-
Notifications
You must be signed in to change notification settings - Fork 744
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
9469fd7
commit 07c3023
Showing
1 changed file
with
260 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,260 @@ | ||
| { | ||
| "nbformat": 4, | ||
| "nbformat_minor": 0, | ||
| "metadata": { | ||
| "colab": { | ||
| "name": "Splitting_the_dataset_into_three_sets.ipynb", | ||
| "provenance": [], | ||
| "collapsed_sections": [], | ||
| "authorship_tag": "ABX9TyMzSplJ67qx8DafnGw4Iolb", | ||
| "include_colab_link": true | ||
| }, | ||
| "kernelspec": { | ||
| "name": "python3", | ||
| "display_name": "Python 3" | ||
| } | ||
| }, | ||
| "cells": [ | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": { | ||
| "id": "view-in-github", | ||
| "colab_type": "text" | ||
| }, | ||
| "source": [ | ||
| "<a href=\"https://colab.research.google.com/github/Tanu-N-Prabhu/Python/blob/master/Splitting_the_dataset_into_three_sets.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": { | ||
| "id": "sh0fLKZpdIp9", | ||
| "colab_type": "text" | ||
| }, | ||
| "source": [ | ||
| "# **Splitting the dataset into three sets**\n", | ||
| "\n", | ||
| "## **In this article, we will understand the necessity of splitting the data set.**\n", | ||
| "\n", | ||
| "\n", | ||
| "\n" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": { | ||
| "id": "zX_9DNXsdRJe", | ||
| "colab_type": "text" | ||
| }, | ||
| "source": [ | ||
| "# **Introduction**\n", | ||
| "\n", | ||
| "In this article, we will mainly focus on **why** do we need to split the dataset into three sets. If so, **how** do we do it?. All these days you have been blindly splitting the data into two sets. Let me guess the name of the sets:\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "1. **Training set**\n", | ||
| "2. **Testing set**\n", | ||
| "\n", | ||
| "You would have used the **training set data** to only **train or build your machine learning model or algorithm**. Similarly, the **testing set** to **evaluate or assess the performance of your model**.\n", | ||
| "\n", | ||
| "Splitting the data into two sets is not wrong. But don't you think you are putting too much burden on the testing set. Because in your case you will use the testing set to:\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "1. **Evaluate the model**\n", | ||
| "2. **Fine-tune the parameters (tuning) or choosing the best parameters**\n", | ||
| "3. **Assess the model performance**\n", | ||
| "\n", | ||
| "Sometimes putting too much load on a donkey ain't gonna work out. Rather invest in a new donkey and put some load on it. This makes your life easy. So your next thought would be what's the splitting ratio. Well, the answer lies in the next section.\n", | ||
| "\n", | ||
| "---\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "\n", | ||
| "\n" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": { | ||
| "id": "eMogI0b7eJ2d", | ||
| "colab_type": "text" | ||
| }, | ||
| "source": [ | ||
| "# **Three sets**\n", | ||
| "\n", | ||
| "Yes, you read it right its \"**Three sets**\". In practice, data analysts work with three distinct sets namely:\n", | ||
| "\n", | ||
| "\n", | ||
| "1. Training set\n", | ||
| "2. Testing set\n", | ||
| "3. Validation set\n", | ||
| "\n", | ||
| "\n", | ||
