-
Notifications
You must be signed in to change notification settings - Fork 16
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
fffb5c7
commit 2aa62f3
Showing
61 changed files
with
6,777 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,198 @@ | ||
| <div align="center"> | ||
| <h1> Grad-SVC based Grad-TTS from HUAWEI Noah's Ark Lab </h1> | ||
|
|
||
| This project is named as Grad-SVC, or GVC for short. Its core technology is diffusion, but so different from other diffusion based SVC models. Codes are adapted from Grad-TTS and so-vits-svc-5.0. So the features from so-vits-svc-5.0 will be used in this project. | ||
|
|
||
| The project will be completed in the coming months ~~~ | ||
| </div> | ||
|
|
||
| ## Setup Environment | ||
| 1. Install project dependencies | ||
|
|
||
| ```shell | ||
| pip install -r requirements.txt | ||
| ``` | ||
|
|
||
| 2. Download the Timbre Encoder: [Speaker-Encoder by @mueller91](https://drive.google.com/drive/folders/15oeBYf6Qn1edONkVLXe82MzdIi3O_9m3), put `best_model.pth.tar` into `speaker_pretrain/`. | ||
|
|
||
| 3. Download [hubert_soft model](https://github.com/bshall/hubert/releases/tag/v0.1),put `hubert-soft-0d54a1f4.pt` into `hubert_pretrain/`. | ||
|
|
||
| 4. Download pretrained [nsf_bigvgan_pretrain_32K.pth](https://github.com/PlayVoice/NSF-BigVGAN/releases/augment), and put it into `bigvgan_pretrain/`. | ||
|
|
||
| 5. Download pretrain model [gvc.pretrain.pth](), and put it into `grad_pretrain/`. | ||
| ```shell | ||
| python gvc_inference.py --config configs/base.yaml --model ./grad_pretrain/gvc.pretrain.pth --spk ./configs/singers/singer0001.npy --wave test.wav | ||
| ``` | ||
|
|
||
| ## Dataset preparation | ||
| Put the dataset into the `data_raw` directory following the structure below. | ||
| ``` | ||
| data_raw | ||
| ├───speaker0 | ||
| │ ├───000001.wav | ||
| │ ├───... | ||
| │ └───000xxx.wav | ||
| └───speaker1 | ||
| ├───000001.wav | ||
| ├───... | ||
| └───000xxx.wav | ||
| ``` | ||
| ## Data preprocessing | ||
| After preprocessing you will get an output with following structure. | ||
| ``` | ||
| data_gvc/ | ||
| └── waves-16k | ||
| │ └── speaker0 | ||
| │ │ ├── 000001.wav | ||
| │ │ └── 000xxx.wav | ||
| │ └── speaker1 | ||
| │ ├── 000001.wav | ||
| │ └── 000xxx.wav | ||
| └── waves-32k | ||
| │ └── speaker0 | ||
| │ │ ├── 000001.wav | ||
