_{(x,c_{i})}\ln\frac{1}{\sqrt{ 2\pi }\sigma _{c}}\exp\left( -\frac{x-\mu_{c}^{2}}{2\sigma^{2}_{c}} \right) | ||
| > | ||
| > $$ | ||
| > | ||
| >这里对似然函数取了对数来提高精度。本来现在要开始优化,但是因为假设是正态分布,所以直接使用结论就好了。 | ||
| > | ||
| > 显然,后两条假设如果被推翻那我们的分类器就没啥意义了。 | ||
| > # 朴素贝叶斯分类 | ||
| > 最大似然估计需要假定概率分布模型,这一步很不好做。为了改善这点,加一个假设: | ||
| >- x(西瓜)的各个属性之间对分类的影响相互独立。 | ||
| > | ||
| > | ||
| > 因此 $P(x|c_{i})=\prod_{x_{j}\in x}P(x_{j}|c_{i})$,代入原公式: | ||
| > | ||
| > $$ | ||
| > P(c_i|x)=\frac{P(c_i)}{P(x)}\prod_{x_{j}\in x}P(x_{j}|c_{i}) | ||
| > | ||
| > $$ | ||
| > | ||
| > 通过数据集直接做统计,可以很方便统计出 $P(c_i),P(x_j|c_i)$,就不需要做其他模型类型上面的假设,也就不需要做最大似然估计了。 | ||
| > | ||
| > $$ | ||
| > P(c_{i})=\frac{标签为c_{i} 的样本数量+1}{数据集中样本总数+标签总数} | ||
| > | ||
| > $$ | ||
| > | ||
| > $$ | ||
| > P(x_{j}|c_{i})=\frac{标签为c_{i} 且第j个属性为x_{j} 的样本数量+1}{标签为c_{i} 的样本数量+第j个属性可能的取值数量} | ||
| > | ||
| > $$ | ||
| > | ||
| > 这两个公式加入了拉普拉斯修正,没有直接统计频率,避免了因为数据集不够大导致分子为 0 的情况。 | ||
| 这个例子和 Unity 的文档一样,都使用了链接。但是最重要的区别在于,本文的链接像是在一篇普通文章中挑选了一些词附加了链接,链接的内容并不是文章的必要组成部分。 | ||
|
|
||
| 对于了解了链接所提概念的读者,可以直接忽略其存在;而需要阅读的读者也不必跳转,只需要预览画面即可。 | ||
|
|
||
| 就这样,多次跳转就被避免了。 | ||
|
|
||
|  | ||
|
|
||
| # 原则 | ||
|
|
||
| 首先,**绝对不允许像 Unity 文档那样把一篇完整文章拆解成若干文件然后要求读者跳转阅读**。也许你会觉得这样的笔记不够原子化,不方便今后复用或者引用。对于这个问题我推荐使用**标题级别的块链接**,这样文章中每个小标题也可以被看作一个知识卡片,在无需拆解文章的前提下完成了复用。 | ||
|
|
||
| Obsidian 中可以通过 `[[##]]` 搜索库中所有标题级别的块并且生成块链接。 | ||
|
|
||
| 其次,知识卡片也要和文章一样保持完整性,不允许拆解。这是因为我们需要使用预览窗口来避免跳转。如果知识卡片内部也还需要跳转那就会形成多层嵌套,影响阅读体验。 | ||
|
|
||
| 除了阅读之外,文章也需要维护更新。当学习到新的零散的知识,建立知识卡片的同时需要思考其是不是可以完善之前的文章的某个部分。如果积累了许多关于同一方面的知识卡片,也可以考虑把它们组织为一篇逻辑体系严密的文章,这样你就完成了从积累到创造的转变,这会为你提供想不到的收益。 | ||
|
|
||
| 最后,我们还可以搬出最古典的文件树法来存放文章。用一个文件夹存放属于同一个课程或者同一本书的所有笔记,并且按照字典序排列。而知识卡片则可以用 tag 来管理,用 dataview 来统计。比如我用一整个文件夹存放了图形学课一共 22 节课的所有课程笔记;而课程笔记中提到的一些非必读概念,比如 Box-Muller 随机数生成算法,则做成知识卡片统一存放,用 tag 标记管理。 | ||
|
|
||
|  | ||
|
|
||
| # 评价 | ||
|
|
||
| 总而言之,**我们必须在维护好行文连贯性的基础上去写作**,这样才能顺应人的线性思维特点,增强可读性,避免整个笔记库成为一团乱麻。这对于需要分享库的人,尤其是那些想要用库打造个人网站的用户非常重要。 | ||
|
|
||
| 此外,这样的模式也适合于想要在平台发布文章的选手。按照这种方法可以很方便地把一系列长文变成平台的连载文章,只需要在发布前修改一下外链部分,看看是不是需要作一定解释或者修改措辞。这个操作可以很容易用 Obsidian 做到,只需要打开文件的「出链」面板就可以定位、修改本文包含的全部外链。 | ||
|
|
||
|  | ||
|
|
||
| 针对这种枝干分明的架构,我给它起个可能欠妥的名字,叫做「知识藤蔓」。 | ||
|
|
||
| # 藤蔓比喻 | ||
|
|
||
| 根本上来讲,这是在管理知识卡片。 | ||
|
|
||
| 文章充当了瓜藤,是主线;知识卡片是附着在瓜藤上的叶片。之所以这样说是取「顺藤摸瓜」的意思。当你跟随主线一直走,摸到了瓜藤的末端,就可以收获到果实。 | ||
|
|
||
| 这个理念很大程度上参考了游戏任务设计的特点。策划常把任务分为主线、支线,玩家主要跟着主线前进,而支线为可选项。这样就丰富游戏内容同时也让玩家有迹可循,不至于摸不着头脑。典型的例子比如元气骑士。 | ||
|
|
||
| - 全流程分为若干个关卡,顺序排布,一关一关往下 | ||
| - 每个关卡有若干个房间,这些房间可以丰富游戏体验,但并不是所有房间都是必须进去的。这些房间都称之为支线 | ||
|  | ||
|
|
||
| 如果坚持记录的习惯时间足够长,笔记库可能会有若干条这样的「藤蔓」,每一条都代表着你在一个领域的躬耕的经历。这些不同领域的知识绝不会是皮毛的,而会是有始有终的。出教程一样的写作态度会倒逼你对学习的概念进行深刻的理解,否则就会难以下笔。这样的做法也可以保证你抓住一点「费曼学习法」的精髓。 | ||
|
|
||
| # 后话 | ||
|
|
||
| 最后的环节我想再问一次那个很经典的问题:人的正确认识从哪里来? | ||
|
|
||
| 比较官方的回答会说:「正确的认识从实践中来」。这很对,但是每个人实践的范围总是相对来说不那么容易改变的。我们马上能做的,还是从既有的实践中尽量发掘出可用的规律。而这光靠思考是办不到的,重要的还是在辩论中不断澄清已有的理念,通过两方攻守互换不断升级双方的认识。 | ||
|
|
||
| 但是这种机会不是那么常有的,所以很多时候往往需要我们一个人同时扮演这两个角色。就像一个和自己下棋的棋手。而上文中所谓的用出书的态度去写作,就是一种自己和自己辩论的方式。相比其他形式,其付出巨大精力是必然的,因为同时承担了作者、读者两个角色,需要不断站到作者对立的读者那一边去尽量质疑和批评,回过来又需要处理这些麻烦。 | ||
|
|
||
| 这些观点的正确性也许还需要后续的讨论和论证,不过我想其肯定可以作为一种组织思路,为有这类需求的朋友们提供一点灵感。 |