| "Let me explain this with the help of a made-up diagram (block diagram). Consider you have a \"**Car Dataset**\" which mainly comprises the features of the car such as model, brand, year, horsepower along with the price. Now your job is to **predict the price** of the car **given the features**. For example, if someone gives you all the features of the car you should take that information then do some magic (apply machine learning algorithms) and then tell them the price of that particular car.\n", | ||
| "\n", | ||
| "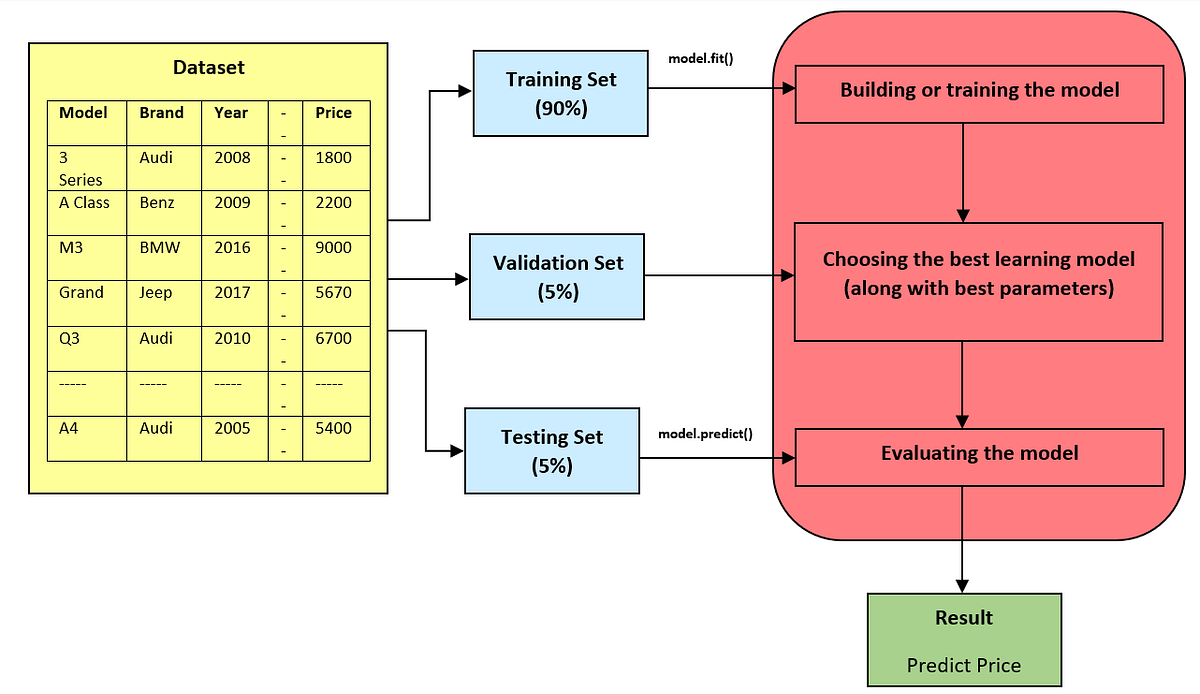\n", | ||
| "\n", | ||
| "\n", | ||
| "Now you need to split the dataset into three sets as shown above. Below are some of the important guidelines:\n", | ||
| "\n", | ||
| "1. First, you need to **shuffle** the samples. You can use `random_state = 42`. This will just shuffle the samples if the value is **0**, then the samples will not be shuffled.\n", | ||
| "\n", | ||
| "2. Split the data sets into **Training, Validation, and Testing sets**. Usually, the training set should be the **biggest one in terms of sample size**. The validation and the testing set also know as the **holdout sets** must be roughly of the **same size**. In general, the holdout sets must be smaller than the size of the training set.\n", | ||
| "\n", | ||
| "---\n", | ||
| "\n" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": { | ||
| "id": "k_k5yEsne5z9", | ||
| "colab_type": "text" | ||
| }, | ||
| "source": [ | ||
| "## **Why the name holdout sets?**\n", | ||
| "\n", | ||
| "\n", | ||
| "This is because the learning algorithm cannot use the samples or examples from these two subsets to build or train the model. Meaning for training the model you need to only use the training set samples.\n", | ||
| "\n", | ||
| "---" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": { | ||
| "id": "b8ZIrJMbfBVJ", | ||
| "colab_type": "text" | ||
| }, | ||
| "source": [ | ||
| "## **What's the exact proportion of splitting?**\n", | ||
| "\n", | ||
| "\n", | ||
| "There is no exact number for the splitting. If you are dealing with the big data sets you have over **500, 000 samples** or more, then in your case you use **95%** of the samples for training, **2.5%** for the validation, and the last **2.5%** for testing. However, if you don't have many samples, then you can split the dataset as **70+15+15**.\n", | ||
| "\n", | ||
| "---" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": { | ||
| "id": "Ix7PojxTfPZ0", | ||
| "colab_type": "text" | ||
| }, | ||
| "source": [ | ||
| "## **What is the main reason behind the three sets?**\n", | ||
| "\n", | ||
| "\n", | ||
| "One of the main purposes is that when we build or train the model there is no point in predicting the samples that the model has already seen. In this case, the model tries to memorize all the samples and makes no mistakes in predicting the samples. So no matter any machine learning algorithm you apply on predicting the training samples, the **accuracy will be higher** (over **95%**). Such algorithms will be useless in practice. Therefore, we want a model that is good at predicting the samples that the model has never seen before. This is what we need in the real world. This is why we need three sets and not one.\n", | ||
| "\n", | ||
| "---\n" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": { | ||
| "id": "k95UcAjIfYA1", | ||
| "colab_type": "text" | ||
| }, | ||
| "source": [ | ||
| "## **What is the purpose of the hold-out sets?**\n", | ||
| "\n", | ||
| "\n", | ||