| │ │ └── 000xxx.wav | ||
| │ └── speaker1 | ||
| │ ├── 000001.wav | ||
| │ └── 000xxx.wav | ||
| └── mel | ||
| │ └── speaker0 | ||
| │ │ ├── 000001.mel.pt | ||
| │ │ └── 000xxx.mel.pt | ||
| │ └── speaker1 | ||
| │ ├── 000001.mel.pt | ||
| │ └── 000xxx.mel.pt | ||
| └── pitch | ||
| │ └── speaker0 | ||
| │ │ ├── 000001.pit.npy | ||
| │ │ └── 000xxx.pit.npy | ||
| │ └── speaker1 | ||
| │ ├── 000001.pit.npy | ||
| │ └── 000xxx.pit.npy | ||
| └── hubert | ||
| │ └── speaker0 | ||
| │ │ ├── 000001.vec.npy | ||
| │ │ └── 000xxx.vec.npy | ||
| │ └── speaker1 | ||
| │ ├── 000001.vec.npy | ||
| │ └── 000xxx.vec.npy | ||
| └── speaker | ||
| │ └── speaker0 | ||
| │ │ ├── 000001.spk.npy | ||
| │ │ └── 000xxx.spk.npy | ||
| │ └── speaker1 | ||
| │ ├── 000001.spk.npy | ||
| │ └── 000xxx.spk.npy | ||
| └── singer | ||
| ├── speaker0.spk.npy | ||
| └── speaker1.spk.npy | ||
| ``` | ||
| 1. Re-sampling | ||
| - Generate audio with a sampling rate of 16000Hz in `./data_gvc/waves-16k` | ||
| ``` | ||
| python prepare/preprocess_a.py -w ./data_raw -o ./data_gvc/waves-16k -s 16000 | ||
| ``` | ||
| - Generate audio with a sampling rate of 32000Hz in `./data_gvc/waves-32k` | ||
| ``` | ||
| python prepare/preprocess_a.py -w ./data_raw -o ./data_gvc/waves-32k -s 32000 | ||
| ``` | ||
| 2. Use 16K audio to extract pitch | ||
| ``` | ||
| python prepare/preprocess_f0.py -w data_gvc/waves-16k/ -p data_gvc/pitch | ||
| ``` | ||
| 3. use 32k audio to extract mel | ||
| ``` | ||
| python prepare/preprocess_spec.py -w data_gvc/waves-32k/ -s data_gvc/mel | ||
| ``` | ||
| 4. Use 16K audio to extract hubert | ||
| ``` | ||
| python prepare/preprocess_hubert.py -w data_gvc/waves-16k/ -v data_gvc/hubert | ||
| ``` | ||
| 5. Use 16k audio to extract timbre code | ||
| ``` | ||
| python prepare/preprocess_speaker.py data_gvc/waves-16k/ data_gvc/speaker | ||
| ``` | ||
| 6. Extract the average value of the timbre code for inference | ||
| ``` | ||
| python prepare/preprocess_speaker_ave.py data_gvc/speaker/ data_gvc/singer | ||
| ``` | ||
| 8. Use 32k audio to generate training index | ||
| ``` | ||
| python prepare/preprocess_train.py | ||
| ``` | ||
| 9. Training file debugging | ||
| ``` | ||
| python prepare/preprocess_zzz.py | ||
| ``` | ||
| ## Train | ||
| 1. Start training | ||
| ``` | ||
| python gvc_trainer.py | ||
