Connect4 bay-beeeeee
Hello! I built Connect4 robots with python, and this notebook is here to help me explain it
There are three main files: Connect4.py, GamePlay.py, and Robots.py
#python class that creates the Connect 4 game structure/environment
from GamePlay import GamePlay
#python class to hold the robots that can play Connect4
from Robots import Robots
#python class that allows you to play the game
from Connect4 import Connect4
game=Connect4()
#play with our without graphics!
#game.play_Graphics()
#game.play_Graphics()gameplay=GamePlay()We can grab the current connect4 board:
board=gameplay.BOARD
print(board)[[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]]
Interact with the environment by taking actions for a player:
print('Before:')
print(board)
player=1 #add a piece for player 1
spot=0 #add a piece in the first column
print('')
print('Add a piece for player {} in spot {}'.format(player,spot))
gameplay.Add_Piece(player,spot,board)
print('')
print('After:')
print(board)Before:
[[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]]
Add a piece for player 1 in spot 0
After:
[[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0.]]
We can also check the status of the game
gameplay.reset()
board=gameplay.BOARD
print('Add two pieces for player 2 in the third column:')
gameplay.Add_Piece(2,3,board)
gameplay.Add_Piece(2,3,board)
print('')
print('Board:')
for row in board:
print(row)
status=gameplay.Check_Goal(board)
print('Status:',status)
print('-------------------------------')
print('Add another four pieces for player 1 in the same column:')
gameplay.Add_Piece(1,3,board)
gameplay.Add_Piece(1,3,board)
gameplay.Add_Piece(1,3,board)
gameplay.Add_Piece(1,3,board)
#update status after adding more pieces
status=gameplay.Check_Goal(board)
print('')
print('Board:')
for row in board:
print(row)
print('Status:',status)
print('notice how the status has changed for player 1 winning (getting 4 in a row)')Add two pieces for player 2 in the third column:
Board:
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 2. 0. 0. 0.]
[0. 0. 0. 2. 0. 0. 0.]
Status: Keep Playing!
-------------------------------
Add another four pieces for player 1 in the same column:
Board:
[0. 0. 0. 1. 0. 0. 0.]
[0. 0. 0. 1. 0. 0. 0.]
[0. 0. 0. 1. 0. 0. 0.]
[0. 0. 0. 1. 0. 0. 0.]
[0. 0. 0. 2. 0. 0. 0.]
[0. 0. 0. 2. 0. 0. 0.]
Status: Player 1 wins!
notice how the status has changed for player 1 winning (getting 4 in a row)
There is also the capability to get the current score of the board for a given player.
The score is calculated based on the windows of size 4 there are on the board. It is the sum of how much all of the board's windows are filled up for that player.
gameplay.reset()
board=gameplay.BOARD
gameplay.Add_Piece(1,0,board)
print(board)
print('Score:',gameplay.Get_Score(1,board))[[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0.]]
Score: 0.75
There are three possible windows with pieces in them where player 1 can get a connect 4
Player 1 could win by getting 4 pieces:
- along the bottom row of the board (window 1),
- in the first column (window 2), or
- in a diagonal (window 3).
All three of these windows are 25% filled, Making the score for player 1 equal to .75 (.25 + .25 + .25)
If player 2 decided to put a piece in any of these windows, then that window will no longer be an option for player 1 to win in.
Notice how the score changes from .75 to .5 if player 2 puts a piece in the first column, as it now makes it impossible for player 1 to complete window 2.
gameplay.Add_Piece(2,0,board)
print(board)
print('Score:',gameplay.Get_Score(1,board))[[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[2. 0. 0. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0.]]
Score: 0.5

bots=Robots()-
FmoveBot:
- Does the first move available to them
-
Rando:
- Takes random actions given a board
-
Minimax:
- Evaluates the board (or state) and does the minimax algorithm to pick it's next move
-
AlphaBeta:
- Does the minimax algorithm with alphabeta pruning
-
DNN:
- Deep Neural Network, trained using Q learning (reinforcement learning).
print('FmoveBot and Rando are pretty straight forward...')
print('')
print('Starting board:')
gameplay.reset()
board=gameplay.BOARD
for row in board:
print(row)
print('')
print('After two moves from the first move bot:')
player=1
action = bots.ROBOT(player,'FmoveBot',board)
gameplay.Add_Piece(player,action,board)
player=2
action = bots.ROBOT(player,'FmoveBot',board)
gameplay.Add_Piece(player,action,board)
for row in board:
print(row)
print('')
print('After two moves from the random bot:')
player=1
action = bots.ROBOT(player,'Rando',board)
gameplay.Add_Piece(player,action,board)
player=2
action = bots.ROBOT(player,'Rando',board)
gameplay.Add_Piece(player,action,board)
for row in board:
print(row)FmoveBot and Rando are pretty straight forward...
Starting board:
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
After two moves from the first move bot:
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[2. 0. 0. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0.]
After two moves from the random bot:
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[2. 0. 0. 0. 0. 0. 0.]
[1. 0. 0. 1. 0. 2. 0.]
The minimax Algorithm for two player games:
Player 1's objective is to maximize their total score, while player 2 wants to minimize it. The algorithm takes a game's current state and expands all of the other possible states for each possible action. This expansion is done again for all of these new possible states for player 2. This expansion process is repeated for a fixed number of times.
Starting from the bottom state and working up, the algorithm choses the direction that maximizes the total score if it is player 1's turn, and minimizes the total score if to is player 2's turn
https://www.baeldung.com/wp-content/uploads/2017/07/minimax.png
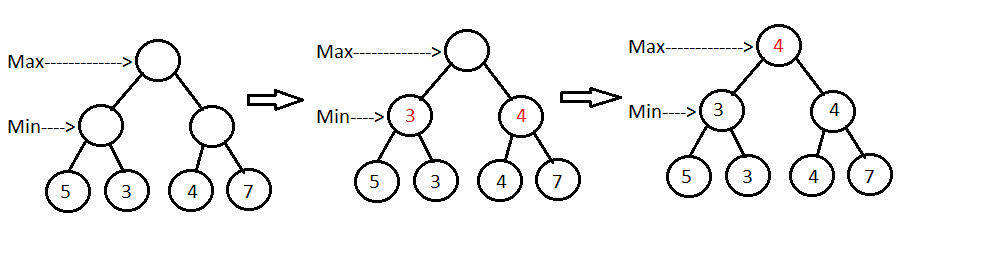{kind=link}