| "Remember to follow these three thumb rules throughout your data science journey. From today please use:\n", | ||
| "\n", | ||
| "1. Training set to only **train** the model.\n", | ||
| "2. Validation set to **choose the learning algorithm** and **choose or find the best hyperparameter**.\n", | ||
| "3. Testing set to **assess or evaluate** the model before putting it into production.\n", | ||
| "\n", | ||
| "---" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": { | ||
| "id": "Sp_2mlz2fr0a", | ||
| "colab_type": "text" | ||
| }, | ||
| "source": [ | ||
| "## **How to split the data set into three sets?**\n", | ||
| "\n", | ||
| "\n", | ||
| "Well, there are quite a lot of solutions on the internet. My two favorite ones are:\n", | ||
| "\n", | ||
| "**Using the numpy library to split the data into three sets:**\n", | ||
| "\n", | ||
| "The below-given code will split the data into **60% of training**, **20% of the samples into validation**, and the rest **20% into the testing set**. Thanks to the [split method](https://docs.scipy.org/doc/numpy/reference/generated/numpy.split.html)." | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "code", | ||
| "metadata": { | ||
| "id": "ojx4SWbNf-N0", | ||
| "colab_type": "code", | ||
| "colab": {} | ||
| }, | ||
| "source": [ | ||
| "train, validate, test = np.split(df.sample(frac=1), [int(.6*len(df)), int(.8*len(df))]" | ||
| ], | ||
| "execution_count": 0, | ||
| "outputs": [] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": { | ||
| "id": "1yHJ_lFNf-4Z", | ||
| "colab_type": "text" | ||
| }, | ||
| "source": [ | ||
| "**Using the sklearn train test split method to split the data into three sets:**\n", | ||
| "\n", | ||
| "\n", | ||
| "We can use the `sklearn.model_selection.train_test_split` twice to split the data set into three sets. First to split to train, test, and then split train again into validation and train. Thanks to the [sklearn library](http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html). In this case, the split will be **80+10+10**.\n" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "code", | ||
| "metadata": { | ||
| "id": "dnT8b-YAgHyN", | ||
| "colab_type": "code", | ||
| "colab": {} | ||
| }, | ||
| "source": [ | ||
| "X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=1)\n", | ||
| "\n", | ||
| "X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.15, random_state=1) # 0.25 x 0.8 = 0.2" | ||
| ], | ||
| "execution_count": 0, | ||
| "outputs": [] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": { | ||
| "id": "xFHcqT33gSwX", | ||
| "colab_type": "text" | ||
| }, | ||
| "source": [ | ||
| "\n", | ||
| "\n", | ||
| "---\n", | ||
| "\n" | ||
| ] | ||
| }, | ||
| { | ||
| "cell_type": "markdown", | ||
| "metadata": { | ||
| "id": "ukgX7yrTgTnG", | ||
| "colab_type": "text" | ||
| }, | ||
| "source": [ | ||
| "That's it for today, you guys have reached the end of the article. I hope you guys learned something new today. I used the [textbook](http://themlbook.com/) named \"**[The Hundred-Page Machine Learning Book by Andriy Burkov](http://themlbook.com/)**\" as a reference (Chapter 5) to write this tutorial. You can have a look at it. If you guys have any doubts regarding this tutorial, you can use the comment section down below. I will try to answer it as soon as possible. Until then, Stay Safe, Good Bye.\n", | ||
| "\n", | ||
| "---" | ||
| ] | ||
| } | ||
| ] | ||
| } |