| ``` | ||
| 2. Resume training | ||
| ``` | ||
| python gvc_trainer.py -p logs/grad_svc/grad_svc_***.pth | ||
| ``` | ||
| 3. Log visualization | ||
| ``` | ||
| tensorboard --logdir logs/ | ||
| ``` | ||
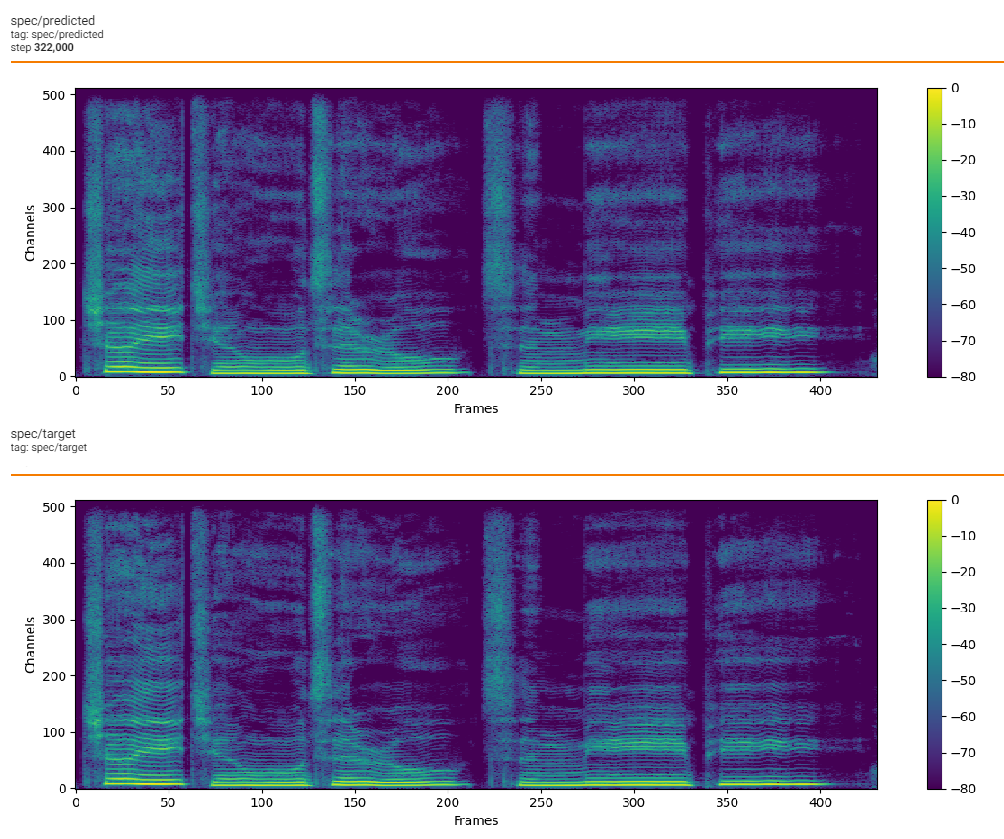
| ## Loss | ||
|  | ||
|  | ||
| ## Inference | ||
| 1. Export inference model | ||
| ``` | ||
| python gvc_export.py --checkpoint_path logs/grad_svc/grad_svc_***.pt | ||
| ``` | ||
| 2. Inference | ||
| - if there is no need to adjust `f0`, just run the following command. | ||
| ``` | ||
| python gvc_inference.py --model gvc.pth --spk ./data_gvc/singer/your_singer.spk.npy --wave test.wav --shift 0 | ||
| ``` | ||
| - if `f0` will be adjusted manually, follow the steps: | ||
| 1. use hubert to extract content vector | ||
| ``` | ||
| python hubert/inference.py -w test.wav -v test.vec.npy | ||
| ``` | ||
| 2. extract the F0 parameter to the csv text format | ||
| ``` | ||
| python pitch/inference.py -w test.wav -p test.csv | ||
| ``` | ||
| 3. final inference | ||
| ``` | ||
| python gvc_inference.py --model gvc.pth --spk ./data_gvc/singer/your_singer.spk.npy --wave test.wav --vec test.vec.npy --pit test.csv --shift 0 | ||
| ``` | ||
| 3. Convert mel to wave | ||
| ``` | ||
| python gvc_inference_wave.py --mel gvc_out.mel.pt --pit gvc_tmp.pit.csv | ||
| ``` | ||
| ## Code sources and references | ||
| https://github.com/huawei-noah/Speech-Backbones/blob/main/Grad-TTS | ||
| https://github.com/facebookresearch/speech-resynthesis [paper](https://arxiv.org/abs/2104.00355) | ||
| https://github.com/jaywalnut310/vits [paper](https://arxiv.org/abs/2106.06103) | ||
| https://github.com/NVIDIA/BigVGAN [paper](https://arxiv.org/abs/2206.04658) | ||
| https://github.com/mindslab-ai/univnet [paper](https://arxiv.org/abs/2106.07889) | ||
| https://github.com/mozilla/TTS | ||
| https://github.com/bshall/soft-vc | ||
| https://github.com/maxrmorrison/torchcrepe |
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,21 @@ | ||
| MIT License | ||
|
|
||
| Copyright (c) 2022 PlayVoice | ||
|
|
||
| Permission is hereby granted, free of charge, to any person obtaining a copy | ||
| of this software and associated documentation files (the "Software"), to deal | ||
| in the Software without restriction, including without limitation the rights | ||
