D:SWARM Use Case at SLUB Dresden
At SLUB Dresden, the Streaming variant of d:swarm is used for normalising data retrieved from various sources before feeding it into to a Solr search index. Clients such as the new SLUB Katalog (beta) can request data from Solr and present it to library users.

The following data sources are currently processed with d:swarm at SLUB Dresden:
-
deutsche FOTOTHEK
- OAI-PMH XML (containing records that make use of terms from the DC Elements and Europeana vocabulary)
- Ebook Library, E-Book packages from Wiley, deGruyter (EBL, WILEY, DEG)
- OAI-PMH + MARCXML
-
Gemeinsamer Bibliotheksverbund (GBV)
- MARCXML
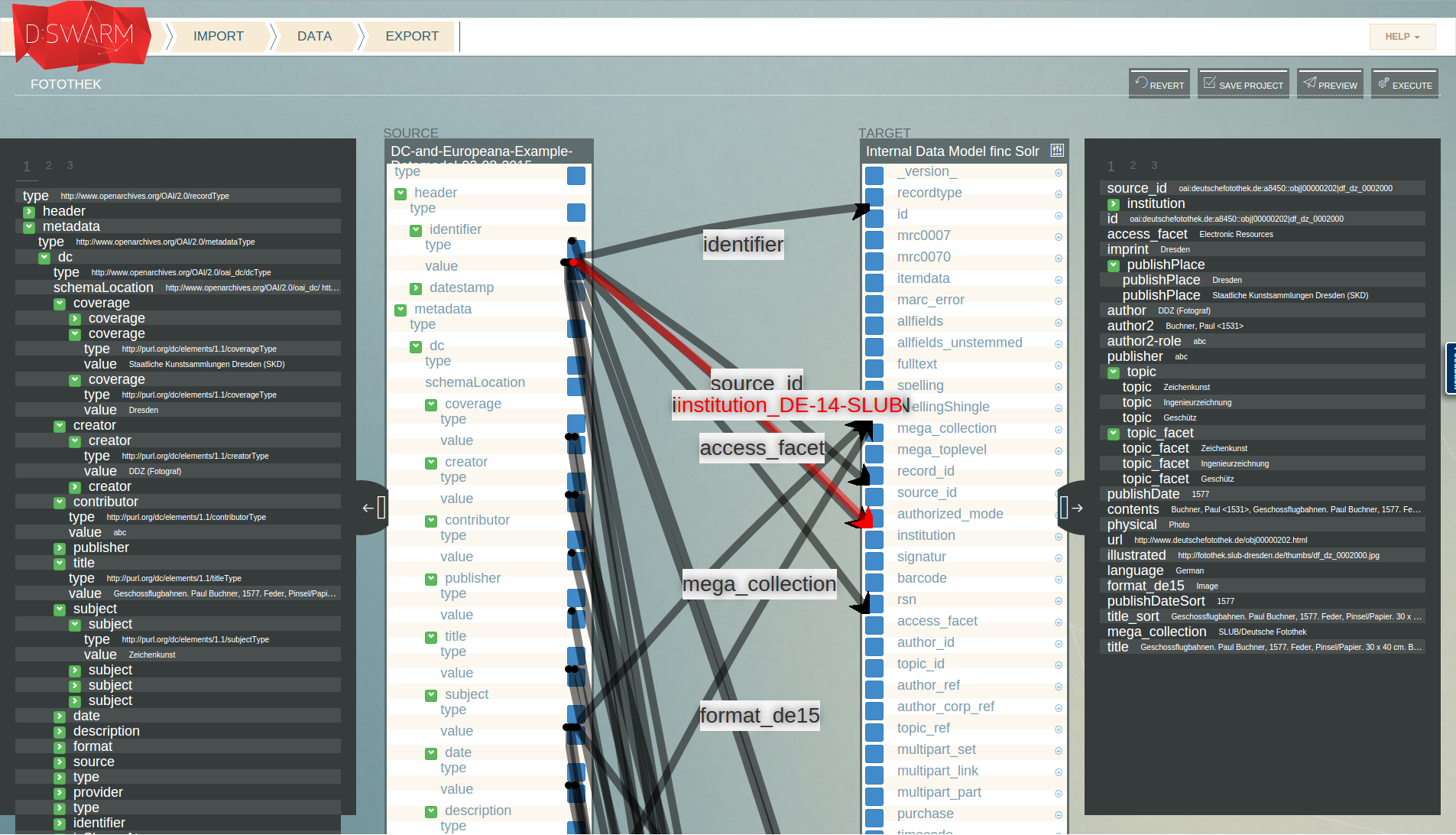
The target schema we map to, is a schema that is utilised in the Finc Solr search index. We export the transformation result of our mapped data as XML (to be able) to import it into the Solr search index (where it will be merged with data from other sources). Below, you find an example of a source data (OAI-PMH + DC Elements and Europeana) on the left and the export data (Finc Solr schema compliant XML) on the right hand side.

For each source, we defined one or multiple mapping projects, all mapping to the same target schema (the Finc Solr schema). In case a source requires specific mappings, we set up a dedicated project for this source and combined the mappings during the task execution. For example, for processing of the GBV data, we use the general OAI-PMH + MARCXML mappings and source specific ones that are located in a separate project ("GBV extra"). A preview of the transformation result that was generated by the mappings in our project for data from the "deutsche FOTOTHEK" is shown below (data widget at right hand side).
We use the Task Processing Unit for d:swarm (TPU) to process larger amounts of data, separated by data source. For each source, a TPU configuration has been written (see, e.g., here), which states
- where the source data folder is located,
- which mappings from which projects are to employ,
- which processing mode is to use and, finally,
- where to store the exported data.
We utilised the following configuration of the TPU (here an example for "deutsche FOTOTHEK") that results in a streaming behavior, i.e., directly exporting it as XML (some properties not shown for clarity, utilise the full example at the TPU documentation to get an overview of all possible configuration parameters):
service.name=fotothek-on-the-fly
resource.watchfolder=/data/source-data/productive/fotothek
configuration.name=/home/dmp/config/xml-configuration.json
prototype.projectID=a6c53e2f-6b59-87b7-ca78-08f96cb6c6a7
prototype.outputDataModelID=5fddf2c5-916b-49dc-a07d-af04020c17f7
...
init.multiple_data_models=true
transform.do=true
task.do_ingest_on_the_fly=true
results.persistInDMP=false
task.do_export_on_the_fly=true
...
results.folder=/data/target-data/productive/fotothek
engine.threads=8
engine.dswarm.api=http://localhost/dmp/
...
Processing Ebook Library data sources for example takes about 580 seconds for 255.365 records (containing 9.683.470 statements at total) on a 8-cores, 64 GB RAM Linux (Ubuntu 12.04, 64-Bit) machine using 32GB RAM for the TPU and 24GB RAM for the d:swarm backend. Further hardware facts:
- HD with SSD cache (but no SSD disk), 500GB, extra partition for all data and logs
- up to 4,5 GHz used
- up to 70% of the total RAM used