If we were to look 5 steps ahead, how many states will we be expanding?
7 to the 5th power
7*7*7*7*716807
gameplay.reset()
board=gameplay.BOARD
gameplay.Add_Piece(1,3,board)
gameplay.Add_Piece(2,3,board)
gameplay.Add_Piece(1,2,board)
for row in board:
print(row)
print('')
for i in range(5):
d=i+1
bots=Robots(depth=d)
%timeit bots.ROBOT(2,'MiniMax',board)
print('For depth ',d,' the best action is:',bots.ROBOT(2,'MiniMax',board))
print('')[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 2. 0. 0. 0.]
[0. 0. 1. 1. 0. 0. 0.]
27.3 ms ± 2.07 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
For depth 1 the best action is: 3
218 ms ± 18.4 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
For depth 2 the best action is: 3
1.67 s ± 195 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
For depth 3 the best action is: 2
9.44 s ± 500 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
For depth 4 the best action is: 1
1min ± 2.26 s per loop (mean ± std. dev. of 7 runs, 1 loop each)
For depth 5 the best action is: 4
gameplay.reset()
board=gameplay.BOARD
gameplay.Add_Piece(1,3,board)
gameplay.Add_Piece(2,3,board)
gameplay.Add_Piece(1,2,board)
print('')
for row in board:
print(row)
for i in range(5):
d=i+1
bots=Robots(depth=d)
%timeit bots.ROBOT(2,'AlphaBeta',board)
print('For depth ',d,' the best action is:',bots.ROBOT(2,'AlphaBeta',board))
print('')[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 2. 0. 0. 0.]
[0. 0. 1. 1. 0. 0. 0.]
28.3 ms ± 2.24 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
For depth 1 the best action is: 3
154 ms ± 7.68 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
For depth 2 the best action is: 3
829 ms ± 47.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
For depth 3 the best action is: 2
3.28 s ± 322 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
For depth 4 the best action is: 1
8.78 s ± 446 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
For depth 5 the best action is: 4
In Artificial Intelegence, an agent is some entity that interacts with an environment.
Reinforcement learning is about having an AI agent learn what best actions to take by interacting with the environment over and over again, and receiving some reward.



#function that takes two robots, plays a bunch of games, and records their number of respective wins
def play_games(bot1,bot2,games,d=3,name='mymodel.h5'):
gameplay=GamePlay()
bots=Robots(depth=d)
bots.load_model(name)
p1wins, p2wins, gamenum=0,0,1
while gamenum<=games:
status=gameplay.Check_Goal(gameplay.BOARD)
#player 1:
if status=='Keep Playing!':
action=bots.ROBOT(1,bot1,gameplay.BOARD)
gameplay.Add_Piece(1,action,gameplay.BOARD)
status=gameplay.Check_Goal(gameplay.BOARD)
#player 2
if status=='Keep Playing!':
action=bots.ROBOT(2,bot2,gameplay.BOARD)
gameplay.Add_Piece(2,action,gameplay.BOARD)
status=gameplay.Check_Goal(gameplay.BOARD)
if status!='Keep Playing!':
if status=='Player 1 wins!':
p1wins=p1wins+1
if status=='Player 2 wins!':
p2wins=p2wins+1
gamenum=gamenum+1
gameplay.reset()
return p1wins,p2wins #bots:
# MiniMax, AplphaBeta, Rando, FmoveBot, DNN
DEPTH=1
g=100
p1wins,p2wins=play_games('AlphaBeta','Rando',g,d=DEPTH)
print('Precentage player1 wins:',round(p1wins/g,2))Precentage player1 wins: 0.99
#bots:
# MiniMax, AplphaBeta, Rando, FmoveBot, DNN
g=100
p1wins,p2wins=play_games('DNN','Rando',g)
print(p1wins,p2wins)
print('Precentage player1 wins:',round(p1wins/g,2))79 21
Precentage player1 wins: 0.79
DEPTH=1
g=10
p1wins,p2wins=play_games('DNN','AlphaBeta',g,d=DEPTH)
print('Precentage player1 wins:',round(p1wins/g,2))Precentage player1 wins: 0.0