| to use, copy, modify, merge, publish, distribute, sublicense, and/or sell | ||
| copies of the Software, and to permit persons to whom the Software is | ||
| furnished to do so, subject to the following conditions: | ||
|
|
||
| The above copyright notice and this permission notice shall be included in all | ||
| copies or substantial portions of the Software. | ||
|
|
||
| THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR | ||
| IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, | ||
| FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE | ||
| AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER | ||
| LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, | ||
| OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE | ||
| SOFTWARE. |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,138 @@ | ||
| <div align="center"> | ||
| <h1> Neural Source-Filter BigVGAN </h1> | ||
| Just For Fun | ||
| </div> | ||
|
|
||
|  | ||
|
|
||
| ## Dataset preparation | ||
|
|
||
| Put the dataset into the data_raw directory according to the following file structure | ||
| ```shell | ||
| data_raw | ||
| ├───speaker0 | ||
| │ ├───000001.wav | ||
| │ ├───... | ||
| │ └───000xxx.wav | ||
| └───speaker1 | ||
| ├───000001.wav | ||
| ├───... | ||
| └───000xxx.wav | ||
| ``` | ||
|
|
||
| ## Install dependencies | ||
|
|
||
| - 1 software dependency | ||
|
|
||
| > pip install -r requirements.txt | ||
| - 2 download [release](https://github.com/PlayVoice/NSF-BigVGAN/releases/tag/debug) model, and test | ||
|
|
||
| > python nsf_bigvgan_inference.py --config configs/nsf_bigvgan.yaml --model nsf_bigvgan_g.pth --wave test.wav | ||
| ## Data preprocessing | ||
|
|
||
| - 1, re-sampling: 32kHz | ||
|
|
||
| > python prepare/preprocess_a.py -w ./data_raw -o ./data_bigvgan/waves-32k | ||
| - 3, extract pitch | ||
|
|
||
| > python prepare/preprocess_f0.py -w data_bigvgan/waves-32k/ -p data_bigvgan/pitch | ||
| - 4, extract mel: [100, length] | ||
|
|
||
| > python prepare/preprocess_spec.py -w data_bigvgan/waves-32k/ -s data_bigvgan/mel | ||
| - 5, generate training index | ||
|
|
||
| > python prepare/preprocess_train.py | ||
| ```shell | ||
| data_bigvgan/ | ||
| │ | ||
| └── waves-32k | ||
| │ └── speaker0 | ||
| │ │ ├── 000001.wav | ||
| │ │ └── 000xxx.wav | ||
| │ └── speaker1 | ||
| │ ├── 000001.wav | ||
| │ └── 000xxx.wav | ||
| └── pitch | ||
| │ └── speaker0 | ||
| │ │ ├── 000001.pit.npy | ||
| │ │ └── 000xxx.pit.npy | ||
| │ └── speaker1 | ||
| │ ├── 000001.pit.npy | ||
| │ └── 000xxx.pit.npy | ||
| └── mel | ||
| └── speaker0 | ||
| │ ├── 000001.mel.pt | ||
| │ └── 000xxx.mel.pt | ||
| └── speaker1 | ||
| ├── 000001.mel.pt | ||
| └── 000xxx.mel.pt | ||
|
|
||
| ``` | ||
|
|
||
| ## Train | ||
|
|
||
| - 1, start training | ||
|
|
||
| > python nsf_bigvgan_trainer.py -c configs/nsf_bigvgan.yaml -n nsf_bigvgan | ||
| - 2, resume training | ||
|
|
||
| > python nsf_bigvgan_trainer.py -c configs/nsf_bigvgan.yaml -n nsf_bigvgan -p chkpt/nsf_bigvgan/***.pth | ||
| - 3, view log | ||
|
|
||
| > tensorboard --logdir logs/ | ||
|
|
||
| ## Inference | ||
|
|
||
| - 1, export inference model | ||
|
|
||
| > python nsf_bigvgan_export.py --config configs/maxgan.yaml --checkpoint_path chkpt/nsf_bigvgan/***.pt | ||
| - 2, extract mel | ||
|
|
||
| > python spec/inference.py -w test.wav -m test.mel.pt | ||
| - 3, extract F0 | ||
|
|
||
| > python pitch/inference.py -w test.wav -p test.csv | ||
| - 4, infer | ||
|
|
||
| > python nsf_bigvgan_inference.py --config configs/nsf_bigvgan.yaml --model nsf_bigvgan_g.pth --wave test.wav | ||
| or | ||
|
|
||
| > python nsf_bigvgan_inference.py --config configs/nsf_bigvgan.yaml --model nsf_bigvgan_g.pth --mel test.mel.pt --pit test.csv | ||
| ## Augmentation of mel | ||
| For the over smooth output of acoustic model, we use gaussian blur for mel when train vocoder | ||
| ``` | ||
| # gaussian blur | ||
| model_b = get_gaussian_kernel(kernel_size=5, sigma=2, channels=1).to(device) | ||
| # mel blur | ||
| mel_b = mel[:, None, :, :] | ||
| mel_b = model_b(mel_b) | ||
| mel_b = torch.squeeze(mel_b, 1) | ||
| mel_r = torch.rand(1).to(device) * 0.5 | ||
| mel_b = (1 - mel_r) * mel_b + mel_r * mel | ||
| # generator | ||
| optim_g.zero_grad() | ||
| fake_audio = model_g(mel_b, pit) | ||
| ``` | ||
| 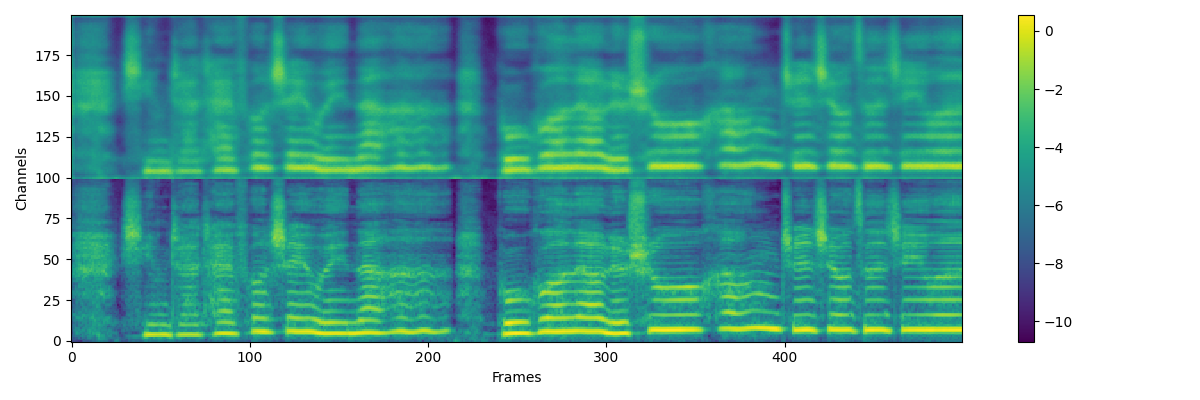 | ||
|
|
||
| ## Source of code and References | ||
|
|
||
| https://github.com/nii-yamagishilab/project-NN-Pytorch-scripts/tree/master/project/01-nsf | ||
|
|
||
| https://github.com/mindslab-ai/univnet [[paper]](https://arxiv.org/abs/2106.07889) | ||
|
|
||
| https://github.com/NVIDIA/BigVGAN [[paper]](https://arxiv.org/abs/2206.04658) |
Oops, something went wrong.